












记得刚接触宫崎骏老爷子的作品是在高中时代,然而当时正值青春年少外加深受灌篮高手等动画“荼毒”,对宫老爷子的《千与千寻》、《龙猫》、《魔女宅急便》、《天空之城》之流也就完全不感冒了。再次接触宫老爷子的动画则是在大学期间,记得当时熬了N个通宵把全集都过了好几遍,不得不感慨作品只有在相应的情景下才能释放价值。从这个观点上看,近日网上流传的“宫老爷子还能再战十年!”也并不为过。
NTV电视台于2013年8月2日晚第14次重播了《天空之城》,当剧情发展到男女主角巴鲁和希达共同念出毁灭之咒“Blase”时,一举将tweet发送峰值带到了每秒143199次,这个峰值高于2013日本新年33388次/秒,也高于拉登之死(5106次/秒)、东日本大地震(5530次/秒)、美国流行天后碧昂斯宣布怀孕(8868次/秒)。
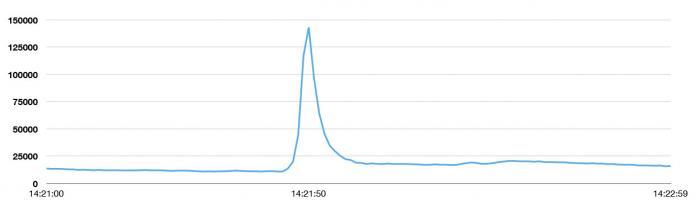
毁灭之咒“Blase”摧毁了天空之城,同样也摧毁了经过充分准备的2ch,然而却铸就了当下Twitter的***峰值。新的峰值是平均值(5700TPS)的25倍,当下用户平均每天发送的tweet是500万条左右。在峰值期间,Twitter一直保持着高可用性,对比3年前世界杯上的表现无疑有着天壤之别。近日Twitter在技术博客上公布了为什么会重铸Twitter以及新系统打造的相关细节,以下为译文:
重铸Twitter决心
当2010年人们将Twitter作为世界杯体验实时分享工具时,每一脚射门、每一次罚球、以及裁判出示的每一张红牌或黄牌产生的tweet都会对系统造成不同程度的影响,同时也会造成程序短时间内的不可用。2010世界杯期间,工程师日以继夜的工作,拼命的改善系统性能。不幸的是,这样的努力瞬间被Twitter的快速增长淹没。
有过这次经历,我们清楚了只有重新架构才能匹配网站的增长,同时让系统变得更加可靠。随后我们就开启了漫漫的重构之路,而当下Twitter已经可以从容应对类似《天空之城》重播、超级碗以及全球新年夜庆典这样的事件,新的架构不仅能弹性的应对负载,还可以帮助工程团队快速发布新特性,包括了跨设备的消息同步,Twitter cards可以让服务变得更加的丰富并拥有更多的内容,同样还带来了囊括用户和故事的搜索体验。为了实现这些,我们甚至改变了工程组织,下面就来一睹服务打造细节:
三年磨剑铸辉煌
重新架构
在2010世界杯尘埃落定后,我们审视了整个系统,并发现众多需要从根本上改善的地方:
1. Twitter曾运行着世界上***的RoR堆栈,并将这个技术推到了一个绝对高度:那个时候,大约200个工程师在为之奋斗,它确实让Twitter渡过了一个用户爆发性时期,不管是新用户的增加,还是负载增加的处理。这个系统一度支撑了所有运作,从管理数据库、memcache连接到网站的渲染及公共API的呈现,这些全部包含在一个代码库里。它不仅让工程师的整合变的困难,同样也困扰了工程团队的管理及并行作业。
2. 存储系统的吞吐量达到了极限——之前Twitter使用的是纯粹的MySQL存储系统,进行分片,同时系统只有一个主节点。然而从系统展示的速度上来看,tweet的吞吐率确实出现了问题。这样我们就必须重建一个新的数据库以应对增长率,因为热门数据的读取已越来越频繁。
