













Hadoop并行处理可以成倍地提高性能。现在的问题是如果将一部分计算工作从CPU迁移到GPU会怎么样?能否更快理论上,这些处理如果经过了并行计算的优化,在GPU上执行会比CPU快50-100倍。作为大数据专家和PaaS的推动者,Altoros Systems研发团队一直致力于探索Hadoop+GPU的可能性,以及在实际的大规模系统中的实现,这篇文章就是他们的部分研究成果。作者 Vladimir Starostenkov是Altoros Systems的资深研发工程师,他在实现复杂软件架构( 包括数据密集型系统和Hadoop驱动的应用程序)方面有五年经验,而且 对人工智能和机器学习算法也很感兴趣。
技术现状:
多年来,有很多将Hadoop或MapReduce应用到GPU的科研项目。 Mars可能是第一个成功的GPU的MapReduce框架。采用Mars技术,分析WEB数据(搜索和日志)和处理WEB文档的性能提高了1.5-1.6倍。 根据Mars的基本原理,很多科研机构都开发了类似的工具,提高自己数据密集型系统的性能。相关案例包括 分子动力学、数学建模(如Monte Carlo)、基于块的 矩阵乘法、财务分析、图像处理等。
还有针对网格计算的 BOING系统,它是一个快速发展、志愿者驱动的中间件系统。尽管没有使用Hadoop,BOINC已经成为许多科研项目加速的基础。例如, GPUGRID是一个基于BOINC的GPU和分布式计算的项目,它通过执行分子模拟,帮助我们了解蛋白质在健康和疾病情况下的不同作用。多数关于医药、物理、数学、生物等的 BOINC项目也可以使用Hadoop+GPU技术。
因此,使用GPU加速并行计算系统的需求是存在的。这些机构会投资GPU的超级计算机或开发自己的解决方案。硬件厂商,如Cray,已经发布了配置GPU和预装了Hadoop的机器。Amazon也推出了EMR(Amazon Elastic MapReduce),用户可以在其配置了GPU的服务器上使用Hadoop。
超级计算机性能很高,但是成本达数百万美元;Amazon EMR也仅适用于延续几个月的项目。对于一些更大的科研项目(两到三年),投资自己的硬件更划算。即使在Hadoop集群内使用GPU能提高计算速度,数据传输也会造成一定的性能瓶颈。以下会详细介绍相关问题。
工作原理
数据处理过程中,HDD、DRAM、CPU和GPU必然会有数据交换。下图显示了CPU和GPU共同执行计算时,数据的传输。
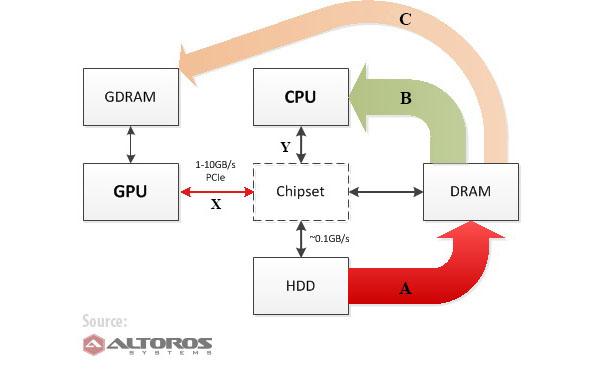
图:数据处理时,各组件之间的数据交换
箭头A :数据从HDD传输到DRAM(CPU+GPU计算的初始步骤)
箭头B :CPU处理数据(数据流:DRAM->chipset->CPU)
箭头C :GPU处理数据(数据流:DRAM->chipset->CPU->chipset->GPU->GDRAM->GPU)
完成任何任务所需的时间总量包括:
CPU或GPU进行计算所需的时间
数据在各个组件间传输所需的时间
根据Tom’s HARDWARE 2012年的CPU图表,CPU的平均性能在15到130GFLOPS之间,而Nvidia GPU的性能范围在100到3000+ GFLOPS。这些都是统计值,而且很大程度上取决于任务的类型和算法。无论如何,在某些情况下,一个GPU可以使节点速度加快5至25倍。一些开发者声称,如果你的集群包括多个节点,性能可以提高50到200倍。例如,MITHRA项目达到了254倍的性能提升。 #p#
性能瓶颈:
