最近的新闻中我们得知雅虎11亿美元收购了Tumblr: Yahoo bought Tumblr for $1.1 billion. 你也许会发现Instagram也被Facebook重金收购的介绍. 这是一个巧合吗?这就由你来判断吧。
为什么雅虎会收购Tumblr? 这场交易中的商业价值我可能无法判断,但是如果你对Tumblr的技术方面有所了解,你一定会为Tumblr竖起大拇指. 为什么这么说呢,请接着读... Tumblr每月页面浏览量超过150亿次,已经成为火爆的博客社区。用户也许喜欢它的简约、漂亮,并且它对用户体验强烈的关注,或是友好而忙碌的沟通方式,总之,它深得人们的喜爱。
每月超过30%的增长当然不可能没有挑战,其中可靠性问题尤为艰巨。每天5亿次浏览量,峰值每秒4万次请求,每天3TB新的数据存储,并运行于超过1000台服务器上,所有这些帮助Tumblr实现巨大的经营规模。
创业公司迈向成功,都要迈过危险的迅速发展期这道门槛。寻找人才,不断改造基础架构,维护旧的架构,同时要面对逐月大增的流量,而且曾经只有4位工程师。这意味着必须艰难地选择应该做什么,不该做什么。这就是Tumblr的状况。好在现在已经有20位工程师了,可以有精力解决问题,并开发一些有意思的解决方案。
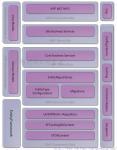
Tumblr最开始是非常典型的LAMP应用。目前正在向分布式服务模型演进,该模型基于Scala、HBase、Redis、Kafka、Finagle,此外还有一个有趣的基于Cell的架构,用于支持Dashboard .现在的重点被放在了解决他们PHP程序中的短期问题,找出问题,并正确的使用服务化去解决他们. Tumblr目前的最大问题是如何改造为一个大规模网站。系统架构正在从LAMP演进为最先进的技术组合,同时团队也要从小的创业型发展为全副武装、随时待命的正规开发团队,不断创造出新的功能和基础设施。下面就是Blake对Tumblr系统架构情况的介绍。
Tumblr网址: http://www.tumblr.com/
统计
- 每天 5 亿页面浏览量
- 每月超过 150亿 页面浏览量
- 约 20 名工程师
- 峰值每秒大约 4 万请求
- 每天有超过 1TB 的数据进入 Hadoop 集群
- 每天有几个 TB 的数据进入 MySQL/HBase/Redis/Memcache
- 每月增长 30%
- 产品环境有大约 1000 个硬件节点
- 平均每个工程师每月处理10亿页面访问
- 每天大约 50GB 的文章,关注者列表更新大约每天 2.7TB
- Dashboard 每秒百万次写,每秒 5w 读
软件
- OS X 用于开发,产品环境用 Linux (CentOS, Scientific)
- Apache
- PHP, Scala, Ruby
- Redis, HBase, MySQL
- Varnish, HA-Proxy, nginx,
- Memcache, Gearman, Kafka, Kestrel, Finagle
- Thrift, HTTP
- Func - 一个安全的、脚本化的远程控制框架和 API
- Git, Capistrano, Puppet, Jenkins
硬件
- 500 台 Web 服务器
- 200 数据库服务器 (大多数是备用池)
- 47 个池
- 30 个分区
- 30 台 memcache 服务器
- 22 台 redis 服务器
- 15 台 varnish 服务器
- 25 个 haproxy 节点
- 8 个 nginx
- 14 个作业队列服务器 (kestrel + gearman)
构架
- 与其他社交网站不同的是,Tumblr有其独特的使用模式。
- 每天有超过5千万篇文章更新,平均每篇文章的跟帖又数以百计。用户一般只有数百个粉丝。这与其他社会化网站里少数用户有几百万粉丝非常不同,使得Tumblr的扩展性极具挑战性。
