众所周知,Mozilla涉足手机操作系统领域,推出Firefox OS,这都不是什么新鲜事了。Firefox OS是纯粹用Web技术打造的,其核心内容就是HTML,CSS,当然还有***的Javascript。Firefox OS上所有的应用程序都是基于上述技术的,甚至包括那些核心应用也不例外。
鉴于FireFox OS完全由Javascript打造,Mozilla的Javascript引擎(SpiderMonkey)不能回避的一个话题,就是与其他手机设备平 台的开发语言相互比较。为了详细地研究这个问题,我花了大约两周的时间做了一个小小的性能测试实验。
实验:
我们的实验以SunSpider benchmark测试为基础,我把部分程序从Javascript代码同时转换成了Java和C++代码,并尽力忠实于Javascript代码本身的 逻辑。接着,我将Java版本的程序编译成Android Dalvik应用,然后用emscripte工具把C++版本的程序生成为asm.js代码。
然后,我在Nexus 4设备上做了如下测试:
1、Dalvik应用程序,直接在Android运行
2、Asm.js代码(从C++编译而来),运行在Mobile Firefox Nightly上
3、本地代码(从C++编译而来),直接在Android上运行(编译指令为:ndk-build V=1 TARGET_ARCH_ABI=armeabi-v7a)
我使用运行时间的倒数作为评判指标(分数越高的话就越好),并且把结果进行了等比例缩放,以保证Dalvik至少能得到1分(哈哈,好恶毒的评论——译者注)
我还让每个程序循环运行了10到1000次(根据程序的实际情况来定),以便让引擎优化器能够有机会编译热代码。一般情况下,SunSpider程 序运行只需要很少的时间。让程序运行很多次能够有效地使得SunSpider模仿真正应用程序运行的情况,因为真正的应用程序都是长时间运行的。
我选择的测试程序包括:binary-trees, 3D-morph, partial-sums, fasta, spectral-norm, nsieve和nbody。源代码可以从下列地址获取:
http://github.com/kannanvijayan/benchdalvik
免责声明:
我必须事先说明一点:我不敢说SunSpider就是一个***的测试基准软件,能够精确地反应真实的性能分析结果。实际上它更像是一系列小的基准测试程序的合集,能够在某种程度上反应出一些性能测试等级而已。
我选择SunSpider作实验的原始,是因为它里面的测试程序很容易能被拿出来,并且能够很清楚地从Javascript源代码转换成对应的 C++或者Java代码。总的来说,对不同语言平台的比较很难做到科学意义上的严格和准确。因此,即使是对这些小的基准测试,也必须要对结果做适当的分析 和估算,才能保持客观。
结果:
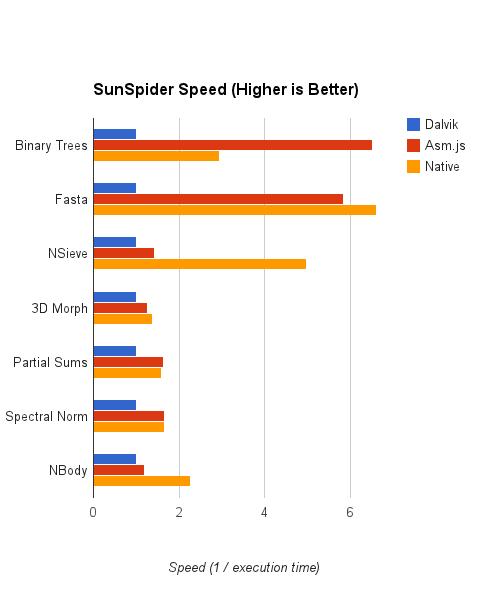
上图显示,asm.js的表现非常好,与原生代码的性能相当,甚至在某些测试上(binary-trees)比原生代码的性能还要好。这些数字本身,当然不能够解释为什么会如此,并且真正的原因也不会像数字这么有趣。那么,就让我们把趣味性放低一些,看看到底是什么造成了这样的结果。
#p#
分析:
二叉树测试
二叉树测试的得分是非常让人意外的。在这个测试里,asm.js版本的程序甚至比原生代码的表现还要好很多。这个结果似乎与常识相悖,但是其中也是有可以解释的原因的。
我们知道,二叉树的数据结构需要给很多对象分配内存。在C++里(实际上是在C语言里,因为malloc是CRT的函数——译者注),分配内存的操 作会大量调用malloc函数。当程序被编译成本地代码时,malloc方法会被大量调用,这个个方法本身就是非常消耗时间的。
