












与大多数互联网公司一样,旅行房屋短期租赁网站Airbnb也希望通过分析海量数据提升用户体验和业务营收。Gigaom最近撰文介绍了Airbnb如何在亚马逊云的基础上打造大数据基础架构,并将数据分析作为产品和业务决策的基础,编译整理如下:
“我们希望所有的决策都基于数据,我们希望成为数据驱动的公司”。这是今天硅谷企业家的梦想,Airbnb副总裁Mike Curtis也不例外。Curtis加盟Airbnb不到半年,此前两年他的履历是Facebook的工程总监。
“在推动数据科学在旅游业的应用方面,没有人比我们做得更多。长期看,这需要很多金刚钻。”Curtis说道。
个性化搜索的挑战
Airbnb的一大数据难题是找到即将推出的个性化搜索的最佳方式,我们希望客户能找到符合他们个性化要求的最佳选择。
但是为不同的用户个体提供个性化的搜索排名会带来非常棘手的算法难题。搜索结果依据社区或地理位置排名还相对简单,但是要加入用户决策的其他因素,例如社会关系、租赁历史、评价等数据点后,整个事情就变得复杂起来。(如果加入Airbnb的城市、客户和租户的人口统计以及其他租赁元数据的话,问题就更加复杂)
Twitter的个性化搜索引擎就整合了大量判断相关度的因素,其背后涉及的数据科学问题就非常复杂。
此外,Airbnb还需要通过数据分析帮助房主制订最佳的房屋租赁价格。
Airbnb也希望能够走Facebook的路子,让Hadoop成为所有公司员工都能轻松使用的强大工具。
Mesos是关键
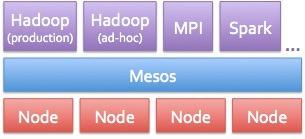
Mesos的架构图
Airbnb实现大数据梦想的战略性工具是一个名为Mesos的开源集群管理项目。该技术来自加州伯克利的AMPLab实验室(该实验室开发的技术例如Spark内存并行处理框架可以让Hadoop运行得更快,比MapReduce快100倍)。可以让用户在单一资源上运行多种计算框架,当然,也可以是多个独立的Hadoop集群。Twitter的使用让Mesos在互联网圈声名鹊起,上周Mesos已经成为Apache的顶级项目。
对于Airbnb来说,Hadoop之外,Mesos也是Airbnb工程师们最大化利用亚马逊AWS云资源的的关键工具。Airbnb是Hadoop的重度用户,但Curtis希望能测试流处理的Storm,还希望能用Spark加速Hive查询。
事实上,Spark对搜索排名、定价、错误排查等算法模型来说特别有用,这些模型大多涉及机器学习,而Spark能大大提升Hadoop的性能,能更快更多地运行这些模型。
Airbnb开发的一个分布式任务计划器——Chronos,也运行在Mesos上。
除了资源管理和效率提升外,Curtis表示Mesos还能有助于推动Airbnb搭建高机动性小团队的工程战略。Airbnb资源分配的自动化水平越高,工程师们就能腾出更多时间做其他事情。
云计算的可以,MapReduce的不要
虽然Airbnb运行在AWS云上,但通过Mesos,Airbnb可以不使用亚马逊的Elastic MapReduce Hadoop服务。据Curtis透露,Airbnb这么做的原因有很多,其中最重要的一点是可以通过Mesos统一管理所有其他Airbnb需要运行的框架,而且能对Hadoop环境控制的粒度更好。Elastic MapReduce也可以看作是亚马逊自己的Hadoop发行版本,这意味着用户需要依赖AWS提供补丁升级,而且仅仅是为了Hadoop任务而准备的。
Airbnb的另外一位工程师Brenden Matthews上周在Twitter总部的一次演讲(演示文稿)介绍了Airbnb如何从Elastic MapReduce迁移到Mesos上,以及在云端运行Hadoop经常会遇到的一些技术难题。
Curtis认为,AWS总体来说还是稳定的,搭配Mesos使用后,Airbnb可以随时做需要做的任何事情。Airbnb的ad hoc分析查询也不会与长时间运行的批量工作流冲突。
“在集群上跑任务的速度实际上是一个资源分配问题,取决于你需要投入的资源”Curtis说道。
总之,云计算让Airbnb这样的创业公司在前期只有少量投入的情况下就能购买和管理服务器,“想想如今大部分服务器都被抽象化了,这确实是一件美妙而惊人的事情。”Curtis感叹道。
原文链接:http://www.ctocio.com/ccnews/13073.html
















