













标签:大数据机器学习特征工程11年的时候我加入百度,在凤巢使用机器学习来做广告点击预测。当时非常惊讶于过去两年内训练数据如此疯狂的增长。大家都在热情的谈特征,每次新特征的加入都能立即得到AUC的提升和收入的增长。大家坚信特征才是王道,相信还会有源源不断的特征加入,数据规模还会成倍的增长。我也深受感染,坚定的相信未来两年数据至少还会长十倍,因此一切的工作都围绕这个假设进行。现在两年过去了,回过头来看,当时的预测是正确的吗?
数据的飞速增长,给模型训练带来极大压力。事实上,11年的时候模型训练已经是新特征上线的主要障碍了。凭着年轻的冲动,和对分布式系统和数值算法优化的一点点知识,我头脑一热就开始设计下一代模型训练系统了。目标是在同样的资源下,能容纳当前十倍的数据。项目是在情人节立项,取了一个好玩的名字,叫darlin【吐槽1】,这个系统应该是百度使用率***的机器学习训练系统之一了。一个重要问题是,它会像前任一样在两年后成为性能瓶颈吗?
目前看来,以上两个问题的答案都是否定的。
【吐槽1】意思是distributed algorithm for linear problems。更好玩的是,计算核心模块叫heart,络通讯模块叫telesthesia。数据是用类似bigtable的格式,叫cake,因为切起来很像蛋糕。开发的时候开玩笑说,以后上线了就会时不时听人说“darlin”,是 不是会很有意思?可惜全流量上线后我就直奔CMU了,没享受到这个乐趣:)
我们首先讨论特征。特征是机器学习系统的原材料,对最终模型的影响是毋庸置疑的。如果数据被很好的表达成了特征,通常线性模型就能达到满意的精度。一个使用机器学习的典型过程是:提出问题并收集数据,理解问题和分析数据继而提出抽取特征方案,使用机器学习建模得到预测模型。第二步是特征工程,如果主要是人来完成的话,我们称之为人工特征工程(human feature engineering)。举个例子,假设要做一个垃圾邮件的过滤系统,我们先收集大量用户邮件和对应的标记,通过观察数据我们合理认为,标题和正文含有“交友“、”发票“、”免费促销“等关键词的很可能是垃圾邮件。于是我们构造bag-of-word特征。继而使用线性logisitic regression来训练得到模型,最终把模型判断成是垃圾邮件的概率大于某个值的邮件过滤掉。
就这样搞定啦?没有。特征工程是一个长期的过程。为了提升特征质量,需要不断的提出新特征。例如,通过分析bad case,不久我们便发现,如果邮件样式杂乱含有大量颜色文字和图片,大概率是垃圾邮件。于是我们加入一个样式特征。又通过头脑风暴,我们认为如果一个长期使用中文的人收到俄语的邮件,那估计收到的不是正常邮件,可以直接过滤掉。于是又加入字符编码这一新特征。再通过苦苦搜寻或买或央求,我们得到一个数据库包含了大量不安全ip和发信地址,于是可以加入不安全来源这一新特征。通过不断的优化特征,系统的准确性和覆盖性不断的提高,这又驱使我们继续追求新特征。
由此可以看出,特征工程建立在不断的深入理解问题和获取额外的数据源上。但问题是,通常根据数据人能抽象出来的特征总类很有限。例如,广告点击预测,这个被广告投放公司做得最透彻的问题,目前能抽象出来的特征完全可以写在一张幻灯片里。好理解的、方便拿来用的、干净的数据源也不会很多,对于广告无外乎是广告本身信息(标题、正文、样式),广告主信息(行业、地理位置、声望),和用户信息(性别、年龄、收入等个人信息,cookie、session等点击信息)。KDD CUP2013腾讯提供了广告点击预测的数据,就包含了其中很多。所以最终能得到的特征类数上限也就是数百。另外一个例子是,google使用的数据集里每个样本含有的特征数平均不超过100,可以推断他们的特征类数最多也只是数百。
