背景
Web程序的后端主要有两个东西:渲染(生成HTML,或数据序列化)和IO(数据库操作,或内部服务调用)。今天要讲的是后面那个,关注一下如何减少数据库往返这个问题。最快的查询是不存在的,没有最快,只有更快!
开始讲之前我得提一下Schema的重要性,但不会在这花太多时间。单独一个因素不会影响程序的整体响应速度,有调数据的能力,比有一个好的数据(库)Schema要强得多。这些东西以后会细讲,但Schema问题常会限制你的选择,所以现在提一下。
我也会提一下缓存。在理想情况下,我要讨论的东西能有效减少返回不能缓存或缓存丢失的数据的时间,但跟通过优化查询减少数据库往返次数一样,避免将全部东西扔进缓存里是个极大的进步。
最后得提一下的是,文中我用的是Python(Django),但原理在其他语言或ORM框架里也适用。我以前搞过Java(Hibernate),不太顺手,后来搞Perl(DBIX::Class)、Ruby(Rails)以及其他几种东西去了。
N+1 Selects问题
关于数据库往返最常见又让人吃惊的问题是n+1 selects问题。这个问题最简单的形式包括一个有子对象的实体,和一对多的关系。下面是一个小例子。
from django.db import models
class State(models.Model):
name = models.CharField(max_length=64)
country = models.ForeignKey(Country, related_name='states')
class Meta:
ordering = ('name',)
class City(models.Model):
name = models.CharField(max_length=64)
state = models.ForeignKey(State, related_name='cities')
class Meta:
ordering = ('name',)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
上面定义了州跟市,一个州有0或多个市,这个例子程序用来打印一个州跟市的内联列表。
Alaska
Anchorage
Fairbanks
Willow
California
Berkeley
Monterey
Palo Alto
San Diego
San Francisco
Santa Cruz
Kentucky
Albany
Monticello
Lexington
Louisville
Somerset
Stamping Ground
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
要完成这个功能的代码如下:
from django.shortcuts import render_to_response
from django.template.context import RequestContext
from locations.models import State
def list_locations(request):
data = {'states': State.objects.all()}
return render_to_response('list_locations.html', data,
RequestContext(request))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
...
<ul>
{% for state in states %}
<li>{{ state.name }}
<ul>
{% for city in state.cities.all %}
<li>{{ city.name }}</li>
{% endfor %}
</ul>
</li>
{% endfor %}
</ul>
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
如果将上面的代码跑起来,生成相应的HTML,通过django-debug-toolbar就会看到有一个用于列出全部的州查询,然后对应每个州有一个查询,用于列出这个州下面的市。如果只有3个州,这不是很多,但如果是50个,“+1”部分还是一个查询,为了得到全部对应的市,“N"则变成了50。
2N+1 (不,这不算个事)
在开始搞这个N+1问题之前,我要给每个州加一个属性,就是它所属的国家。这就引入另一个一对多关系。每个州只能属于一个国家。
Alaska (United States)
...
- 1.
- 2.
...
class Country(models.Model):
name = models.CharField(max_length=64)
class State(models.Model):
name = models.CharField(max_length=64)
country = models.ForeignKey(Country, related_name='states')
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
...
<li>{{ state.name }} ({{ state.country.name }})
...
- 1.
- 2.
- 3.