那么,GPU对数据传输会有什么影响?不同类型的硬件传输数据的速率不同,超级计算机已经在GPU上做过相关优化,一个普通的计算机或服务器在数据传输时可能会慢得多。 通常在一个CPU和芯片集数据传输速率在10到20GBps之间(图中的Y点),GPU和DRAM间的数据交换速率在1到10GBps之间(图中的X点)。虽然一些系统速率可达10GBps(PCI-E v3),大部分标准配置的GDRAM和DRAM间数据流速率是1GBps。(建议在真实的硬件环境中来测量实际值,因为CPU内存带宽[X和Y]以及对应的数据传输速率[C和B]可能差不多也可能相差10倍)。
虽然GPU提供了更快的计算能力,GPU内存和CPU内存间的数据传输(X点)却带来了性能瓶颈。因此,对于每一个特定的项目,要实际测量消耗在GPU上的数据传输时间(箭头C)以及GPU加速节省的时间。因此,最好的方法是根据一个小集群的实际性能估计更大规模系统的运行情况。
由于数据传输速率可能相当慢,理想的情况是相比执行计算的数目,每个GPU输入/输出数据的量比较小。切记:第一,任务类型要和GPU的能力相匹配,第二任务可以被Hadoop分割为并行独立的子流程。 复杂的数学公式计算(例如矩阵乘法),大量随机值的生成,类似的科学建模任务或其它通用的GPU应用程序都属于这种任务。
可用的技术
JCUDA:JCUDA项目为Nvidia CUDA提供了Java绑定和相关的库,如JCublas、JCusparse(一个矩阵的工作库)、JCufft(通用信号处理的Java绑定)、JCurand(GPU产生随机数的库)等等。但 它只适用于Nvidia GPU。
Java Aparapi。Aparapi在运行时将Java字节码转换为OpenCL,并在GPU上执行。所有的Hadoop+GPU计算系统中,Aparapi和OpenCL的前景最被看好。Aparapi由AMDJava实验室开发,2011年开放源代码,在AMD Fusion开发者峰会的官网上可以看到Aparapi的一些实际应用。OpenCL是一个开源的、跨平台的标准,大量硬件厂商都支持这个标准,并且可以为CPU和GPU编写相同的代码基础。如果一台机器上没有GPU,OpenCL会支持CPU。
创建访问GPU的本地代码。访问GPU本地代码进行复杂的数学计算,要比使用绑定和连接器性能高很多,但是,如果你需要在尽可能短的时间内提供一个解决方案,就要用类似Aparapi的框架。然后,如果你对它的性能不满意,可以将部分或整个代码改写为本地代码。可以使用C语言的API(使用Nvidia CUDA或OpenCL)创建本地代码,允许Hadoop通过JNA(如果是Java应用程序)或Hadoop Streaming(如果是C语言应用程序)使用GPU。
GPU-Hadoop框架
也可以尝试定制的GPU-Hadoop框架,这个框架启动于Mars之后,包括Grex、Panda、C-MR、GPMR、Shredder、SteamMR等。但是GPU-Hadoop多用于特定的科研项目,并且不再提供支持了,你甚至很难将Monte Carlo模拟框架应用于一个以其它算法为基础的生物信息项目。
处理器技术也在不断发展。在Sony PlayStation 4中出现了革命性的新框架、Adapteva的多核微处理器、ARM的Mali GPU等等。Adapteva和Mali GPU都将兼容OpenCL。
Intel还推出了使用OpenCL的Xeon Phi协同处理器,这是一个60核的协同处理器,架构类似于X86,支持PCI-E标准。双倍精度计算时性能可达1TFLOPS,能耗仅为300Watt。目前最快的超级计算机天河-2就使用了该协同处理器。
很难说以上哪种框架会在高性能和分布式计算领域成为主流。随着它们的不断改善,我们对于大数据处理的理解可能也会改变。












