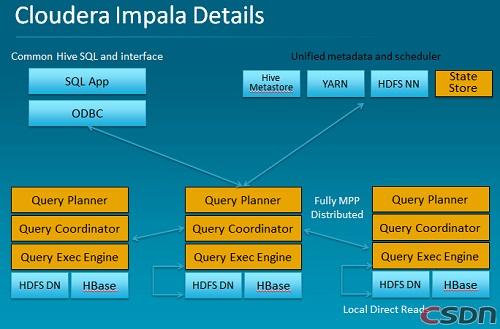
在去年认识了Impala这只高脚羚——其主要分布在东非,在Dremel的启发下开发。文章中还指出Impala不再使用缓慢的Hive+MapReduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或者HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如下图所示:
5月1日,Cloudera释放了Impala 1.0版本(下载传送门);对比旧版本,新的版本基于社区回馈和现实世界中不同的负载做出了修改,其根本的设计理念是与Hadoop无缝的整合——共同使用一个存储池、元数据模型、安全框架以及系统资源集。这种整合允许Impala用户从成本、灵活性、以及Hadoop交互式SQL查询中获利,并且能让Hadoop用户在MapReduce和其它的框架上做更好的SQL查询。最终达到所有的数据都可以做交互式分析以及做其它类型的处理,免去了ETL过程。进化后的高脚羚究竟如何,必须牵出来溜溜:
Impala 1.0中的特性
Impala 1.0的特性详情可以参考此文档,在这里先看一下摘要。为了集合上述特性,他们完成了所有Hadoop上实现SQL的事项:用以避免网络瓶颈的本地处理、交互式响应、本地数据的单储存池以及可同时对相同数据做不同类型的处理:
支持ANSI-92 SQL所有子集,包括CREATE, ALTER, SELECT, INSERT, JOIN和 subqueries
支持分区join、完全分布式聚合以及完全分布式top-n查询
支持多种数据格式:Hadoop原生格式(pache Avro, SequenceFile, RCFile with Snappy, GZIP, BZIP或未压缩)、文本(未压缩或者LZO压缩)和Parquet(Snappy或未压缩)——最新及最先进的列式存储
支持所有CDH4 64位包:Ubuntu、Debian、LES
可以通过JDBC、ODBC、Hue GUI或者命令行shell进行连接
Kerberos认证及MR/Impala资源隔离
Impala当下的性能
对比测试版,Impala新版本的性能提升很大。为了更加的客观,Cloudera在公布基准数字之前,先对测试如何迎合现实中的用例做出了解释:
因为做BI和分析涉及允许一组不同的查询集合去生成报告,而Cloudera此次性能测试的重点就是使用多个现实世界中用户针对原生Hadoop格式文件的查询——而不是针对预加载专业文件格式的择优选取(择优选取在项目宣传中还是比较常见的)。此外,为了测试平台的全局性能,在测试单机性能的同时,还测试了多租户情景下Impala查询及其它并行处理作业的性能。最终测试的制定通过与用户和社区的共同努力完成,Cloudera该测试基准无与伦比,并得到了很有意义的结果(事实上,这些结果可能会产生误解)。
测试中其它一些重要的事项:
在单用户Impala与Hive/MapReduce的对比中,两方面的查询都运行在HDFS文件系统中Snappy-compressed SequenceFile文件上。
表格中包含了5年内总计1TB的数据。
查询分布在不同的时间段(1个月到5年)以及不同数量延时(分别是Interactive Exploration、Reports和Deep Analytics buckets)上。
查询涉及到多种级别的join(数量上从1到7)和聚合,同时还包含了复杂的多层次聚合和内联视图。
定期运行在多种本地文件格式的查询集来自几个客户中的一个。
下面是几秒内一个20节点集群单机上的结果,按照类型划分buckets,并计算出这些buckets上的几何平均数(这种情况下几何平均数一直优于算数平均值,因为每个查询的响应时间都可能不同):
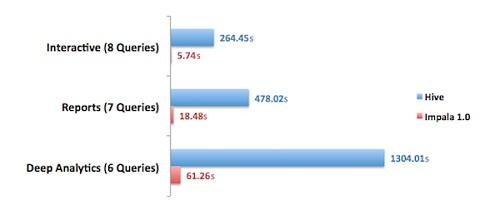
Impala 1.0 vs. Hive:查询响应时间(几何平均数,按类别)
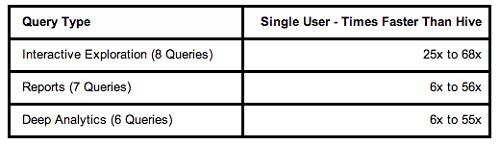
通过“比Hive快多少倍”的范围表达上图结果:
下图显示在加入更多并行客户端后,Impala将达到超线性标度的提升:
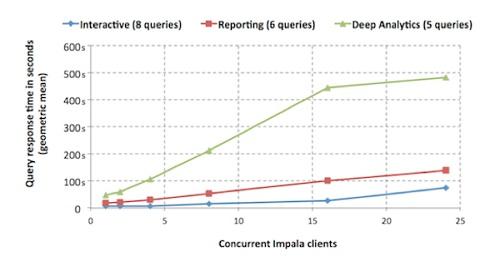
上述图片显示随着并行客户端数量的增加,查询响应时间甚至飙升到之前的24倍。然而即使这样,Impala 1.0性能仍然高于单机Hive!(需要注意的是,并行是非常重要的一点,Cloudera声明将来会做更深度的基准测试)
以上的结果显示,区别于Hive,Impala 1.0适合现代的BI环境(在这种环境下,用户将并行的运行不同的查询类型)——Impala中,性能会随着你添加节点得到类似的提升。
Impala未来的工作
虽然Impala的性能已经相当出众,但是Cloudera认为在下两个版本中完全实现Parquet和多线程执行后,Impala性能将再次得到跨越性提升。
在Impala 1.0中,Cloudera已针对BI和分析查询对MapReduce/Hive性能做了大幅度改善,实现了BI在Hadoop上的可行。而借助与Hadoop的完全整合,Impala灵活性同样得以保证,同时还具备了远程查询上的TCO优势以及DBMS/Hadoop混合优势——省下了昂贵的冗余设施。
在释放了Impala 1.0之后,Cloudera将最终目标定义为:允许用户将所有数据存储在通一个灵活、开放以及原生的Hadoop文件格式,并且可以同时在同一个数据上运行他们所有的批处理MapReduce、机器学习、交互式SQL/BI、数学以及其它作业。