













在Facebook上,人们已经形成了一个复杂的社会关系网络,如何去存储、扩展和展示这个网络是Facebook工程师的一大难题。早在几年前,Facebook的工程师就意识到:关系型数据库的老方法,正在逐步降低基础设施和代码的效率。2009年,他们开始设计一种新的数据库体系结构,也就是分布式数据库TAO(The Associations and Objects)。6月25日,Facebook在官方博客上公布了支持其基础设施细节。
Facebook的软件工程师Mark Marchukov在博客中表示他们之所以创建TAO的原因之一在于同时使用MySQL和Memcached读取数据太复杂了。产品工程师要工作在两种完全不同的数据模型之间:大规模的MySQL服务器用关系表存储持久数据,类似数量的缓存数据服务器用来存储SQL查询到的键值对。即便是封装在数据访问库中最常见的操作,也需要产品工程师对系统内部有充分的了解,才能高效地使用memcache-MySQL组合。
TAO的图型架构在信息组织方面类似于Facebook的图搜索工具,它将世界看作由节点(对象,即人、地点和事物)和边(关联,即他们之间的关系)组成的图。随着数据量的增大,保持数据的关系模式变得不再重要,TAO及其对应的API应运而生。
Marchukov认为TAO最大的突破在于实现了图解模型,Facebook的主要工作负载在于读取数据,TAO证明了图数据模型很适合这类查询操作较多的网站。实际上,类似Neo4j的图形数据库一直备受关注,因为它能有效表示人际关系。
Marchukov 在博客中提到,TAO不仅大规模实现了图数据结构,也使用MySQL实现硬盘上的持久存储,同时要保证数据在各个数据中心的最终一致性,用户才能获取“新鲜事”。
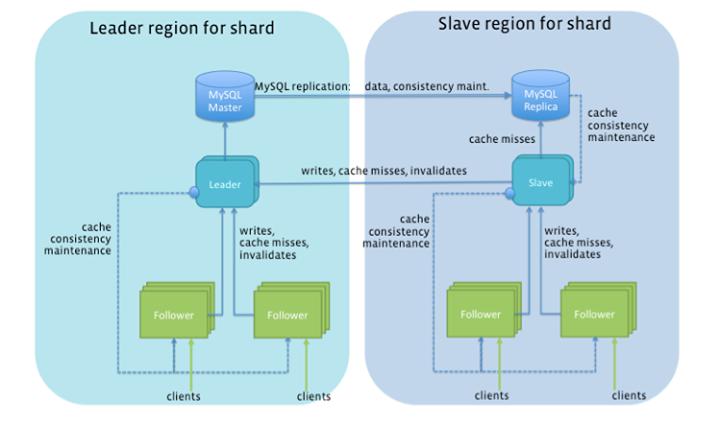
TAO服务运行在大量的服务器集群上,这些分布在不同地理位置的集群构成一个树形网络。有另外的集群用来持久存储对象和对象关联,RAM和闪存实现缓存。这种分层结构在单独进行不同类型的集群扩展时更方便,也能有效利用服务器硬件。



