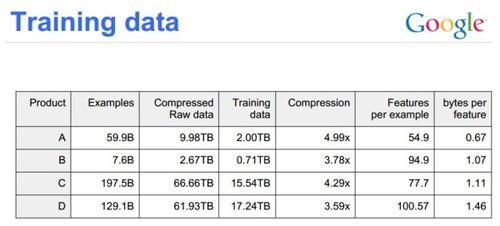
图1
因此,新数据源和新特征的获得会越来越难。然而,模型的精度并不是随着特征的增长而线性提高。很多情况是指数。随着人工特征工程的深入,投入的人力和时间越来越长,得到的新特征对系统的提升却越来越少。最终,系统性能看上去似乎是停止增长了。Robin曾问过我老大一个问题:“机器学习还能持续为百度带来收益吗?” 但时候我的***反应是,这个商人!现在想一想,Robin其实挺高瞻远瞩。
另外一个例子是IBM的Watson。从下图中可以看出,虽然每次性能的提升基本都是靠引入了新数据和新特征,但提升幅度是越来越小,也越来越艰难。
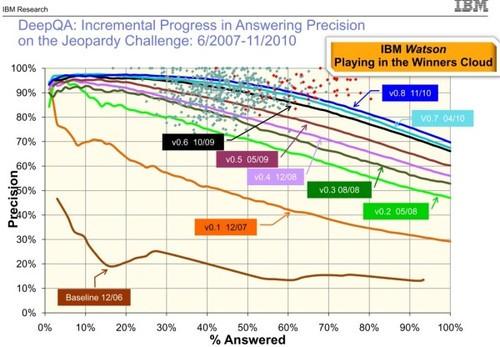
图2
这解释了***个问题,为什么特征数量的涨幅比当初预计的要少很多。一个特征团队,5个经验丰富的大哥加上10个动手强的小弟,几个月就能把可能的特征发掘得差不多,然后再用1、2年把特征全部做进系统。再然后呢?就会被发现有点后续无力了,进入中年稳定期了。
接下来讨论模型训练,因为不想被跨国追捕所以主要用google sibyl?来举例子。Sibyl是一个线性分类器,支持多种常见loss,例如logistc loss,square loss,hingle loss。还可以使用l2罚,或者l1罚来得到稀疏模型。Sibyl每天要被运行数百次,被广泛应用在google的搜索,gmail,youtube等应用上。由于这些应用直接关系到用户体验和收入,通常需要得到收敛精度很高而且收敛点稳定的模型。因为一个有着数百亿项的模型,如果收敛不够,即使只是少数特征上权重计算误差过大,也很容易引起bad case。同时,应用也希望模型的输出在一段时间是稳定的。
Sibyl使用parallel boosting,而darin用了一个更生僻的算法。后来听说了linkedin,yahoo,facebook的算法之后,狠下心survey了一些古老的优化论文,发现虽然大家名字各不相同,但其实都等价的【吐槽2】。在合适算法下,收敛到所要求的精度通常只需要数十论迭代。而且随着数据量的增大迭代数还会进一步降低。更多的,在online/incremental的情况下,还能更进一步大幅减少。 #p#
【吐槽2】在尝试过ml人最近一些年做的一系列算法后发现,它们真心只是研究目的:(
然后是工程实现。google有强大的底层支持,例如GFS,Mapreduce,BigTable,最近几年更是全部更新了这一套。所以sibyl的实现应该是相当轻松。但即使是从0开始,甚至不借助hadoop和mpi,也不是特别复杂。纯C开发,只是用GCC的情况下,代码量也只是数万行。主要需要考虑的是数据格式,计算,和网络通讯。数据格式首先考虑压缩率,可以大量节省I/O时间,其次是空间连续性(space locality)。但通常数据都远超last level cache,也不需要顾虑太多。计算可以用一些常见小技巧,例如少用锁,线程分配的计算量要尽量均匀(稀疏数据下并不容易),double转float,甚至是int来计算,buffer要管理好不要不断的new和delete,也不要太浪费内存。网络稍微复杂一点,要大致了解集群的拓扑结构,注意不要所有机器同时大量收发打爆了交换机,从而引起大量重传(这个经常发生),尽量少的做集群同步。