3. 取代从工程方面彻底的解决问题,我们曾尝试过投入更多主机;然而随后就发现,前端Rbuy主机并不能处理预期(根据性能)的事务量——从以往的经验看,这些主机完全可以胜任更多的事务。
4. ***,从软件角度上看,我们发现我们一直在钻优化这个牛角尖,我们开始在性能和效率与代码库的可读性和灵活性之间做权衡。
综上所述,系统的重新架构已迫在眉睫,我们给自己定下了3个目标和挑战:
1. 我们希望打造出兼具性能、效率及灵活性的大型基础设施——我们希望能改善Twitter上的平均延时,同样我们希望通过离群值给Twitter带来统一的体验。我们希望将赖以运行的服务器降到十分之一。我们希望对故障进行隔离以避免大规模宕机——随着服务器规模的日益增大,这点就尤为重要,因为集群的变大意味着主机故障将愈来愈频繁。故障是不可避免的,所以我们希望它们发生在一个更容易控制的模式下。
2. 我们希望通过将相关的代码放到一起,以获得更清晰的边缘——我们已经感受了整片代码所带来的困扰,所以我们打造一个松耦合、基于服务的架构。我们目标是封装和模块化的***实践,当然是在系统级,而不是类、模块或者是包一级。
3. 最重要的是,我们希望能更快的发布特性。我们希望团队能并行的运作,每一个小组都可以在不依赖其它小组的情况下独立的完成局部决策,并将特性发布给用户。
我们POC了新的架构,虽然不是所有的努力最终都能符合上述目标,但是最起码做到了一部分并且解决了工具问题,当然,还得到了比现下更令人满意及可靠的基础设施。#p#
JVM与Ruby Vm
首先我们从CPU、RAM及网络三个角度评估了前端服务器层,我们发现基于Ruby的架构明显受限于CPU和内存,然而单机器的请求并没有达到,网络带宽同样也没有接近饱和。在那个时候,我们的Rails服务器只能服务单线程,同样,每次也只能处理一个请求。每个Rails主机都运行了一定数量的Unicom进程,用以提供主机级的并发性,但是重叠率浪费了太多的资源。归结起来,Rails服务器每台主机每秒只能处理200到300个请求。
然而Twitter使用率的增长却并未放缓,这样一来我们就必须投入海量的主机才能匹配用户的增长曲线。
在那段时间,Twitter已经拥有部属超大规模基于JVM服务的经验——Twitter的搜索引擎就是使用Java编写,而Streaming API基础设施以及社交图系统Flock都是使用Scala编写,同时我们也迷恋JVM带来的性能,如果选用Ruby VM的话,那么性能、灵活性以及效率都很难符合我们的目标,所以我们开始编写可以运行在JVM上的代码。我们预计重写代码库可以让我们获得10倍的性能提升,而今天我们每台服务器每秒已经可以处理1到2万的请求。
对JVM的信任还基于公司中有很多工程师有着丰富的JVM经验,我们有信心将Twitter带入JVM后可以得到本质上的提升。这样下面需要做的就是拆分架构,并弄清楚不同服务之间的交互方式。
程序设计模型
在Twitter的Ruby系统中,并发控制被放在进程级——单网络请求通过进程排队。这个进程会一直占用资源,直到请求结束。这样将同时增加复杂性及架构难度,Twitter需要完成基于服务的转变。同时因为Ruby进程使用单线程模式,后端系统延时将直接影响到响应时间。在Ruby中有很多选择来增加并发性,然而JVM中却并没有一个标准选择。JVM拥有着支持并发的设计和基元,让我们可以建立一个真正的并发程序设计平台。