- 按用户使用时间衡量,Tumblr已经是排名第二的社会化网站。内容的吸引力很强,有很多图片和视频,文章往往不短,一般也不会太长,但允许写得很长。文章内容往往比较深入,用户会花费更长的时间来阅读。
- 用户与其他用户建立联系后,可能会在Dashboard上往回翻几百页逐篇阅读,这与其他网站基本上只是部分信息流不同。
- 用户的数量庞大,用户的平均到达范围更广,用户较频繁的发帖,这些都意味着有巨量的更新需要处理。
- Tumblr目前运行在一个托管数据中心中,已在考虑地域上的分布式构架。
- Tumblr平台由两个组件构成:公共Tumblelogs和Dashboard
- 公共Tumblelogs与博客类似,并非动态,易于缓存
- Dashboard是类似于Twitter的时间轴,用户由此可以看到自己关注的所有用户的实时更新。
- 与博客的扩展性不同,缓存作用不大,因为每次请求都不同,尤其是活跃的关注者。
- 而且需要实时而且一致,文章每天仅更新50GB,跟帖每天更新2.7TB,所有的多媒体数据都存储在S3上面。
- 大多数用户以Tumblr作为内容浏览工具,每天浏览超过5亿个页面,70%的浏览来自Dashboard。
- Dashboard的可用性已经不错,但Tumblelog一直不够好,因为基础设施是老的,而且很难迁移。由于人手不足,一时半会儿还顾不上。
老的Tumblr构架
- Tumblr最开始是托管在Rackspace上的,每个自定义域名的博客都有一个A记录。当2007年Rackspace无法满足其发展速度不得不迁移时,大量的用户都需要同时迁移。所以他们不得不将自定义域名保留在Rackspace,然后再使用HAProxy和Varnish路由到新的数据中心。类似这样的遗留问题很多。
- 开始的架构演进是典型的LAMP路线
- 最初用PHP开发,几乎所有程序员都用PHP
- 最初是三台服务器:一台Web,一台数据库,一台PHP
- 为了扩展,开始使用memcache,然后引入前端cache,然后在cache前再加HAProxy,然后是非常奏效的MySQL sharding
- 采用“在单台服务器上榨出一切”的方式。过去一年已经用C开发了两个后端服务:ID generator和Staircar(用Redis进行Dashboard通知)
- Dashboard采用了“扩散-收集”方式。当用户访问Dashboard时将显示事件,来自所关注的用户的事件是通过拉然后显示的。这样支撑了6个月。由于数据是按时间排序的,因此sharding模式不太管用。
新的构架
- 由于招人和开发速度等原因,改为以JVM为中心。
- 目标是将一切从PHP应用改为服务,使应用变成请求鉴别、呈现等诸多服务之上的薄层。
- 选择了Scala 和 Finagle
- 在团队内部有很多人具备Ruby和PHP经验,所以Scala很有吸引力。
- Finagle是选择Scala的重要因素之一。这个来自Twitter的库可以解决大多数分布式问题,比如分布式跟踪、服务发现、服务注册等。
- 转到JVM上之后,Finagle提供了团队所需的所有基本功能(Thrift, ZooKeeper等),无需再开发许多网络代码,另外,团队成员认识该项目的一些开发者。
- Foursquare和Twitter都在用Finagle,Meetup也在用Scala。
- 应用接口与Thrift类似,性能极佳。
- 团队本来很喜欢Netty,但不想用Java,Scala是不错的选择。
- 选择Finagle是因为它很酷,还认识几个开发者。
- 之所以没有选择Node.js,是因为以JVM为基础更容易扩展。Node的发展为时尚短,缺乏标准、最佳实践以及大量久经测试的代码。而用Scala的话,可以使用所有Java代码。虽然其中并没有多少可扩展的东西,也无法解决5毫秒响应时间、49秒HA、4万每秒请求甚至有时每秒40万次请求的问题。但是,Java的生态链要大得多,有很多资源可以利用。
- 内部服务从C/libevent为基础正在转向Scala/Finagle为基础。
