在引入线程池之前,MySQL支持的线程处理方式(thread_handling参数控制)有no-threads和one-thread-per-connection两种方式,no-threads方式是指任一时刻最多只有一个连接可以连接到server,一般用于实验性质。 one-thread-per-connection是指针对每个连接创建一个线程来处理这个连接的所有请求,直到连接断开,线程 结束。是thread_handling的默认方式。
one-thread-per-connection存在的问题就是需要为每个连接创建一个新的thread,当并发连接数达到一定 程度,性能会有明显下降,因为过多的线程会导致频繁的上下文切换,CPU cache命中率降低和锁的竞争 更加激烈。
解决one-thread-per-connection的方法就是降低线程数,这样就需要多个连接共用线程,这便引入了线程 池的概念。线程池中的线程是针对请求的,而不是针对连接的,也就是说几个连接可能使用相同的线程处理 各自的请求。
MariaDB在5.5引入了一个动态的线程池方案,可以根据当前请求的并发情况自动增加或减少线程数,还好 MariaDB完全开源,本文结合MariaDB的代码来介绍下thread pool的实现。这里使用的MariaDB 10.0的 代码树。
1 相关参数
MySQL的参数都写在sys_vars.cc文件下。
- static Sys_var_uint Sys_threadpool_idle_thread_timeout(
- "thread_pool_idle_timeout",
- "Timeout in seconds for an idle thread in the thread pool."
- "Worker thread will be shut down after timeout",
- GLOBAL_VAR(threadpool_idle_timeout), CMD_LINE(REQUIRED_ARG),
- VALID_RANGE(1, UINT_MAX), DEFAULT(60), BLOCK_SIZE(1)
- );
- static Sys_var_uint Sys_threadpool_oversubscribe(
- "thread_pool_oversubscribe",
- "How many additional active worker threads in a group are allowed.",
- GLOBAL_VAR(threadpool_oversubscribe), CMD_LINE(REQUIRED_ARG),
- VALID_RANGE(1, 1000), DEFAULT(3), BLOCK_SIZE(1)
- );
- static Sys_var_uint Sys_threadpool_size(
- "thread_pool_size",
- "Number of thread groups in the pool. "
- "This parameter is roughly equivalent to maximum number of concurrently "
- "executing threads (threads in a waiting state do not count as executing).",
- GLOBAL_VAR(threadpool_size), CMD_LINE(REQUIRED_ARG),
- VALID_RANGE(1, MAX_THREAD_GROUPS), DEFAULT(my_getncpus()), BLOCK_SIZE(1),
- NO_MUTEX_GUARD, NOT_IN_BINLOG, ON_CHECK(0),
- ON_UPDATE(fix_threadpool_size)
- );
- static Sys_var_uint Sys_threadpool_stall_limit(
- "thread_pool_stall_limit",
- "Maximum query execution time in milliseconds,"
- "before an executing non-yielding thread is considered stalled."
- "If a worker thread is stalled, additional worker thread "
- "may be created to handle remaining clients.",
- GLOBAL_VAR(threadpool_stall_limit), CMD_LINE(REQUIRED_ARG),
- VALID_RANGE(10, UINT_MAX), DEFAULT(500), BLOCK_SIZE(1),
- NO_MUTEX_GUARD, NOT_IN_BINLOG, ON_CHECK(0),
- ON_UPDATE(fix_threadpool_stall_limit)
- );
这几个参数都有相应的描述,这里再稍微具体介绍一下。
thread_pool_size: 线程池的分组(group)个数。MariaDB的线程池并不是说一整个 大池子,而是分成了不同的group,而且是按照到来connection的顺序进行分组的,如 第一个connection分配到group[0],那么第二个connection就分配到group[1],是一种 Round Robin的轮询分配方式。默认值是CPU core个数。
thread_pool_idle_timeout: 线程最大空闲时间,如果某个线程空闲的时间大于这个 参数,则线程退出。
thread_pool_stall_limit: 监控间隔时间,thread pool有个监控线程,每隔这个时间, 会检查每个group的线程可用数等状态,然后进行相应的处理,如wake up或者create thread。
thread_pool_oversubscribe: 允许的每个group上的活跃的线程数,注意这并不是每个group上的 最大线程数,而只是可以处理请求的线程数。
2 thread handling设置
thread pool模式其实是新增了一种thread_handling的方式,即在配置文件中设置:
- [mysqld]
- thread_handling=pool-of-threads.
- ....
