













前言
文件系统是一套实现了数据的存储、分级组织、访问和获取等操作的抽象数据类型(Abstract data type)(From Wikipedia)。
现在的文件系统多种多样,不管是接口、架构、部署都有巨大差异,本文试图总结一下本地文件系统和分布式文件系统以及它们的特点和技术点。
我试图用一个极其抽象的图来描绘本地文件系统和分布式文件系统。(PS: 好吧,结果就成了下面这个基本没啥意义的图。。。。)
专题推荐:回味那些经典的分布式文件系统
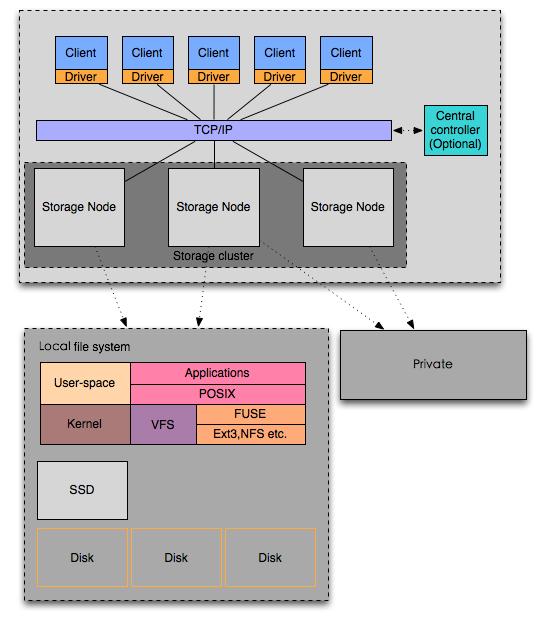
本地文件系统
本地文件系统主要是指Ext2,Ext3,Btrfs,XFS这类(很难概括,只好举例子),它们通常提供以下功能:
- 扩展性:随着系统容量的增加保持性能,不随容量变化而导致性能震荡。比如一个目录下的海量文件,在EXT2/3中由于目录设计问题会导致较大的性能问题。再比如EXT2/3中的Metadata的占用和inode的划分可能会导致空间的浪费。
- 数据一致性
- Checksum: Checksum与对应的数据块分开放置,避免silent corruption
- COW事务: COW事务参考文件系统特性 – COW事务
- Log: Log被一些文件系统用作WAL模式来加快写操作,并且保证写操作的原子性
- 多设备管理:传统上Linux往往使用LVM进行多设备的管理,现代文件系统往往增加对多设备的支持。如ZFS和Btrfs会有存储池模型对应LVM的逻辑卷组,文件系统会对底层的多设备进行并行的访问。
- 快照和克隆:采用COW事务模型的文件系统通常具有这个特性
- 软件RAID支持:现代文件系统通过对多设备的管理可以很好的支持软件RAID,如Btrfs对Metadata进行RAID1的默认保护
- 针对SSD的优化: 除了SSD对于随机读这一特性的优化外,还有对SSD擦除操作的优化。另外,SSD在使用容量接近100%时会导致极差的写入性能,文件系统也可以对SSD的分配策略和重平衡进行一定的优化。
- 压缩和加密: 现在的IO速度远远跟不上CPU的发展,因此对磁盘文件进行压缩读写是个很好的选择,现代文件系统往往支持多种压缩格式,而且可以支持整个文件系统的加密或者某个文件和目录的加密
- 去重: 文件系统系统去重是个大话题,主要是计算块的checksum方法或者客户端计算文件的hash来决定是否是一个新文件。具体参考Deduplication。#p#
分布式文件系统
分布式文件系统的架构和实现有非常大的差异,如NFS这种传统的基于存储服务器的网络文件系统,基于SAN的GPFS,然后现在的集群式架构,比如HDFS这种有中心的分布式,如GlusterFS这种无中心分布式,再如Ceph这种部分在内核态部分在用户态等等。
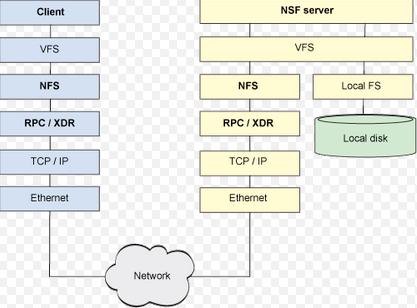
NFS
- 1.
