之前的报道中,从架构的角度剖析了Netflix的大规模Hadoop作业调度工具。其储存主要基于Amazon S3(Simple Storage Service),利用云的弹性来运行多个Hadoop集群的动态调整,从而应对不同类型的工作负载,这个可横向扩展的Hadoop平台即服务就被称为Genie。而近日,这头来自Netflix的妖怪终于被放出神灯, 于GitHub上开源 。在这里不得不感叹一句Amazon确实该给Netflix颁发个最佳生态伙伴奖。
这头妖怪究竟是什么
Genie提供了Hadoop环境云中的作业和资源调度,从终端用户的角度,Genie剥离了各种Hadoop资源的物理细节,无需安装Hadoop客户端情况下提供了一个监视及提交Hadoop、Hive和Pig作业的途径——REST-ful Execution Service,负责整个集群以及相关的Hive和Pig配置。
为什么要建立Genie
Netflix建立Genie的主要原因有两个。首先是需要在云端运行不同规模的Hadoop集群来应对Netflix不同的工作负载。其中有一些是根据需要启动的,瞬态的;举个例子,在夜间Netflix需要启动“bonus”Hadoop集群来增加资源做ETL(抽取、转换以及加载)处理。还有一些不停运行的集群,比如常规的SLA及ad-hoc集群;但是有时也会停机,因为Netflix使用的是云服务,所以还受到云服务稳定性的影响。用户通过集群名称或者是所支持的负载类型来查找这些集群的最新版本,在数据中心这一般不成问题,因为这里的Hadoop集群不会时不时宕机,但是在云端却是不可避免需要面对的挑战。
其次,有些终端用户期望运行自己的Hadoop、Hive或者Pig作业——其中很少数的人甚至期望运行自己的集群,更甚至是安装客户端软件以及下载所有作业需要运行的配置。一般来说不管是数据中心还是云端都存在这种需求:使用一个可以实现很多功能的REST-ful API去运行作业,比如利用它来建立网络UI、工作流模板以及封装了日常所需的可视化工具。
Genie与一些工具的区别
首先,Genie不是个工作流调度程序,比如Oozie。Genie的执行单位是单一的Hadoop、Pig或者是Hive作业。Genie不会调度或者是运行工作流,事实上,Netflix使用的是一个企业版调度程序(UC4)来运行ETL。
其次,Genie不是一个任务调度程序,比如Hadoop的一些性能调度其等。Genie从本质上讲是个资源“红娘”,基于作业参数和集群性能为作业分配合适的集群。如果可供作业运行的有多个集群,Genie将随机的对其进行分配。当然这里可以加入一个定制的负载平衡器,为作业和集群的匹配进行更好的优化;然而,目前并不存在这样一个负载均衡器。
最后,Genie同样不是一个终端到终端的资源管理工具,它不会提供或者是启动一个集群,同样也不会基于集群的利用率开启或者关闭集群。然而Genie可以与他们合作达到更好的效果,作为一个集群的资源库以及一个用于作业管理的API。
Genie的工作方式
下图详述了Genie的核心组件,以及它的两个类型Hadoop用户——管理员和终端用户。
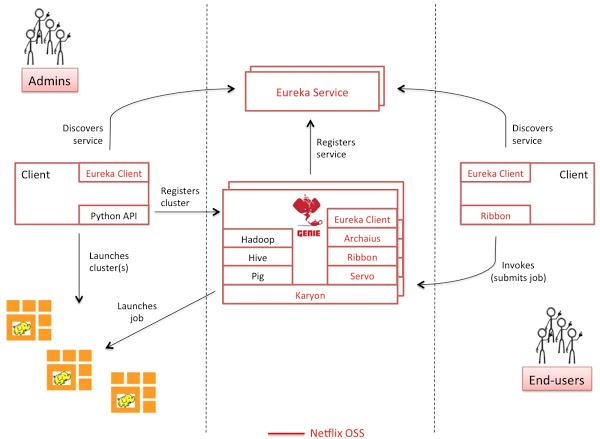
Genie本身构建于以下几个Netflix OSS组件之上:
Karyon——提供了引导、运行时分析(runtime insight)、诊断以及为不同云准备的Hook。
Eureka——提供了服务的登记及一些搜索功能(比如搜寻活动的Genie实例)
Archaius——提供云端的动态管理特性
Ribbon——提供了Eureka的整合,以及为REST-ful提供客户端负载均衡和进程间通信
Servo——提供了输出测量,并通过JMX登记(Java管理扩展),并将他们发送给外部监视系统,比如Amazon的CloudWatch
Genie现已可以从GitHub上下载,并部署到一个类似Tomcat的容器中。但是仅仅这么部署并未起到太大作用,除非你为其注册一个Hadoop集群。给Genie注册Hadoop集群可以通过以下几个步骤:
Hadoop管理员启动一个Hadoop集群,比如使用EMR客户端API。
将集群的Hadoop和Hive配置上传到S3上的某个位置
