













架构
Cascading 是一个架构在Hadoop上的API,用来创建复杂和容错数据处理工作流。它抽象了集群拓扑结构和配置来快速开发复杂分布式的应用,而不用考虑背后的 MapReduce。Cascading目前依赖于Hadoop提供存储和执行架构,但是Cascading API为开发者隔离了Hadoop的技术细节,提供了不需要改变初始流程工作流定义就可以在不同的计算框架内运行的能力
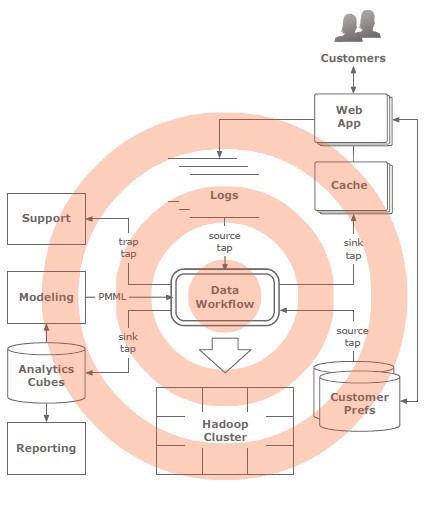
Cascading目前依赖于Hadoop提供存储和执行架构,但是Cascading API为开发者隔离了Hadoop的技术细节,提供了不需要改变初始流程工作流定义就可以在不同的计算框架内运行的能力。
Cascading使用了“pipe and filters”(管道和过滤)来定义数据处理进程。它支持分隔,合并,分组和排序操作,这是开发者唯一需要考虑的操作。Nathan Marz提供了一个范例:Goodbye MapReduce, Hello Cascading. Cascading对于使用Hadoop开发复杂应用是一个不错的解决方案。
发展
Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊、Facebook和Yahoo等等。它主要由MapReduce的算法执行和一个分布式的文件系统HDFS等两部分组成。
HDFS:即Hadoop Distributed File System (Hadoop分布式文件系统)
HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。
延伸
MapReduce:MapReduce 是Google 的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来 说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
