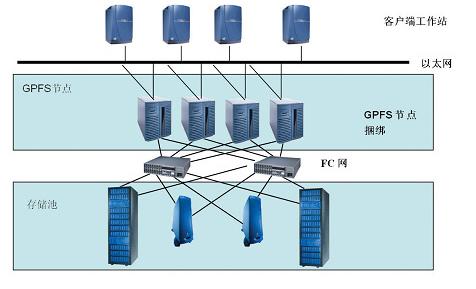
GPFS
- 1.
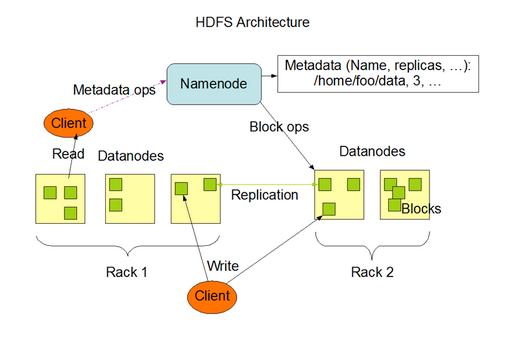
HDFS
- 1.
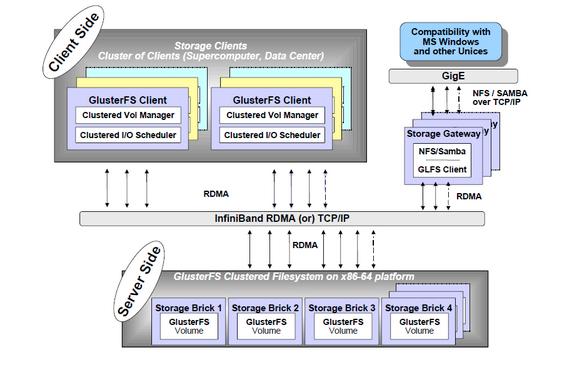
GlusterFS
- 1.
由于架构上的差异和本身文件系统的设计目标,通常分布式文件系统可以根据接口类型分成块存储、对象存储和文件存储。如Ceph具备块存储(Experiment)、文件存储和对象存储的能力,GlusterFS支持对象存储和文件存储的能力。而MogileFS只能作为对象存储并且通过key来访问。
- 扩展能力: 毫无疑问,扩展能力是一个分布式文件系统最重要的特点。分布式文件系统中元数据管理一般是扩展的重要问题,GFS采用元数据中心化管理,然后通过Client暂存数据分布来减小元数据的访问压力。GlusterFS采用无中心化管理,在客户端采用一定的算法来对数据进行定位和获取。
- 高可用性: 在分布式文件系统中,高可用性包含两层,一是整个文件系统的可用性,二是数据的完整和一致性。整个文件系统的可用性是分布式系统的设计问题,类似于NOSQL集群的设计,比如有中心分布式系统的Master服务器,网络分区等等。数据完整性则通过文件的镜像和文件自动修复等手段来解决,另外,部分文件系统如GlusterFS可以依赖底层的本地文件系统提供一定支持。
- 协议和接口: 分布式文件系统提供给应用的接口多种多样,Http RestFul接口、NFS接口、Ftp等等POSIX标准协议,另外通常会有自己的专用接口。
- 弹性存储: 可以根据业务需要灵活地增加或缩减数据存储以及增删存储池中的资源,而不需要中断系统运行。弹性存储的最大挑战是减小或增加资源时的数据震荡问题。
- 压缩、加密、去重、缓存和存储配额: 这些功能的提供往往考验一个分布式文件系统是否具有可扩展性,一个分布式文件系统如果能方便的进行功能的添加而不影响总体的性能,那么这个文件系统就是良好的设计。这点GlusterFS就做的非常好,它利用类似GNU/Hurd的堆栈式设计,可以让额外的此类功能模块非常方便的增加。
















