众所周知,对比传统的关系型数据库,NoSQL有着更为复杂的分类——键值、面向文档、列存储、搜索引擎等等。繁多的分类让NoSQL有着更强的业务针对性,因此在性能上对比传统关系型数据库有着颠覆性的提升。然而这种针对性同样给企业带来了一定程度的困扰,比如专业工程师的培养/聘请、架构的变迁等,同时这种群雄割据的局面也不利于NoSQL的整体发展。通用、统一才能有更好的发展;随着NoSQL的发展,我们似乎也越来越需要一种技术去打开当下这个局面。
近日,MapR Technologies的首席数据工程师Michael Hausenblas与DataStax的联合创始人兼CTO Jonathan Ellis针对这个问题展开了讨论,并就“HBase是否能成为NoSQL领域的领导者”发表了不同的观点。在看他们观点之前,我们首先看一下为什么会是HBase。
HBase及NoSQL现状
HBase是Google BigTable的仿制品,当下最流行大数据处理平台Apache Hadoop的一部分。高贵的血统无疑让HBase备受关注,也给它带来了更广阔的发展空间。然则HBase的人气究竟如何,我们不妨看一下 DB-Engines的数据库人气排行榜 :
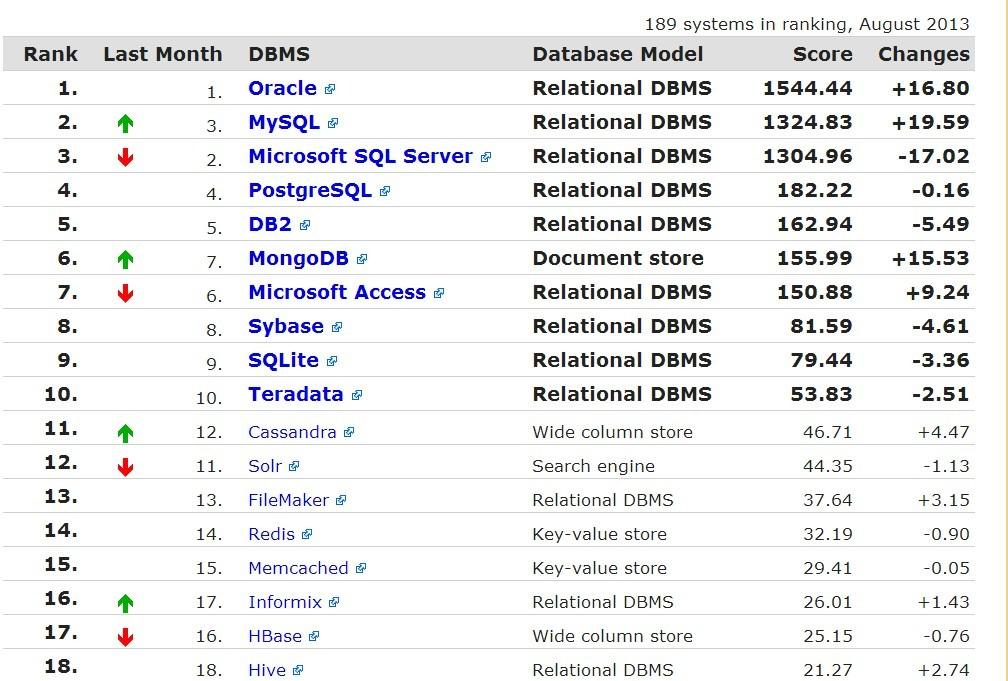
从最新的排行榜我们可以发现前10中只有一个NoSQL数据库——MongoDB,而HBase排名第16,NoSQL领域第6,在列存储数据库中排名也只是第2,第1被Cassandra抢走。

上表是2013年1月份的部分排行,对比MongoDB、Cassandra这些人气增长很快的数据库,HBase的增长也并不突出。
如此看来即使HBase最后可以成为NoSQL领域的领军者,这条成功路上也是遍地荆棘。长话短说,下面就看一下两位数据领域佼佼者的不同看法,以下为译文:
正方:Michael Hausenblas是MapR Technologies的首席数据工程师兼EMEA。在大规模数据集成研究和开发上有着丰富的经验。他认为,基本上所有NoSQL解决方案都有着技术限制,而与Hadoop的整合将大幅度提高HBase的采用率。
HBase制霸将是个必然的结果,但是……
为了理解这个问题,我们必须和现状集合起来。Martin Fowler及Mike Stonebraker都认为“混合持久化”才是王道,“同一个标准不可能适合所有人”。
因此这里我说的制霸不是传统数据库过去10年内一直使用的市场份额的标准,而是“Apache HBase是不是拥有更广泛的使用场景,以及是否比其它数据库拥有一个更大的社区”。
我们可以大胆断言的是:当下可供选择的NoSQL技术已经超过100种(DB-Engines排行榜已收录114个NoSQL数据库),包括MongoDB、Riak、Couchbase、Cassandra等等。但是在这个大数据的时代,趋势不再是专业的信息持久化,而是大规模的多样数据处理,因此即使是MongoDB如此流行的NoSQL也必将会被HBase超越。
为什么?因为MongoDB有明显的扩展性缺陷,而随着Hadoop采用的快速增长,类似HBase这种内置的NoSQL解决方案在规模和人气上都有着天生的市场优势。HBase拥有不同方面巨大而多元化的社区,它连接着多个方面:用户、开发者、多个商业供应商以及云端的可用性——来自AWS最新的功能。
从两个数据库的历史上看,HBase和Cassandra拥有很多相同之处。HBase于2007年在Powerset建立(后被微软收购),开始是作为Hadoop的一部分,后来成为一个Top-Level-Project。Cassandra则是2007年起源于Facebook,开始是开源项目,后由Apache孵化,当下同样是个Top-level-Project。不管是HBase还是Cassandra都是列存储键值类型数据库,都拥有良好的横向可扩展性、健壮性和弹性,擅长处理巨大体积的数据。
但是他们在设计理念上却有着天壤之别:Cassandra借鉴了许多Amazon DynamoDB系统的元素,使用最终一致模型,并且进行了写入优化;而HBase克隆的是Google的BigTable,进行了读取优化,并拥有强一致性。这里HBase存在一个很有意思的强项就是——Facebook,Cassandra的制造者,使用HBase代替了Cassandra在他们内部使用。
从开发者角度上来看,HBase提供的强一致性会让开发过程变得轻松。而这里对于最终一致性存在的误区就是:它改善的是写入的速度——持续的写操作可能会造成延迟,为了保持最终一致性付出了代价,却没有达到应有的效果。