这样,就需要一个独立且统一的方式去思考并发性,特别是网络的思考。众所周知,编写并发代码(以及并发的网络代码)是非常困难的,并且需要使用多种方式。事实上,这方面我们早就有所体会。然而在系统被分解成不同服务的初期,团队并未使用统一的途径;比如从客户端到服务的failure semantics就不能很好交互:我们并没有一致的back-pressure机制让服务器给客户端返回信号,因此出现了客户端疯狂重试服务引起的惊群效应。这个经历让我们明白统一、互补的客户端及服务器库的重要性,它可以在多个方面起到作用:连接池、故障转移策略以及负载平衡,将我们连成一体,我们把Futures和Finagle拉到了一起。
现在不仅有了统一的方式,同样合并了系统所需核心库;如此我们就可以取得更快的进展,而不用过多关注每个系统的操作方式,从而把精力放到应用程序和服务接口上。
独立系统
Twitter的***改变就是从一个整体的Ruby应用程序转变为基于服务的架构,我们首先聚焦建立tweet、timeline及用户服务——这也是Twitter的“核心名词”。这种转变让我们可以更清晰的抽象出边缘、团队级所有权和独立性。在Twitter王国,不仅需要理解整个代码库的专家,还有需要模块以及类级别的所有者。越来越大的代码库让全局理解变得不可能,然而在实际工作中,只有模块和类级别的所有者根本不能解决问题。我们的代码库变得很难被维护,而团队不停的去挖掘历史代码以便清楚某一功能。大规模错误发生时,搞清楚状况就像组织去远海狩猎鲸鱼;到了***,我们在纠错上花费的时间要远大于新特性的发布,这是任何人都不愿看到的情况。
我们追求的永远都是允许并行设计的面向服务架构,我们赞同网络RPC接口,然后独立的开发系统内部构件,然而这同样意味着每个服务的逻辑都必须在内部实现。如果我们需要对tweet相关部分做改变,那么只需要在一个位置做出更改(Tweet 服务),这种变化就可以贯穿整个操作系统。然而在实际操作中,发现并不能完全实现这个目标,比如:一个Tweet服务中的改变可能会需要其他服务做出相应的改变。虽然没有做到完全独立,但是大部分的情况下还是可以的。
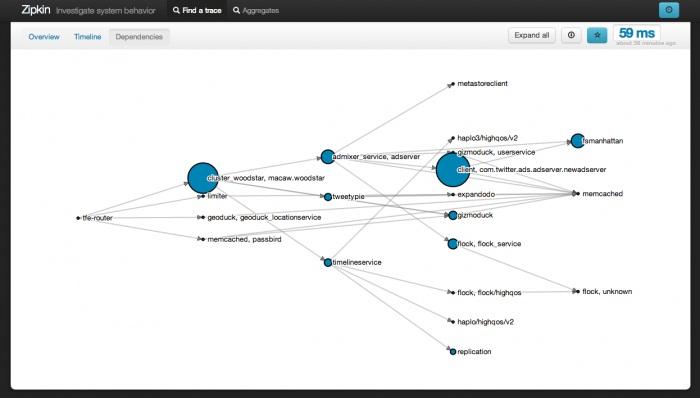
这个系统架构就是我们一直期待的,每个团队都可以独立和快速的运转。这就意味着团队可以调用后端系统对所属服务进行操作,非常有益大型应用程序运营。#p#
储存
即使应用程序被切分成服务,存储上仍然存在非常大的瓶颈。这时的Twitter使用的还是一个主MySQL数据库,为此我们采取了临时策略——将每条tweet都储存为数据库中的一行并进行顺序存储,当数据库容量耗尽时会建立一个新的数据库,并在应用中进行配置。这个策略为我们争取到了一定的时间,但是峰值时的tweet吞吐量瓶颈依然存在,因为他们总是被顺序的存储到一个单独的数据库主节点中,所以读负载只被分担到一小部分的数据库主机中。因此,我们需要为Tweet的存储选择一个不同的分片策略。
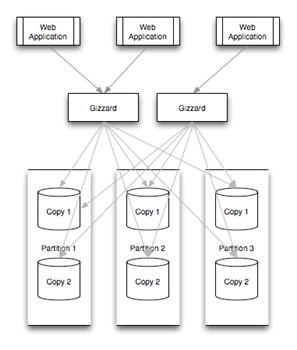