在django-debug-toolbar的SQL窗口里,能看到现在处理每个州时都得查询一下它所属的国家。注意,这里只能不停的检索同一个州,因为这些州都是同一个国家的。
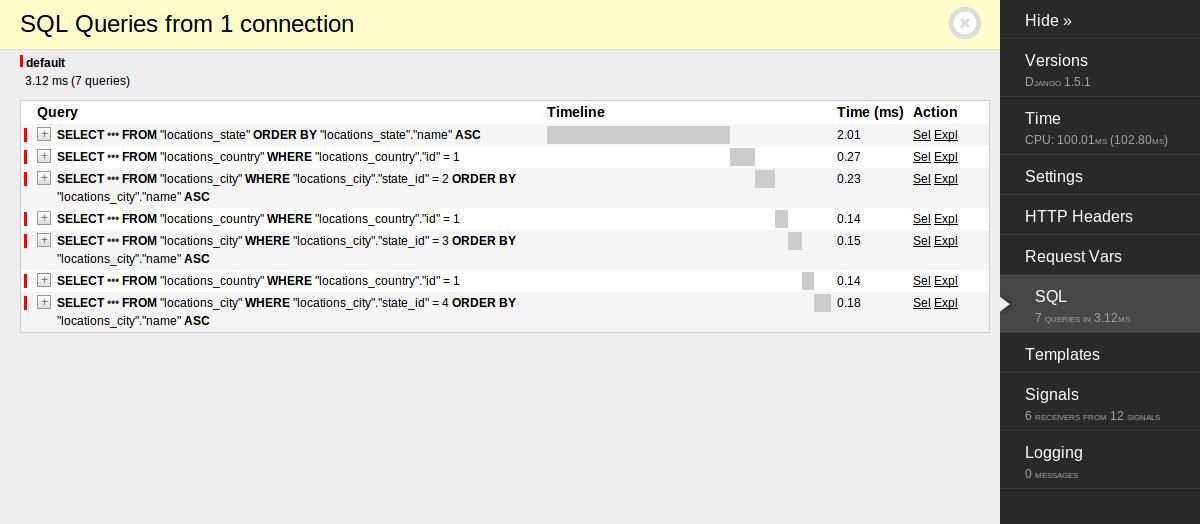
现在就有两个有趣的问题了,这是每个Django ORM方案都要面对的问题。
#p#
select_related
states = State.objects.select_related('country').all()
- 1.
select_related通过在查询主要对象(这里是州state)和其他对象(这里是国家country)之间的SQL做手脚起作用。这样就可以省去为每个州都查一次国家。假如一次数据库往返(网络中转->运行->返回)用时20ms,加起来的话共有N*20ms。如果N足够大,这样做挺费时的。
下面是新的检索州的查询:
SELECT ... FROM "locations_state"
INNER JOIN "locations_country" ON
("locations_state"."country_id" = "locations_country"."id")
ORDER BY "locations_state"."name" ASC
...
- 1.
- 2.
- 3.
- 4.
- 5.
用上面这个查询取代旧的,能省去用来找国家的二级查询。然而,这种解决有一个潜在的缺点,即反复的返回同一个国家对象,从而不得不一次又一次的将这一行传给ORM代码,生成大量重复的对象。等下我们还会再说说这个。
在继续往下之前得说一下,在Django ORM中,如果关系中的一方有多个对象,select_related是没用的。它能用来为一个州抓取对应的国家,但如果调用时添上“市”,它什么都不干。其他ORM框架(如Hibernate)没有这种限制,但要用类似功能时得特别小心,这类框架会在join的时候为二级对象重复生成一级对象,然后很快就会失控,ORM滞在那里不停的处理大量的数据或结果行。
综上所述,select_related的最好是在取单独一个对象、同时又想抓取到关联的(一个)对象时用。这样只有一次数据库往返,不会引入大量重复数据,这在Django ORM只有一对一关系时都适用。
prefetch_related
states = State.objects.prefetch_related('country', 'cities').all()
- 1.
相反地, prefetch_related 的功能是收集关联对象的全部id值,一次性批量获取到它们,然后透明的附到相应的对象。这种方式最好的一个地方是能用在一对多关系中,比如本例中的州跟市。
下面是这种方式生成的SQL:
SELECT ... FROM "locations_state" ORDER BY "locations_state"."name" ASC
SELECT ... FROM "locations_country" WHERE "locations_country"."id" IN (1)
SELECT ... FROM "locations_city"
WHERE "locations_city"."state_id" IN (1, 2, 3)
ORDER BY "locations_city"."name" ASC
- 1.
- 2.
- 3.
- 4.
- 5.