- 开始采用新的NoSQL存储方案如HBase和Redis。但大量数据仍然存储在大量分区的MySQL架构中,并没有用HBase代替MySQL。
- HBase主要支持短地址生产程序(数以十亿计)还有历史数据和分析,非常结实。此外,HBase也用于高写入需求场景,比如Dashboard刷新时一秒上百万的写入。之所以还没有替换HBase,是因为不能冒业务上风险,目前还是依靠人来负责更保险,先在一些小的、不那么关键的项目中应用,以获得经验。
- MySQL和时间序列数据sharding(分片)的问题在于,总有一个分片太热。另外,由于要在slave上插入并发,也会遇到读复制延迟问题。
- 此外,还开发了一个公用服务框架:
- 花了很多时间解决分布式系统管理这个运维问题。
- 为服务开发了一种Rails scaffolding,内部用模板来启动服务。
- 所有服务从运维的角度来看都是一样的,所有服务检查统计数据、监控、启动和停止的方式都一样。
- 工具方面,构建过程围绕SBT(一个Scala构建工具),使用插件和辅助程序管理常见操作,包括在Git里打标签,发布到代码库等等。大多数程序员都不用再操心构建系统的细节了。
- 40台服务器采用HAProxy进行负载均衡,Varnish进行缓存.
- 200台数据库服务器中,很多是为了提高可用性而设,使用的是常规硬件,但MTBF(平均故障间隔时间)极低。故障时,备用充足。
- 500台服务器运行Apache和其他PHP程序。
- 6个为了支持PHP应用的后端服务,并有一个小组专门开发后端服务。新服务的发布需要两到三周,包括Dashboard通知、Dashboard二级索引、短地址生成、处理透明分片的memcache代理。
- 其中在MySQL分片上耗时很多。虽然在纽约本地非常热,但并没有使用MongoDB,他们认为MySQL的可扩展性足够了。
- Gearman用于会长期运行无需人工干预的工作。
- 可用性是以达到范围(reach)衡量的。用户能够访问自定义域或者Dashboard吗?也会用错误率。
- 历史上总是解决那些最高优先级的问题,而现在会对故障模式系统地分析和解决,目的是从用户和应用的角度来定成功指标。
- 最开始Finagle是用于Actor模型的,但是后来放弃了。对于运行后无需人工干预的工作,使用任务队列。而且Twitter的util工具库中有Future实现,服务都是用Future(Scala中的无参数函数,在与函数关联的并行操作没有完成时,会阻塞调用方)实现的。当需要线程池的时候,就将Future传入Future池。一切都提交到Future池进行异步执行。
- Scala提倡无共享状态。由于已经在Twitter生产环境中经过测试,Finagle这方面应该是没有问题的。使用Scala和Finagle中的结构需要避免可变状态,不使用长期运行的状态机。状态从数据库中拉出、使用再写回数据库。这样做的好处是,开发人员不需要操心线程和锁。
- 22台Redis服务器,每台的都有8-32个实例,因此线上同时使用了100多个Redis实例。
- Redis主要用于Dashboard通知的后端存储。
- 所谓通知就是指某个用户like了某篇文章这样的事件。通知会在用户的Dashboard中显示,告诉他其他用户对其内容做了哪些操作。
- 高写入率使MySQL无法应对。
- 通知转瞬即逝,所以即使遗漏也不会有严重问题,因此Redis是这一场景的合适选择。
- 这也给了开发团队了解Redis的机会。
- 使用中完全没有发现Redis有任何问题,社区也非常棒。
- 开发了一个基于Scala Futures的Redis接口,该功能现在已经并入了Cell架构。
- 短地址生成程序使用Redis作为一级Cache,HBase作为永久存储。
- Dashboard的二级索引是以Redis为基础开发的。
- Redis还用作Gearman的持久存储层,使用Finagle开发的memcache代理。