基本上所有NoSQL解决方案都存在技术限制,比如会导致高延时的压缩、无法自动分片、可靠性隐患以及节点故障转移时间太长。而在MapR建立的企业版HBase中,我们提供了立即恢复、无缝分片以及高可用性,同时还剔除了压缩。
最后,鉴于HBase与Hadoop生态系统的整合力度,它可以更好的与Hive、Pig等组件协作。
汇总,HBase必然制霸小规模写入及大规模查询的使用场景,而最近的一些创新提供的架构优势也可以用于摆脱压缩的困扰。
反方:Jonathan Ellis是初创公司DataStax的联合创始人兼首席技术官,而DataStax是一家著名开源软件公司。他认为HBase受众多的缺陷困扰,比如:部署难、操作复杂、社区零散以及致命的架构缺陷。种种因素之下,HBase根本不具备成为领导者的资质。
NoSQL有着不同的专长,比如:某些领域HBase就无法与图数据库和文档数据库匹敌;但是即使是列存储数据库中,HBase也不能独占鳌头。导致HBase采用率一般的问题在于:可以通过投入巨量物理和人力解决的工程问题和无法弥补的天生架构缺陷。
工程问题
1. 运营的复杂并且容易发生故障
HBase的配置非常麻烦,最低的限度都需要包括Zookeeper ensemble、primary HMaster、secondary HMaster、RegionServers、active NameNode、standby NameNode、HDFS quorum journal manager及DataNodes。虽然配置可以自动化,但是如果无帮助下安装难度太大,在故障发生时,你如何去寻找故障,比如:RegionServer失效或者一个 lower-level NameNode故障。使用HBase需求大量的专业知识——甚至是最简单的监视;如果你需要定期的备份,那么你可以去寻求上帝的帮助了!
2. RegionServer故障转移需要10到15分钟
HBase将行分割到不同的region中,通过 RegionServer来管理。RegionServer存在单点故障,当它发生故障时,一个新的RegionServer必须被选举出,而在可以投入之前,必须重新完成write-ahead日志里的内容。
3. 使用HBase开发是非常痛苦的。
HBase的API非常笨拙并且具有太强的Java特色,非Java客户端只能委托给Thrit或者REST。对比起来,Cassandra Query Language则提供了多语言开发者都熟悉的体验。
4. HBase社区就是盘散沙
以Apache为主的社区是众所周知的不稳定,Cloudera、Hortonworks以及其他高端用户都是在闭门造车。相反开源的Cassandra社区各个机构间毫无派系,比如DataStax、Netflix, Spotify、Blue Mountain Capital等。
总的来说,HBase和其它NoSQL平台间的差距越来越大。在我第一次评估的时候,HBase的工程进展可能会差Cassandra 6个月,而如今至少差2年。
架构缺陷
1. Master-oriented的设计让HBase失去了灵性
通过RegionServer master来路由所有读写操作意味着HBase丧失了数据中心的active/active异步复制,你也不能在一个集群的不同副本集中单独的执行工作负载。想比之下,Cassandra的peer-to-peer复制却允许与Hadoop的无缝集成,当你需求线性一致性,没有ETL的Solr和Cassandra却允许你少量使用轻量级事务。
2. 故障转移意味着宕机
许多应用甚至不能容忍1分钟的宕机,而这恰恰是HBase设计的固有问题,每个RegionServer都是个单点故障。然而一个分布式系统应该是在某个副本发生故障,我们不需要做特殊的恢复处理,系统仍然能正常运作。
3. HDFS是主要为大体积文件设计的流访问系统
HBase建立于一个专为批处理优化的文件系统,这直接导致了HBase的低性能。特别是读取,尤其是使用SSD的情况。就像是30年前为准大数据负载设计、未优化B树的传统关系型数据库引擎,HDFS并未做好主要设计目的与关键功能弥补上的平衡:
在同一个集群中混合机械和固态硬盘,并为负载分配适当的硬盘类型
快照、增量备份和及时的恢复
压缩流量以避免应用程序的峰值响应时间
动态的将请求路由到性能最高的副本上
HBase基于批处理的设计决定了它低下的性能,使其无法适应高速、随机访问负载,然而NoSQL运动的特性恰恰是这些,因此HBase永远不可能制霸NoSQL领域。