我们开发了Gizzard,帮助我们建立分片及容错的分布式数据库,用它来服务tweet。我们还建立了T-Bird。这种情况下,Gizzard需要处理大量的MySQL数据库——当tweet被传入系统时,Gizzard会首先得到它,然后选择一个合适的数据库。当然,这就意味丧失了MySQL的唯一ID生成能力。Snowflake被开发用以解决这个问题,它可以帮助建立tweet的ID。一旦有了标识符,就可以依靠Gizzard进行存储。如果哈希算法非常有效,并且tweet接近均匀分布,那么就可以通过增加目标数据库的数量来提高吞吐量。读取同样均匀的分布在整个集群上,而不是被绑在“最近”的数据库上,这同样是高吞吐量的保障。
可观察及统计
虽然已经对整体应用程序进行更健壮的封装,但是依然存在很多复杂性。为了管理如此规模的应用程序,工具也是个煞费苦心的领域。鉴于新服务的发布速度,快速收集每个服务运行数据的能力是必不可少的。一般情况下,我们希望做数据驱动策略,所以必须无缝获得尽可能详细的数据。
鉴于我们需要在一个不断变大的系统上建立越来越多的服务,我们必须让这个操作变得非常简单。为此,Runtime Systems团队为工程师建立了两个工具:Viz和Zipkin。这两个工具都对Finagle可见并与之整合,这样所有使用Finagle建立的系统都可以自动通信。
|
1
2
3
|
stats.timeFuture("request_latency_ms") {// dispatch to do work} |
如上显示,一个服务通过短短的3行代码就可以给Viz报告统计信息。这样一来,任何人使用Viz都可以查询自己感兴趣的数据,比如request_latency_ms中第55和99百分位数据。
运行时配置和测试
***,当我们实现以上所有步骤时,却遭遇了两个看似无关紧要的障碍:发布特性必须在不同的服务之间做一系列协调,而Twitter的规模之也导致服务阶段测试能力的丧失。依赖部署去开启用户层代码已不再可行,取而代之的是必须在整个应用程序上做协调;此外,考虑到Twitter的相对体积,在整个隔离环境下进行有意义的测试变得非常困难。相对而言,我们并没有在隔离系统中进行测试——我们使用了运行时配置来应对。
我们在服务中整合了被称为Decider的系统,它允在服务中改变发生时,以近实时的方式将这个改变扩散到整个系统。这意味着一旦准备就绪,软件和多个系统就可以投入使用。然而一个特性不应该是“神出鬼没”的,Decider同样允许我们灵活的去做基于二进制或者百分位的转换,比如让某个特性只针对百分之多少的传输或者用户生效。我们可以将代码配置成完全“off”或者是安全设置,然后逐渐的将它打开或者关闭,直到可以确信它正常工作并且系统可以支撑新的负载。这样做可以降低队伍之间协调的工作量,取而代之的是我们在运行时进行设置。
Twitter系统的现状
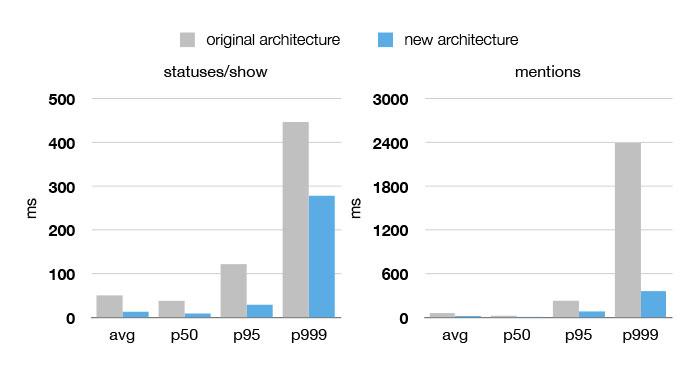
比之3年前,当下Twitter系统的性能、有效性和可靠性都得到了显著提高,从下图不难看到,在集群使用率在50%到99.9%的情况下,网站的性能都得到了大幅度的提升,然而机器的数量却减少了5至12倍。过去6个月,服务的可用性更达到了4个9(99.99%)。
模仿软件堆栈去设置工程团队,让团队长期获得一个服务的所有权,有助于这部分基础设施专家的形成。团队有着自己的接口及问题域,举个例子:不是所有的团队都需要去关心tweet的扩展问题,只有涉及tweet子系统(tweet服务团队、储存团队、缓存团队等)运行的团队必须去扩展tweet的写入和读出,其它的团队只需要懂得使用现成的API就可以了。