在asm.js里,被编译后的C++代码在执行的时候会使用一个Javascript类型的序列,叫做“机器内存“。“机器内存”在整个程序的运行 期内只会分配一次。从asm.js产生的malloc方法不会执行系统级别的调用。这可能就是为什么asm.js编译出来的C++代码比编译成本地的 C++代码执行效率更高的原因,当然这个说法还有待于进一步的证实。
另一个问题是,为什么Dalvik表现那么糟糕。这就是Java需要优化的地方了:过于简单,采用固定大小的类结构,过多的琐碎的内存分配策略,等 等。我对Dalvik的性能问题并没有很好的答案——并且这个测试的结果也让我十分惊讶,我本以为Dalvik的表现应该比这好很多才对。
下面的说法纯属是我的猜测,不过我认为Dalvik的糟糕表现估计和tracing JIT有关。根据我与那些有tracing JIT研究经验的交流结果,我得知tracing JIT对递归的编译显得非常困难。鉴于二叉树的基本功能就是基于几个递归函数实现的,这也很可能就解释了为什么Dalvik的表现很糟糕的问题。如果读者 对此有更好的解释,请不吝赐教。
Fasta
注意到fasta程序已经修改,把makeCumulative操作移除主循环,放到了setup代码里。
Asm.js和本地C++代码都远比Dalvik的运行分数高,本地代码好像比asm.js的性能稍微好那么一点点。那么,让我们分析一下其中的原因。
从代码很容易看出来,程序花了很多时间在关联矩阵之间进行迭代,反复取值。在C++/asm.js版本的实现里,这些迭代操作是通过使用标注有 inlie关键字的hash_map结构来进行操作的,键采用char类型,值采用double类型,效率很高。在Java代码里,所有的迭代是通过 java.util.HashMap数据结构来操作的,并且采用了Character和Double的装箱类作为基本数据结构。
Java的HashTable迭代是非常耗费资源,并且很不直接的。迭代器会首先将指针转换为Map.Entry对象,而不是直接只用固定大小的实 例数组(C++就是这么做的),并且它还潜质奖char和double类型自动装箱成Character和Double的装箱类实例对象。Java集合类 虽然功能非常强大,但是它们在规模较大,结构较复杂的情况下才能有效地展现出威力,如果把本来可以用原生类型处理的结构再搞成集合,那反而会起到反作用。 这个fasta中的小小的查找表就完全违背了Java数据结构的本意。
C++和asm.js版本的程序就采取了更有效的存储模式来存储数据,并且采用了更有效的迭代器来处理数据。C++/asm.js还是用了单字节的 char, 而不是Java和Javascript的双字节char, 这也就意味着C++/asm.js的实现版本能够节约更多的存储空间。
总的来说,fasta测试的主要目的,是测试语言能够在多快的速度下找到与之相关的小序列。我相信Dalvik的表现不好的主要原因也在于Java语言本身:集合不支持原生数据类型,集合迭代器的资源消耗太大等等。
NSIEVE
在这个测试里,asm.js比本地程序慢了三倍,并且仅仅领先Dalvik一点点。
这是一个完全令人意想不到的结果——我本来以为asm.js的速度会和本地代码的速度差不多。Alon Zakai(Mozilla研究员,emscripte的作者)跟我说,在台式机电脑上(x86构架),asm.js的表现大约是本地代码的84%。这样 一来,问题就很可能出在SpikderMonkey的ARM代码生成上,而且应当是可以进行优化的。
3D Morph, Partial Sums, and Spectral Norm
我把这么多程序写在一起,主要是因为我觉得这些程序的得分基本上都可以用同样的道理来解释。
本地代码,asm.js和Dalvik的得分都很相似,本地代码比asm.js快一点点,asm.js又比Dalvik快更多一点点。(请忽略asm.js综合起来仿佛比本地代码还快一点的现象,我基本可以肯定这是实验中的误差造成的,实际上这两者可以算是齐头并进的)
这些程序都是基于双精度浮点数的。对于这种数据类型的运算,在ARM CPU上的代价是很高的,而且部分代码的运行速度差异很可能掩盖了整体性能的表现。
