













这是最近发生的又一起内存相关的事件了。这个案例是从一个最近的客户报告中提取出来,一个异常运行的应用在其产品中反复报告内存耗尽。
这个症状是由我们的一个实验性功能发现,它主要用来监测某一类数据结构的使用情况。它提供了一个信号探针,结果会指向问题源代码的某一位置。为了保护客户的隐私,我们人为重建了该例子并保持它同原真实场景在技术层面的一致性。你可以免费在此处下载到源码。
故事开始于一组从外界源加载进来的对象。同外部的信息交互是基于XML的接口,这本身并没什么大不了的,但事实上“基于XML的格式进行通讯”的实现细节被分散到了系统的每一个角落。 传入系统的文档是首先被转换成XMLBean实例,然后在整个系统范围内被使用,这中做法听起来有点傻。
整个问题中最核心的部分是一个延迟加载的缓冲方案。缓存的对象是“Person”的实例:
// Imports and methods removed to improve readability
public class Person {
private String id;
private Date dateOfBirth;
private String forename;
private String surname;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
你也许会说这才能消耗多少内存呢。但当我们揭开进一步的细节时,发现事情就变了味了。表面上根据设计,声称实现只用到的诸如上文提到的那样一些简单的类,但真实的情形是使用了基于模型生成的数据结构。使用的模型是诸如下面的这个简化的XSD片段。
<xs:schema targetNamespace="http://plumbr.eu"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<xs:element name="person">
<xs:complexType>
<xs:sequence>
<xs:element name="id" type="xs:string"/>
<xs:element name="dateOfBirth" type="xs:dateTime"/>
<xs:element name="forename" type="xs:string"/>
<xs:element name="surname" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
使用XMLBeans,开发者生成了该模型,并在真实的场景中使用。现在我们回到开始的这个缓存的方案上来,假设它设计初衷是为了支持最多1.3M Person类的实例,而我们实际却要塞进去同等数量的大家伙,这从根上就注定了失败。
跑一组测试用例后,发现1.3M个基于XMLBean的生成的实例需要消耗大概1.5GB的堆空间。我们当时想这肯定可以做的更好。
第一个改进是显而易见的,外部同系统内部集成的实现细节是不应该把影响传递给系统的每一个角落的。所以我们把缓存改成了使用简单的 java.util.HashMap<Long, Person>。ID是键,Person是值。我们发现内存的消耗立即降低到了214MB。但这还不能令我们满意。
由于Map中的键是一个数,我们有十足的理由使用Trove Collections来进一步降低它的内存消耗。这在实现上的改动很快,我们只需把 HashMap 改成 TLongObjectHashMap<Person> ,堆的消耗进一步降低到了143MB。
活干到这个程度我们已经可以收工了,但是工程师的好奇心驱使我们要更进一步。不由自主的我们发现了系统的数据存在着大量的重复信息。例如Date Of Birth其实已经在ID中编码了,所以Date Of Birth可以直接从ID中得到,而不必使用额外的空间去它。
经过改良,Person类现在变成了这个样子:
// Imports and methods removed to improve readability
public class Person {
private String id;
private String forename;
private String surname;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
重新跑一边测试证实我们的改进的确有效,堆消耗降低到了93MB。但是我们还未满足。
该应用在64位的机器上使用老的JDK6。默认情况下,这么做不能压缩普通对象的指针的。通过参数”-XX:UseCompressedOops“切换到压缩模式使我们获得了额外的收获,现在我们的内存消耗降低到了73MB。
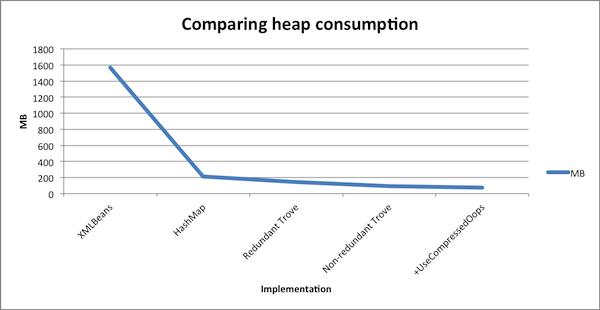
当然,我们还能走的更远。比如基于键值建立B-tree,但这已经开始影响到了代码的可读性,所以我们决定到此为止。降低21.5倍的堆内存应该已经是一个足够好的结果了。
让我们在重复一下学到了什么
别把同外部模块的整合影响到系统的每一个角落
冗余的数据可能带来开销。在可能的情况下尽量消除它
基本数据类型是你最经常打交道的朋友,务必知道些关于它们的工具,如果还没玩过Trove请立刻开始吧
JVM自带的优化技术不可忽视
如果你对这个实验很好奇,请在此处下载相关的代码。使用到的的测量工具和其具体描述可以在这篇博文找到。