MySQL内部是有一个scheduler_functions结构体,不论thread_handling是哪种方式,都是通过设置这个 结构体中的函数来进行不同的调度。
- /** scheduler_functions结构体 */
- struct scheduler_functions
- {
- uint max_threads, *connection_count;
- ulong *max_connections;
- bool (*init)(void);
- bool (*init_new_connection_thread)(void);
- void (*add_connection)(THD *thd);
- void (*thd_wait_begin)(THD *thd, int wait_type);
- void (*thd_wait_end)(THD *thd);
- void (*post_kill_notification)(THD *thd);
- bool (*end_thread)(THD *thd, bool cache_thread);
- void (*end)(void);
- };
- static int get_options(int *argc_ptr, char ***argv_ptr)
- {
- ...
- /** 根据thread_handling选项的设置,选择不同的处理方式*/
- if (thread_handling <= SCHEDULER_ONE_THREAD_PER_CONNECTION)
- /**one thread per connection 方式 */
- one_thread_per_connection_scheduler(thread_scheduler, &max_connections,
- &connection_count);
- else if (thread_handling == SCHEDULER_NO_THREADS)
- /** no thread 方式 */
- one_thread_scheduler(thread_scheduler);
- else
- /** thread pool 方式 */
- pool_of_threads_scheduler(thread_scheduler, &max_connections,
- &connection_count);
- ...
- }
- static scheduler_functions tp_scheduler_functions=
- {
- 0, // max_threads
- NULL,
- NULL,
- tp_init, // init
- NULL, // init_new_connection_thread
- tp_add_connection, // add_connection
- tp_wait_begin, // thd_wait_begin
- tp_wait_end, // thd_wait_end
- post_kill_notification, // post_kill_notification
- NULL, // end_thread
- tp_end // end
- };
- void pool_of_threads_scheduler(struct scheduler_functions *func,
- ulong *arg_max_connections,
- uint *arg_connection_count)
- {
- /** 设置scheduler_functions结构体为tp_scheduler_functions */
- *func = tp_scheduler_functions;
- func->max_threads= threadpool_max_threads;
- func->max_connections= arg_max_connections;
- func->connection_count= arg_connection_count;
- scheduler_init();
- }
上面可以看到设置了thread_scheduler的处理函数为tp_scheduler_functions,即 为thread pool方式,这种方式对应的初始函数为tp_init, 创建新连接的函数为 tp_add_connection,等待开始函数为tp_wait_begin,等待结束函数为tp_wait_end. 这里说明下等待函数的意义,等待函数一般是在等待磁盘I/O,等待锁资源,SLEEP,或者等待 网络消息的时候,调用wait_begin,在等待结束后调用wait_end,那么为什么要等待的时候 调用等待函数呢?这个在后面进行介绍。
上面讲的其实和thread pool关系不是很大,下面开始thread pool流程的介绍。thread pool涉及 到的源码在emphsql/threadpool_common.cc和emphsql/threadpool_unix.cc, 对于windows而言,还有emphsql/threadpool_win.cc.
3 线程池初始化——tp_init
- >tp_init
- | >thread_group_init
- | >start_timer
tp_init非常简单,首先是调用了thread_group_init进行组的初始化, 然后调用的start_timer开启了监控线程timer_thread。 至此为止,thread pool里面只有一个监控线程启动,而没有任何工作线程, 直到有新的连接到来。
4 添加新连接——tp_add_connection
- void tp_add_connection(THD *thd)
- {
- DBUG_ENTER("tp_add_connection");
- threads.append(thd);
- mysql_mutex_unlock(&LOCK_thread_count);
- connection_t *connection= alloc_connection(thd);
- if (connection)
- {
- thd->event_scheduler.data= connection;
- /* Assign connection to a group. */
- thread_group_t *group=
- &all_groups[thd->thread_id%group_count];
- connection->thread_group=group;
- mysql_mutex_lock(&group->mutex);
- group->connection_count++;
- mysql_mutex_unlock(&group->mutex);
- /*
- Add connection to the work queue.Actual logon
- will be done by a worker thread.