管理员使用Genie客户端通过Eureka来寻找一个Genie实例,调用REST-ful注册集群的配置,这里会使用到的属性有:唯一id、集群的名称以及一些其它的属性;比如它支持“SLA”作业以及“prod”元存储。如果建立一个新的元存储配置,同样需要与Genie注册一个新的Hive或者Pig配置。
当集群注册后,Genie已经可以完成终端用户所有的愿望——提交Hadoop、Hive和Pig作业。终端用户使用Genie客户端来发布和监视Hadoop作业。客户端内部会使用Eureka去寻找一个活动的Genie实例,Ribbon则会去执行客户端的内部负载均衡,并与服务的RESTfully通信。这里用户需要指定的作业参数包括:
作业的类型,Hadoop、Hive或者是Pig
作业的命令行参数
S3上一组文件的依赖关系,包括脚本或者是UDF(用户定义函数)
用户还必须告知Genie需要选择的集群类型。这个方面,可以有许多选择——使用集群名称或者是集群ID来指定特定的集群,或者使用计划表(比如SLA)和元存储配置(比如prod),这样的话Genie就会根据这些参数为作业选择一个合适的集群去运行作业。
Genie为每个作业建立了一个新的工作目录,演算所有依赖性(包括了Hadoop、Hive以及Pig用于选择集群的配置),然后从那个工作目录下选择一个Hadoop客户端进程。接着会返回一个Genie作业ID,客户端可以根据这个ID来查询作业状态,以及获得输出URI,可以用于作业执行期间以及执行后的查询(详见下图)。用户可以使用它来监视标准输出以及Hadoop客户端错误,在发生错误时同样可以查看Hive及Pig的客户端日志。
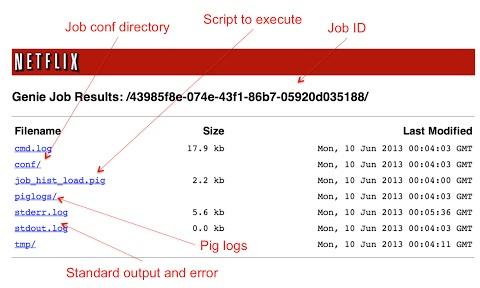
Genie的执行模型非常简单,Genie为新工作目录下的每个作业选择一个新的进程。这种简单、重要工作模式有益于每个作业之间以及与Genie的隔离,同样也方便操作标准输出、错误发生以及终端用户作业日志(这些都可以从输出URI中查看)。这里Netflix并没有在Genie内部使用作业队列,因为如果要实现Genie内部队列的话,还必须实现共享及性能调度程序,但是这些在Hadoop层已经实现。鉴于底层是使用JVM来处理每个作业,这样的话基于可用内存,每个Genie实例上并行执行作业的数量都是有限的。
Genie在Netflix的部署
Genie使用ASG(Auto-Scaling Group)进行横向扩展,这样通过Asgard进行云管理和部署,Netflix可以运行上千的Hadoop并行作业。在针对容错设置的多个可用区域使用Asgard计算最小、渴望以及最大实例数量。对于Genie服务器推送,Asgard提供了“sequential ASG”理念,这将允许在新ASG发布后立即给新的Genie实例路由通信,并且通过关闭旧ASG切断与旧实例的通信。
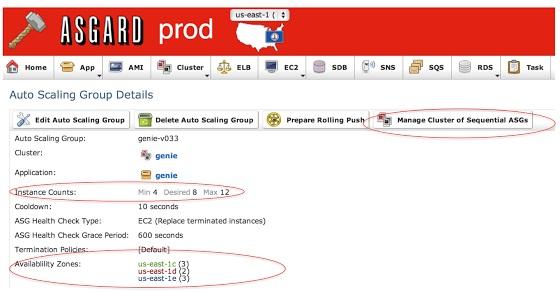
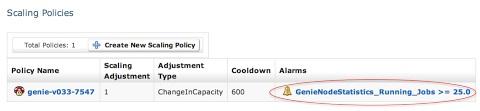
通过使用Asgard,同样可以为动态负载设置扩展策略。下方的截图就是一个简单的策略,一旦所有实例上的平均作业数量大于25就会自动开启一个Genie实例。
Genie在Netflix的实践
Netflix已使用Genie日处理近万的Hadoop作业,处理上千TB的数据。下图显示了Netflix几个月内一些集群的概况:
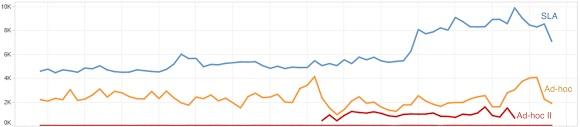
蓝线代表了SLA类集群中的一个,橙线则表示一个主要的ad-hoc集群。红线则代表了另一个ad-hoc集群,它使用了一个实验版本的共享调度程序,而Genie会随机给这两个ad-hoc集群中的一个分配作业。当对新调度器带能的性能感到满意时,Netflix果断在另一个更大的ad-hoc集群上投入使用(同样用橙线表示),而所有新的ad-hoc Genie作业都被路由到这个新的集群,而两个老集群也随着运行作业的完成被关闭。
结束语
虽然Genie有着强大的功能,但Netflix认为Genie还有很多地方可以继续提高;比如设计一般的数据模型,这些都带有很强烈的Netflix及云色彩。Netflix希望能得到更多关于产品的反馈,从而进行更好的改善。