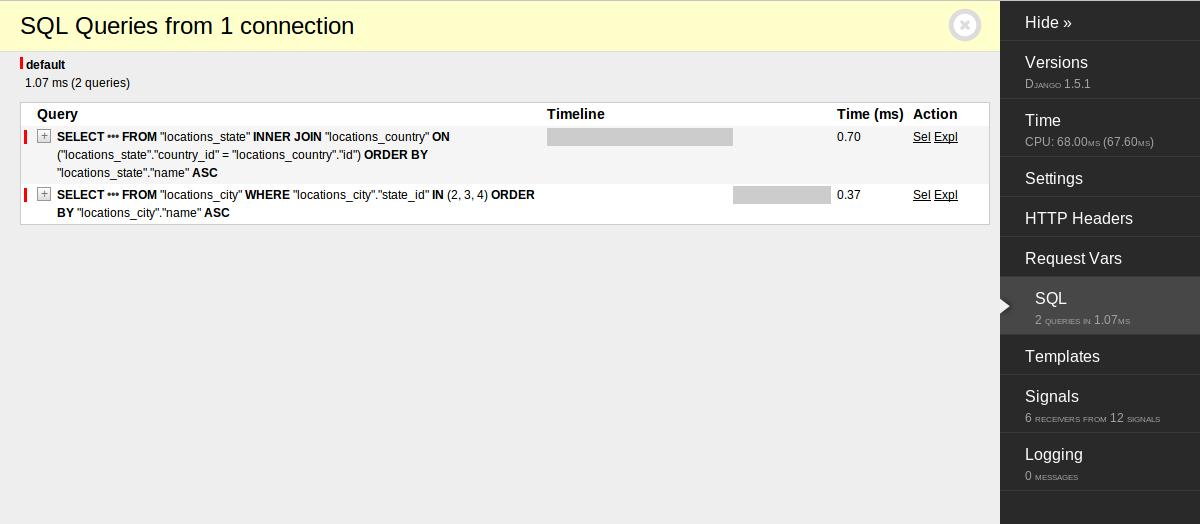
这样2N+1就变成3了。把N扔掉是个大进步。3 * 20ms总是会比(2 * 50 + 1) * 20ms 小,甚至比用select_related时的 (50 + 1) * 20ms也小。
上面这个例子对国家跟市都采用了prefetch。前面说过这里的州都属同一国家,用select_related获得州记录时,这意味着要取到并处理这一国家记录N次。相反,用prefetch_related只要取一次。而这样会引入一次额外的数据库往返,有没有可能综合两种方式,你得在你的机器及数据上试试。然而,在本例中同时用select_related 和 prefetch_related可以将时间降到2 * 20ms,这可能会比分3次查询要快,但也有很多潜在因素要考虑。
states = State.objects.select_related('country') \
.prefetch_related('cities').all()
- 1.
- 2.
能支持多深的关系?
要跨多个级别时怎么办?select_related 和prefetch_related都可以通过双下划线遍历关系对象。用这个功能时,中间对象也会包括在内。这很有用,但在更复杂的对象模型中有点难用。
# only works when there's a single object at each step
city = City.objects.select_related('state__country').all()[0]
# 1 query, no further db queries
print('{0} - {1} - {2}'.format(city.name, city.state.name,
city.state.country.name)
# works for both single and multiple object relationships
countries = Country.objects.prefetch_related('states__cities')
# 3 queries, no further db queries
for country in countries:
for state in country.states:
for city in state.cities:
print('{0} - {1} - {2}'.format(city.name, city.state.name,
city.state.country.name)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
prefetch_related用在原生查询
最后一点。上周的 efficiently querying for nearby things 一文中,为了实现查找最近的经度/纬度点,我写了一条复杂的SQL。其实最好的方法是写一条原生的sql查询 。而原生查询不支持prefetch_related,挺可惜的。但有一个变通的方法,即可以直接用Django实现prefetch_related功能的prefetch_related_objects。
from django.db.models.query import prefetch_related_objects
# prefetch_related_objects requires a list, it won't work on a QuerySet so
# we need to convert with list()
cities = list(City.objects.raw('<sql-query-for-nearby-cities>'))
prefetch_related_objects(cities, ('state__country',))
# 3 queries, no further db queries
for city in cities:
print('{0} - {1} - {2}'.format(city.name, city.state.name,
city.state.country.name)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
这多牛呀!
英文原文:High Performance Web: Reducing Database Round Trips
译文链接:http://www.oschina.net/translate/high-performance-web-reducing-database-round-trips