- 正在缓慢地从memcache转向Redis。希望最终只用一个cache服务。性能上Redis与memcache相当。
#p#
内部通讯管道(Firehose)
- 内部的应用需要活跃的信息流通道。这些信息包括用户创建/删除的信息,liking/unliking 的提示,等等。挑战在于这些数据要实时的分布式处理。我们希望能够检测内部运行状况,应用的生态系统能够可靠的生长,同时还需要建设分布式系统的控制中心。
- 以前,这些信息是基于 Scribe (Facebook 开源的分布式日志系统。)/Hadoop 的分布式系统。服务会先记录在 Scribe 中,并持续的长尾形式写入,然后将数据输送给应用。这种模式可以立即停止伸缩,尤其在峰值时每秒要创建数以千计的信息。不要指望人们会细水长流式的发布文 件和 grep。
- 内部的 firehose 就像装载着信息的大巴,各种服务和应用通过 Thrift 与消防管线沟通。(一个可伸缩的跨语言的服务开发框架。)
- LinkedIn 的 Kafka 用于存储信息。内部人员通过 HTTP 链接 firehose。经常面对巨大的数据冲击,采用 MySQL 显然不是一个好主意,分区实施越来越普遍。
- firehose 的模型是非常灵活的,而不像 Twitter 的 firehose 那样数据被假定是丢失的。
- firehose 的信息流可以及时的回放。他保留一周内的数据,可以调出这期间任何时间点的数据。
- 支持多个客户端连接,而且不会看到重复的数据。每个客户端有一个 ID。Kafka 支持客户群,每个群中的客户都用同一个 ID,他们不会读取重复的数据。可以创建多个客户端使用同一个 ID,而且不会看到重复的数据。这将保证数据的独立性和并行处理。Kafka 使用 ZooKeeper (Apache 推出的开源分布式应用程序协调服务。)定期检查用户阅读了多少。
为 Dashboard 收件箱设计的 Cell 架构
- 现在支持 Dashboard 的功能的分散-集中架构非常受限,这种状况不会持续很久。
- 解决方法是采用基于 Cell 架构的收件箱模型,与 Facebook Messages 非常相似。
- 收件箱与分散-集中架构是对立的。每一位用户的 dashboard 都是由其追随者的发言和行动组成的,并按照时间顺序存储。
- 就因为是收件箱就解决了分散-集中的问题。你可以会问到底在收件箱中放了些什么,让其如此廉价。这种方式将运行很长时间。
- 重写 Dashboard 非常困难。数据已经分布,但是用户局部升级产生的数据交换的质量还没有完全搞定。
- 数据量是非常惊人的。平均每条消息转发给上百个不同的用户,这比 Facebook 面对的困难还要大。大数据+高分布率+多个数据中心。
- 每秒钟上百万次写入,5万次读取。没有重复和压缩的数据增长为2.7TB,每秒百万次写入操作来自 24 字节行键。
- 已经流行的应用按此方法运行。
- Cell构架
- 每个 cell 是独立的,并保存着一定数量用户的全部数据。在用户的 Dashboard 中显示的所有数据也在这个 cell 中。
- 用户映射到 cell。一个数据中心有很多 cell。
- 每个 cell 都有一个 HBase 的集群,服务集群,Redis 的缓存集群。
- 用户归属到 cell,所有 cell 的共同为用户发言提供支持。
- 每个 cell 都基于 Finagle(Twitter 推出的异步的远程过程调用库),建设在 HBase 上,Thrift 用于开发与 firehose 和各种请求与数据库的链接。
- 一个用户进入 Dashboard,其追随者归属到特定的 cell,这个服务节点通过 HBase 读取他们的 dashboard 并返回数据。
- 后台将追随者的 dashboard 归入当前用户的 table,并处理请求。
- Redis 的缓存层用于 cell 内部处理用户发言。