- */
- queue_put(group, connection);
- }
- else
- {
- /* Allocation failed */
- threadpool_remove_connection(thd);
- }
- DBUG_VOID_RETURN;
- }
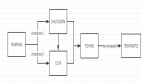
但server的主监听线程监听到有客户端的connect时,会调用tp_add_connection函数进行处理。 首先根据thread_id对group_count取模,找到其所属的group,然后调用queue_put将此connection 放入到group中的queue中。这里涉及到两个新的结构体,connection_t和thread_group_t。
- struct connection_t
- {
- THD *thd;
- thread_group_t *thread_group;
- connection_t *next_in_queue;
- connection_t **prev_in_queue;
- ulonglong abs_wait_timeout; //等待超时时间
- bool logged_in; //是否进行了登录验证
- bool bound_to_poll_descriptor; //是否添加到了epoll进行监听
- bool waiting; //是否在等待状态,如I/O, sleep
- };
- struct thread_group_t
- {
- mysql_mutex_t mutex;
- connection_queue_t queue; //connection请求链表
- worker_list_t waiting_threads; //group中正在等待被唤醒的thread
- worker_thread_t *listener; //当前group中用于监听的线程
- pthread_attr_t *pthread_attr;
- int pollfd; //epoll 文件描述符,用于绑定group中的所有连接
- int thread_count; //线程数
- int active_thread_count;//活跃线程数
- int connection_count; //连接数
- /* Stats for the deadlock detection timer routine.*/
- int io_event_count; //epoll产生的事件数
- int queue_event_count; //工作线程消化的事件数
- ulonglong last_thread_creation_time;
- int shutdown_pipe[2];
- bool shutdown;
- bool stalled; // 工作线程是否处于停滞状态
- } MY_ALIGNED(512);
上面对这些参数进行了说明,理解这些参数的意义,才能了解这个动态thread pool的管理机制, 因为每个参数都会影响到thread pool的增长或收缩。
介绍完结构体,继续回到新的连接到来,这时会调用queue_put函数,将此connection放到 group的队列queue中。
- static void queue_put(thread_group_t *thread_group, connection_t *connection)
- {
- DBUG_ENTER("queue_put");
- mysql_mutex_lock(&thread_group->mutex);
- thread_group->queue.push_back(connection);
- if (thread_group->active_thread_count == 0)
- wake_or_create_thread(thread_group);
- mysql_mutex_unlock(&thread_group->mutex);
- DBUG_VOID_RETURN;
- }
注意,这时候有个active_thread_count的判断,如果没有活跃的线程,那么就无法处理 这个新到的请求啊,这时就需要调用wake_or_create_thread,这个函数首先会尝试唤醒group 等待线程链表waiting_threads中的线程,如果没有等待中的线程,则需要创建一个线程。 至此,新到的connection被挂到了group的queue上,这样一个连接算是add进队列了,那么如何 处理这个连接呢?我们继续往下看。
5 工作线程——worker_main
由于是第一个连接到来,那么肯定没有waiting_threads,此时会调用create_worker 函数创建一个工作线程。我们直接来看下工作线程。
- static void *worker_main(void *param)
- {
- ...
- DBUG_ENTER("worker_main");
- thread_group_t *thread_group = (thread_group_t *)param;
- /* Run event loop */
- for(;;)
- {
- connection_t *connection;
- struct timespec ts;
- set_timespec(ts,threadpool_idle_timeout);
- connection = get_event(&this_thread, thread_group, &ts);
- if (!connection)
- break;
- this_thread.event_count++;
- handle_event(connection);
- }
- ....
- my_thread_end();
- return NULL;
- }
上面是整个工作线程的逻辑,可以看到是一个循环,get_event用来获取新的需要处理的 connection,然后调用handle_event进行处理相应的connection。one thread per connection 中每个线程也是一个循环体,这两者之间的区别就是,thread pool的循环等待的是一个可用的event, 并不局限于某个固定的connection的event,而one thread per connection的循环等待是等待固定的 connection上的event,这就是两者最大的区别。
6 事件获取——get_event
工作线程通过get_event获取需要处理的connection,
- connection_t *get_event(worker_thread_t *current_thread,
- thread_group_t *thread_group, struct timespec *abstime)
- {
- ...
- for(;;)
- {
- ...
- /** 从QUEUE中获取connection */
- connection = queue_get(thread_group);
- if(connection) {
- fprintf(stderr, "Thread %x get a new connection.\n", (unsigned int)pthread_self());
- break;
- }
- ...
- /**监听epoll */
- if(!thread_group->listener)
- {
- thread_group->listener= current_thread;
- thread_group->active_thread_count--;
- mysql_mutex_unlock(&thread_group->mutex);
- fprintf(stderr, "Thread %x waiting for a new event.\n", (unsigned int)pthread_self());
- connection = listener(current_thread, thread_group);
- fprintf(stderr, "Thread %x get a new event for connection %p.\n",
- (unsigned int)pthread_self(), connection);
- mysql_mutex_lock(&thread_group->mutex);
- thread_group->active_thread_count++;
- /* There is no listener anymore, it just returned. */
- thread_group->listener= NULL;
- break;
- }
- ...