最令人惊讶的并不是asm.js和本地代码运行效率之间的比较,而是Dalvik仿佛比asm.js的得分大约落后了20%-30%。
NBody
我猜测asm.js的速度只有本地代码速度的一半。Nbody代码的主要逻辑是产生大量的二次间接寻址操作:从一个数组中挑出一个指针,然后从这个 指针的地址开始再读取一个偏移量的内存。每次读取操作都可以用ARM的单条指令来完成,采用带有多地址模式的ARM LDR指令即可:
例如,从一个指针数组中读取一个对象的指针,然后再从这个对象中读取一个属性,用下面两个指令就可以完成:
LDR TargetReg, [ArrayReg + (IndexReg leftshift 2)] LDR TargetReg, [TargetReg + OffsetOfField]
(如上,ArrayReg是一个寄存器,保存了一个指向数组的指针,IndexReg也是一个寄存器,保存了数组中的序列号,OffSetOfField是一个常量)
然而,在asm.js里面,“内存”读取操作实际上是在一个类型化了数组中完成的,“指针”实际上是指对应数组内部的整数偏移量。Asm.js里的指针与本地代码有所不同,因为它还包含了边界检查。与上面逻辑相同的逻辑代码实际上是由下面五条语句构成的:
LDR TargetReg, [ArrayReg + (IndexReg leftshift 2)] CMP TargetReg, MemoryLength BGE bounds-check-failure-address LDR TargetReg, MemoryReg + TargetReg LDR TargetReg, [TargetReg + OffsetOfField]
(如上,ArrayReg, IndexReg, 和 OffsetOfField都与之前相同,MemoryReg是用来保存TypeArray数组基址指针的寄存器,TypeArray数组在asm.js里面被用来表示内存。)
基本上看来,asm.js加入了额外的操作,从而让对内存的间接读取变得开销更大。因此这个测试完全依赖于其内部循环的情况,我认为大大地影响了降低了程序的性能。
请记住,上面所说的一切理由都是基于理论推测,没有进一步的实验和验证,下任何结论都是不符合事实的。
一点看法:
这个实验是相当有趣的。因此我产生了几点看法,我个人觉得都还挺有道理的:
1. 在ARM上,asm.js完全是一个可以和C++本地代码抗衡的语言。就算是去掉一个***分(就是asm.js比C++快的那个测试),asm.js依然 可以表现出本地C++代码70%的速度。这些测试结果说明,那些对性能需求很高的应用程序,完全可以采用asm.js来达到接近于本地代码的性能表现。
2. Asm.js跟Dalvik相比,拥有巨大的优势。即使是去掉一个***分(在二叉树测试和fasta中的那个结果),asm.js依然比Dalvik代码快10%-50%,并且这一优势十分稳定。
尾声:
敏感的读者一定会问:如果是直接用Javascript代码会怎么样?普通的Javascript代码性能太差,以至于我完全忽略它了?还是有什么猫腻我故意不提?
坦诚地说,我并没有把对普通Javascript代码的测试放到这次试验当中。因为普通的Javascript大码到目前为止表现得有些太好了,所以我觉得我还是不要把他们放到测试里面来,以免这些测试结果反而起到误导的作用。
因为一些原因,SunSpider的标准测试的得分会“相当不合理”,这多少还是有点让人遗憾的。所有的Javascript引擎,包括 SpiderMonkey,都多少使用了优化技术,例如先验式数学缓存(就是把正弦,余弦,正切等三角函数的值缓存起来,在使用的时候直接查内存表,而不 是真的去计算,以此来节省时间),来提高他们的SunSpider测试得分。这些专门针对SunSpider进行的优化,很讽刺地让SunSpider完 全失去了对纯粹Javascript代码运行效率测评的客观性。