- 请求流:用户发布消息,消息将被写入 firehose,所有的 cell 处理这条消息并把发言文本写入数据库,cell 查找是否所有发布消息追随者都在本 cell 内,如果是的话,所有追随者的收件箱将更新用户的 ID。
- cell 构架的优点:
- 大规模的请求被并行处理,组件相互隔离不会产生干扰。 cell 是一个并行的单位,因此可以任意调整规格以适应用户群的增长。
- cell 的故障是独立的。一个 Cell 的故障不会影响其他 cell。
- cell 的表现非常好,能够进行各种升级测试,实施滚动升级,并测试不同版本的软件。
- 关键的思想是容易遗漏的:所有的发言都是可以复制到所有的 cell。
- 每个 cell 中存储的所有发言的单一副本。 每个 cell 可以完全满足 Dashboard 呈现请求。应用不用请求所有发言者的 ID,只需要请求那些用户的 ID。他可以在 dashboard 返回内容。每一个 cell 都可以满足 Dashboard 的所有需求,而不需要与其他 cell 进行通信。
- 用到两个 HBase table :一个 table 用于存储每个发言的副本,这个 table 相对较小。在 cell 内,这些数据将与存储每一个发言者 ID。第二个 table 告诉我们用户的 dashboard 不需要显示所有的追随者。当用户通过不同的终端访问一个发言,并不代表阅读了两次。收件箱模型可以保证你阅读到。
- 发言并不会直接进入到收件箱,因为那实在太大了。所以,发言者的 ID 将被发送到收件箱,同时发言内容将进入 cell。这个模式有效的减少了存储需求,只需要返回用户在收件箱中浏览发言的时间。而缺点是每一个 cell 保存所有的发言副本。令人惊奇的是,所有发言比收件箱中的镜像要小。每天每个 cell 的发言增长 50GB,收件箱每天增长2.7TB。用户消耗的资源远远超过他们制造的。
- 用户的 dashboard 不包含发言的内容,只显示发言者的 ID,主要的增长来自 ID。
- 当追随者改变时,这种设计方案也是安全的。因为所有的发言都保存在 cell 中了。如果只有追随者的发言保存在 cell 中,那么当追随者改变了,将需要一些回填工作。
- 另外一种设计方案是采用独立的发言存储集群。这种设计的缺点是,如果群集出现故障,它会影响整个网站。因此,使用 cell 的设计以及后复制到所有 cell 的方式,创建了一个非常强大的架构。
- 一个用户拥有上百万的追随者,这带来非常大的困难,有选择的处理用户的追随者以及他们的存取模式(见Feeding Frenzy)
- 不同的用户采用不同并且恰当的存取模式和分布模型,两个不同的分布模式包括:一个适合受欢迎的用户,一个使用大众。
- 依据用户的类型采用不同的数据处理方式,活跃用户的发言并不会被真正发布,发言将被有选择的体现。
- 追随了上百万用户的用户,将像拥有上百万追随者的用户那样对待。
- cell 的大小非常难于决定。cell 的大小直接影响网站的成败。每个 cell 归于的用户数量是影响力之一。需要权衡接受怎样的用户体验,以及为之付出多少投资。
- 从 firehose 中读取数据将是对网络最大的考验。在 cell 内部网络流量是可管理的。
- 当更多 cell 被增添到网络中来,他们可以进入到 cell 组中,并从 firehose 中读取数据。一个分层的数据复制计划。这可以帮助迁移到多个数据中心。
在纽约启动运作
- 纽约具有独特的环境,资金和广告充足。招聘极具挑战性,因为缺乏创业经验。
- 在过去的几年里,纽约一直致力于推动创业。纽约大学和哥伦比亚大学有一些项目,鼓励学生到初创企业实习,而不仅仅去华尔街。市长建立了一所学院,侧重于技术。
团队架构
- 团队:基础架构,平台,SRE,产品,web ops,服务
- 基础架构:5层以下,IP 地址和 DNS,硬件配置
- 平台:核心应用开发,SQL 分片,服务,Web 运营
- SRE:在平台和产品之间,侧重于解决可靠性和扩展性的燃眉之急
- 服务团队:相对而言更具战略性