- }
这个get_event的函数逻辑稍微有点多,这里只抽取了获取事件的两个点, 我们接着按照第一个连接到来是的情形进行说明, 第一个连接到来,queue中有了一个connection,这是get_event便会从queue中获取到一个 connection,返回给worker_main线程。worker_main接着调用handle_event进行事件处理。
每个新的connection连接到服务器后,其socket会绑定到group的epoll中,所以,如果queue中 没有connection,需要从epool中获取,每个group的所有连接的socket都绑定在group的epool 中,所以任何一个时刻,最多只有一个线程能够监听epoll,如果epoll监听到有event的话,也会返回 相应的connection,然后再调用handle_event进行处理。
7 事件处理——handle_event
handle_event的逻辑比较简单,就是根据connection_t上是否登录过,进行分支,如果没 登录过,说明是新到的连接,则进行验证,否则直接进行请求处理。
- static void handle_event(connection_t *connection)
- {
- DBUG_ENTER("handle_event");
- int err;
- if (!connection->logged_in) //处理登录
- {
- err= threadpool_add_connection(connection->thd);
- connection->logged_in= true;
- }
- else //处理请求
- {
- err= threadpool_process_request(connection->thd);
- }
- if(err)
- goto end;
- set_wait_timeout(connection);
- /** 设置socket到epoll的监听 */
- err= start_io(connection);
- end:
- if (err)
- connection_abort(connection);
- DBUG_VOID_RETURN;
- }
- static int start_io(connection_t *connection)
- {
- int fd = mysql_socket_getfd(connection->thd->net.vio->mysql_socket);
- ...
- /* 绑定到epoll *。
- if (!connection->bound_to_poll_descriptor)
- {
- connection->bound_to_poll_descriptor= true;
- return io_poll_associate_fd(group->pollfd, fd, connection);
- }
- return io_poll_start_read(group->pollfd, fd, connection);
- }
注意,在handle_event之后,会调用start_io,这个函数很重要,这个函数会将新 到的connection的socket绑定到group的epoll上进行监听。
8 线程等待
当group中的线程没有任务执行时,所有线程都会在get_event处等待,但是有两种等待方式, 一种是在epoll上等待事件,每个group中只有一个线程会做这个事情,且这个会一直等待,直到有新 的事件到来。另一种就是等待一定的时间, 即参数thread_pool_idle_time这个时间,如果超过了这个时间,那么当前的线程的get_event就会 返回空,然后worker_main线程就会退出。如果在线程等待的过程被唤醒的话,那么就会继续在 get_event中进行循环,等待新的事件。
9 唤醒等待线程
有两种方式会唤醒等待的线程,一种是监控线程timer_thread,另一种就是一些active的线程碰到 需要等待的时候,会调用tp_wait_begin,这个函数如果判断当前没有active的thread且没有thread监听 epoll,则会调用wake_or_create_thread。
监控线程timer_thread用于定期监控group中的thread使用情况,具体的检查函数是check_stall.
- void check_stall(thread_group_t *thread_group)
- {
- ...
- /** 如果没有线程监听epoll且自上次检查到现在没有新的event事件产生,说明所有的
- 活跃线程都在 忙于执行长任务,则需要唤醒或创建工作线程 */
- if (!thread_group->listener && !thread_group->io_event_count)
- {
- wake_or_create_thread(thread_group);
- mysql_mutex_unlock(&thread_group->mutex);
- return;
- }
- /* Reset io event count */
- thread_group->io_event_count= 0;
- /** 如果队列queue中有请求,且自上次检查到现在queue中的请求没有被消化,
- 则说明所有活跃线程忙于执行长任务,需要唤醒或创建工作线程*/
- if (!thread_group->queue.is_empty() && !thread_group->queue_event_count)
- {
- thread_group->stalled= true;
- wake_or_create_thread(thread_group);
- }
- /* Reset queue event count */
- thread_group->queue_event_count= 0;
- mysql_mutex_unlock(&thread_group->mutex);
- }
10 小结
MariaDB的thread pool的实现相对比较简单,总体上就是将group中所有的connection的socket挂在 group的epoll_fd上进行事件监听,监听到的事件或被当前线程执行,或者被push到group的queue上 被其他线程执行。
监控线程timer_thread定期的根据需要去唤醒等待线程或创建新的线程,来达到动态增加的thread的 目的。而thread的收缩则是通过线程等待事件超时来完成的。
btw,在跟踪代码的过程中,也发现了使用thread pool时导致server crash的情况,提交了个 bug给MariaDB,发现当天就有回复, 并立刻修复push到source tree上了,看来MariaDB的团队反映够迅速的,赞一个。
原文链接:http://www.cnblogs.com/nocode/archive/2013/05/25/3098317.html