考察了几个公司的系统性能后,可以认为现在state-of-the-art的性能标准是,100T数据,通常包含几千亿样本,几百亿特征,200台机器,收敛精度要求大致等于L-BFGS 150轮迭代后的精度,可以在2小时内训练完成。如果用online/incremental模式,时间还可以大幅压缩。例如,使用67T数据和1000核,Sibyl在不到一个小时可以完成训练。
这回答了前面的第二个问题。假设特征不会突增,那么数据的主要增长点就是样本的累积。这只是一个线性的增长过程,而硬件的性能和规模同时也在线性增长。目前来看效率已经很让人满意。所以一个有着适当优化算法和良好工程实现的系统会胜任接下来一两年的工作。
在人工特征工程下,随着可用的新数据源和新特征的获取越来越困难,数据的增长会进入慢速期。而硬件的发展使得现有系统能完全胜任未来几年内的工作量,因此人工特征工程加线性模型的发展模式进入了后期:它会随着数据和计算成本的降低越来越普及,但却无法满足已经获得收益而希求更多的人的期望。
所以,然后呢?我来抛砖引玉:)
还是先从特征开始。正如任何技术一样,机器学习在过去20年里成功的把很多人从机械劳动里解救了出来,是时候再来解救特征专家们了。因为线性分类系统有足够的性能来支撑更多的数据,所以我们可以用它来做更加复杂的事情。一个简单的想法是自动组合特征,通过目标函数值的降低或者精度的提升来启发式的搜索特征的组合。此外,Google最近的deep learning项目【吐槽3】展现另外一种可能,就是从原始数据中构造大量的冗余特征。这些特征虽然质量不如精心构造的特征来得好,但如果数量足够多,极有可能得到比以前更好的模型。他们使用的算法结合了ICA和sparse coding的优点,从100x100图片的原始pixel信息中抽取上十亿的特征。虽然他们算法现在有严重的scalability的问题,但却可以启发出很多新的想法。 #p#
【吐槽3】中文介绍请见余老师的文章。我个人觉得这个项目更多是关于提取特征。引用Quoc来CMU演讲时说的两点。一、为了减少数据通讯量和提升并行效率,每一层只与下层部分节点相连。因此需要多层来使得局部信息扩散到高层。如果计算能力足够,单层也可能是可以的。二、如果只使用DL来得到的特征,但用线性分类器来训练,还可以提升训练精度。
模型方面,线性模型虽然简单,但实际上是效果最差的模型。鉴于计算能力的大量冗余,所以是时候奔向更广阔的天空了。在广告点击预测那个例子里,数据至少可以表示成一个四纬的张量:展现 x广告 x 广告主 x 用户。线性模型简单粗暴把它压成了一个2维矩阵,明显丢掉了很多信息。一个可能的想法是用张量分解(现在已经有了很高效的算法)来找出这些内在的联系。另一方面,点击预测的最终目的是来对广告做排序,所以这个本质是一个learning to rank的问题,而不是一个简单的分类问题。例如可以尝试boosted decision tree。
再有,最近大家都在谈神经网络。多层神经网络理论上可以逼近任何一个函数,但由于计算复杂、参数过多、容易过拟合等特点被更加简单的kernel svm取代了。但现在的数据规模和计算能力完全不同当年,神经网络又再一次显示它的威力,hinton又再一次走向了职业生涯的***。微软的语音实时翻译是一个很好的样例。反过来说,有多少人真正试过百亿样本级别kernel svm?至少,据小道消息说,多项式核在语音数据上效果很好。
我的结论是,大数据时代,虽然人工特征工程和线性模型将会被更广泛的事情,但它只是大数据应用的起点。而且,我们应该要迈过这个起点了。
