- Web ops:负责问题检测、响应和优化
软件部署
- 开发了一套 rsync 脚本,可以随处部署 PHP 应用程序。一旦机器的数量超过 200 台,系统便开始出现问题,部署花费了很长时间才完成,机器处于部署进程中的各种状态。
- 接下来,使用 Capistrano(一个开源工具,可以在多台服务器上运行脚本)在服务堆栈中构建部署进程(开发、分期、生产)。在几十台机器上部署可以正常工作,但当通过 SSH 部署到数百台服务器时,再次失败。
- 现在,所有的机器上运行一个协调软件。基于 Redhat Func(一个安全的、脚本化的远程控制框架和接口)功能,一个轻量级的 API 用于向主机发送命令,以构建扩展性。
- 建立部署是在 Func 的基础上向主机发送命令,避免了使用 SSH。比如,想在组A上部署软件,控制主机就可以找出隶属于组A的节点,并运行部署命令。
- 通过Capistrano的命令实现部署。它可以可以从git仓库中拉取代码。正因为是基于HTTP的,所以非常易于扩展。他们喜欢 Capistrano,因为它支持简单的基于目录的版本控制,能够很好地管理PHP程序。版本更新的时候,每个目录都包含一个SHA,所以很容易检查版本的正确性。
- Func API 可用于返回状态报告,报告哪些机器上有这些软件版本。
- 安全重启任何服务,因为它们会关闭连接,然后重启。
- 在激活前的黑暗模式下运行所有功能。
开发
- 从哲学上,任何人都可以使用自己想要的任意工具。但随着团队的发展壮大,这些工具出现了问题。新员工想要更好地融入团队,快速地解决问题,必须以他们为中心,建立操作的标准化。
- 过程类似于 Scrum(一种敏捷管理框架),非常敏捷。
- 每个开发人员都有一台预配置的开发机器,并按照控制更新。
- 开发机会出现变化,测试,分期,乃至用于生产。
- 开发者使用 VIM 和 TextMate。
- 测试是对 PHP 程序进行代码审核。
- 在服务方面,他们已经实现了一个与提交相挂钩的测试基础架构,接下来将继承并内建通知机制。
招聘流程
- 面试通常避免数学、猜谜、脑筋急转弯等问题,而着重关注应聘者在工作中实际要做什么。
- 着重编程技能。
- 面试不是比较,只是要找对的人。
- 挑战在于找到具有可用性、扩展性经验的人才,以应对 Tumblr 面临的网络拥塞。
- 例如,对于一个新的ID生成器器,他们需要一个高可用的JVM进程,并且需要在1万次每分钟的请求下及最多使用500兆内存的情况下完成1毫秒以下的响应。他们发现串行收集器给这个特定的工作负载带来最低的延迟。在 JVM优化上花了大量的时间。
- 在 Tumblr 工程博客(Tumblr Engineering Blog),他们对已过世的 Dennis Ritchie 和 John McCarthy 予以纪念。
经验及教训
- 自动化无处不在
- MySQL(增加分片)规模,应用程序暂时还不行
- Redis 总能带给人惊喜
- 基于 Scala 语言的应用执行效率是出色的
- 废弃项目——当你不确定将如何工作时
- 不顾用在他们发展经历中没经历过技术挑战的人,聘用有技术实力的人是因为他们能适合你的团队以及工作。
- 选择正确的软件集合将会帮助你找到你需要的人
- 建立团队的技能
- 阅读文档和博客文章。
- 多与同行交流,可以接触一些领域中经验丰富的人,例如与在 Facebook、Twitter、LinkedIn 的工程师多交流,从他们身上可以学到很多
- 对技术要循序渐进,在正式投入使用之前他们煞费苦心的学习 HBase 和 Redis。同时在试点项目中使用或将其控制在有限损害范围之内。
英文原文:The Tumblr Architecture Yahoo Bought For A Cool Billion Dollars
译文链接:http://www.oschina.net/translate/the-tumblr-architecture-yahoo-bought-for-a-cool-billion-doll