微软最新Windows Azure数据中心扁平网络存储(Flat Network Storage)架构,展示Hadoop众所周知的“将计算转移到数据上”的特性,对大数据分析使用高可用性和可持续的blob存储集群成为现实。
微软全球副总裁Scott Guthrie三月份宣布了该公司HDInsight服务预览版的主要升级,即Hortonworks Hadoop Data Platform v1.1.0。此次更新的预览版中的DevOps特性,让开发者可以更轻松的用Windows Azure服务订阅创建高性能HDInsight计算集群,通过Windows Azure Management Portal实现(图一)。
SQL Server群组的新版本由以下这些开源Apache Hadoop组件以及可再分布的微软Java数据库连接(JDBC)驱动组成:
• Apache Hadoop, Version 1.0.3
• Apache Hive, Version 0.9.0
• Apache Pig, Version 0.9.3
• Apache Sqoop, Version 1.4.3
• Apache Oozie, Version 3.2.0
• Apache H.Catalog, Version 0.4.1
• Apache Templeton, Version 0.1.4
• SQL Server JDBC Driver, Version 3.0
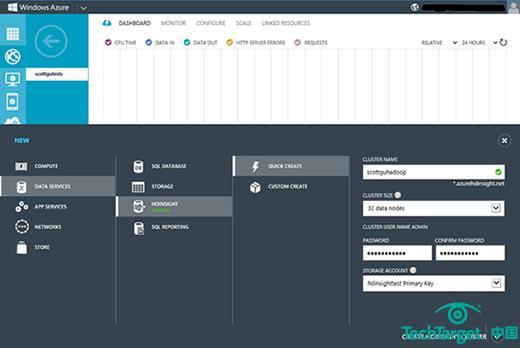
图一.开发者或者DevOps专家用Windows Azure Management Portal对HDInsight数据服务集群规定计算结点。
一个集群包含一个每小时成本0.48美元的超大头结点,以及一个或者一个以上的大型计算结点,每小时成本0.24美元。因此,四个结点的小范围集群费用为每小时1.44美元,或者每月1000美元。(微软基于其每小时2.88美元的收费价格列表提出,但是对于实际的时间打五折;点击获取更多HDInsight价格信息。)Windows Azure上的Hadoop第一次预览提供了预构建、可再生的三个结点集群,寿命为24小时;随后的升级增加到五天的寿命,但是关闭了可再生功能。数据存储和出口带宽收费在最新的预览版中没有折扣,但是对亚马逊Web服务的简单对象存储服务(S3)具有竞争性。打折的Azure服务不提供服务水平协议。
将HDFS存储从本地文件系统转移到Windows Azure blob
Hadoop最基本的DevOps格言之一就是“将计算转移到数据上”,通常需要托管Hadoop分布式文件系统(HDFS)数据存储文件,并在运营系统的文件系统中计算操作。Windows Azure开发者习惯了Azure blob存储,这种存储通过三次复制所有的存储对象,提供了高可用性。加强了可持续性,灾难恢复通过地理复制激活,地理位置设置好后,在相同的区域中的Windows Azure数据中心中一式三份复制。比如,在西欧都柏林创建了Azure blob存储,就会自动复制到北欧的阿姆斯特丹。HDFS不提供内建可用性和可持续性特性。
HDFS在本地文件系统上运行,对比HDInsight 服务第一代网络架构的MapReduce任务和相同文件系统中的MapReduce计算可执行性,交付了比Azure blob上更好的性能。Windows Azure存储由于早期分离虚拟机(VM)的决定而进展缓慢,主要是改善多租户隔离的存储计算。
Windows Azure存储团队的Brad Calder在2012年11月的一篇博客中,对扁平网络存储和第二代存储硬件进行了描述,详见《Windows Azure的扁平网络存储和2012年可扩展性目标》。他对比了第一代和第二代存储硬件:
|
硬件代数 |
存储结点网络速度 |
计算和存储之间的网络 |
负载均衡器 |
日志存储设备 |
|
第一代 |
1 Gbps |
分层网络 |
硬件 |
硬盘 |
|
第二代 |
10 Gbps |
扁平网络 |
软件 |
SSD |
根据Calder的博客内容,第二代Quantum 10或者Q10,存储提供了充分的非阻塞,10Gbps成熟的网状网络提供了聚合基架,为每一个Windows Azure数据中心提供超过50Tbps的带宽。他宣称实景实现了存储账户可扩展性目标,下面就是截止到2012年底实现的目标:
• 容量多达200TB
• 事务比率达到20,000实体/消息/blobs/秒
• 地理冗余存储账户带宽
o 入口: 5 Gbps
o 出口: 10 Gbps
• 本地冗余存储账户带宽
o 入口: 10 Gbps
o 出口: 15 Gbps
存储账户有异地备援,默认提供地理冗余存储。终端用户可以关闭异地备援,使用本地冗余存储,从而减少地理冗余相关的存储成本,实现更高的入口和出口目标。
Denny Lee是SQL Server团队商务智能团队的成员,Brad Sarsfield是Windows Azure团队的主要开发者,共同探讨了Azure上HDInsight的blob存储性能。下面是要点总结:http://dennyglee.com/2013/03/18/why-use-blob-storage-with-hdinsight-on-azure/
• Azure blob存储在map任务中提供了与HDFS几近一致的读(性能和任务拆分)访问特性。
• Azure blob提供更快的Hadoop HDFS写访问,在往磁盘写数据时,任务完成的更快,减少任务。
Lee也总结了Nasuni的《2013云存储产业现状报告》, 对比了Azure blob存储和亚马逊简单对象存储服务(S3)的性能:
• 速度: Azure比位列第二的亚马逊S3的写速度快56%,读取文件的速度比排在第二的惠普云对象存储的读速度快39%。
• 有效性: Azure的平均响应时间比亚马逊S3快25%。
• 可扩展性:亚马逊S3各项平均扩展范围测试为0.6%,微软Windows Azure 范围1.9%,二者的可扩展范围可接受度都非常高。惠普和Rackspace,都是基于OpenStack 的云,显示的值为23.5%和26.1%。随着对象总数的增加,性能越来越不可预知。
我的博文《在Windows Azure CTP上使用来自Windows Azure Blob和Apache Hadoop的数据》,揭示了如何输入*.csv文件到HDInsight所调用的Azure存储库(ASV)。
HDInsight服务控制面板和样例库

图二.HDInsight控制台的活动瓷砖用户界面提供了对于该服务的DevOps 特性的访问。Monitor Cluster和 Documentation瓷砖是新添加的。
Windows Azure HDInsight服务的控制面板简化了Hadoop DevOps,提供了可以轻松访问的交互控制台,包括执行JavaScript代码、Hive查询、卡其远程桌面连接到计算VM、显示MapReduce 工作记录以及访问示例分析任务和文档。(图二)
交互控制台的Hive窗口允许开发者基于Azure Blob数据(图三)定义结构化Hive表格。数据专家用类SQL语言——HiveQL查询Hive表。开放数据库连接(ODBC)Hive驱动可以让商务智能分析师用微软Excel可视化HiveQL结果。更多细节,参考《Excel中设置ODBC数据源》和《Excel中执行HiveQL查询》。
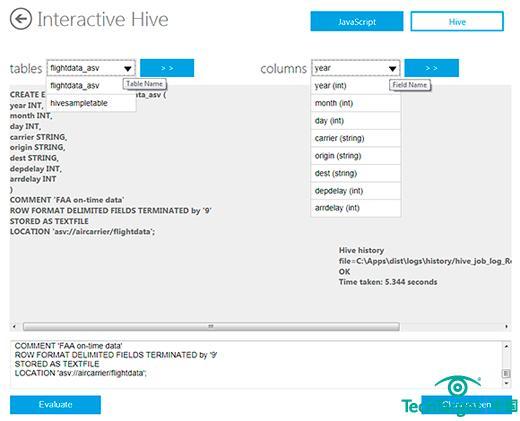
图三.交互控制台的Hive窗口允许开发者基于Azure Blob数据定义结构化Hive表格。
最新的Azure HDInsight服务预览版在微软数据中心,充分利用扁平网络的第二代硬件。ASV用户得到了HDFS集群的Windows Azure blob存储有效性和可持续性,而且性能不受到影响。开发者必须要警惕的是,删除不需要的集群,避免大量未使用的计算账单出现。
关于作者
Roger Jennings是一位面向.NET开发者兼作者, Windows Azure MVP, OakLeaf Systems的首席咨询师,也是OakLeaf Systems博客的管理者。他同时还是30多本书的作者,范围涉及Windows Azure平台、微软操作系统(Windows NT和2000 Server) 、数据库(SQL Azure、SQL Server和Access)、.NET 数据访问、Web服务和InfoPath 2003。他的图书英文版本印刷数量超过125万,还被翻译成20多种语言出版。