毫无疑问,VMware公司希望所有企业用户都以虚拟化而非裸机方式运行一切。而且在过去几年中,该公司也一直在推动Hadoop堆栈的虚拟化概念,旨在使整套堆栈运行更顺畅、管理更简便。为了达成这一目标,VMware推出了Serengeti项目,目前此项目已经获得一部分功能性调整,欲吸引更多大数据集群制造商加以尝试。
在本周二公布的Serengeti 0.8.0中,这款专为Hadoop虚拟化打造的开源工具已经能够支持数个Hadoop发行版,外加多项能够简化Hadoop之上HBase数据仓储设置流程的功能。
此次Seregenti版本更新发布在Richard McDougall的一篇博文中,他是虚拟化巨头VMware公司CTO办公室的***工程师。“大多数大数据环境中包含着混合工作负载,”McDougall解释道。“Serengeti的任务是让尽可能多的大数据类工作负载在同一套通用共享型平台上进行运作。”
通过对集群的虚拟化,大家得以在共享硬件中运行各种大数据处理工具的多项功能,根据需要与运行着每种工作负载的虚拟机进行拨号连接,并以可逆方式使其与其它工作负载协同运作。
这一切的核心在于弹性缩放,用户需要为此交纳虚拟化性能税。由于很多工作负载都要求在服务器中塞入大量运算核心,因此这笔开销还是可以接受的。
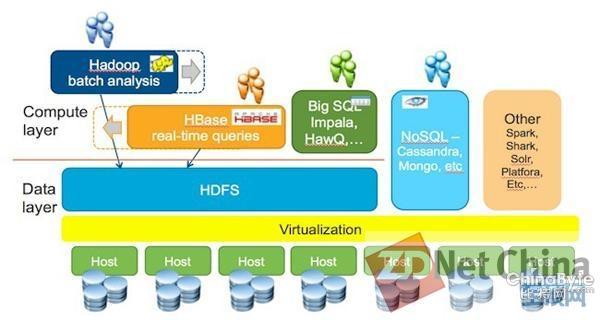
VMware希望在其ESXi服务器虚拟化之上部署大数据工具层
大多数企业可能还没有想过通过这种方式处理自己的Hadoop集群,也很可能对这种机制的具体功能及表现抱怀疑态度。更令他们担心的是,批量作业、查询及其它依赖于此类结果的应用程序在周转时间方面是否可能受到影响。他们显然不希望由于虚拟化的介入而在性能方面做出牺牲。
但VMware公司则始终抱持着一往无前的态度,坚信虚拟化将成为足以应所有大数据任务的服务器集群混合模式。有鉴于此,Pivotal公司已经有计划将Serengeti与Cloud Foundry平台云、EMC的Greenplum数据仓储以及Hadoop发行版加以整合,在今年晚些时候为用户带来全能型Pivotal产品。
随着Serengeti 0.8.0版本的发布,Cloudera的CDH4与MapR Technologies的M5 Hadoop发行版如今也已经获得在虚拟机容器中运行的必要支持。开源Apache 1.0发行版此前已经获得支持,同样可运行于虚拟机中的还有EMC的Greenplum HD 1.2、Cloudera CDH 3以及Hortonworks Data Platform 1.0。
在CHD4发行版的辅助下,Serengeti已经能够识别出我们所使用的HDFS1或HDFS2文件系统,同时也能识别到Cloudera内置在其Hadoop发行版中的联合NameNode支持,甚至能够对选项进行配置。
而在MapR发行版的辅助下,Serengeti则获得了对NFS类文件系统中容器位置数据库(简称CLDB)的识别能力,这是因为MapR将NFS作为HDFS的替代方案。其它新增识别对象包括FileServer、JobTracker以及MapR堆栈中的TaskTracker元素。Serengeti甚至能够将以上对象打包入虚拟机当中并通过复制副本进行性能扩展。
如果大家正打算设置一套HBase数据仓储系统,那么请注意Serengeti 0.8.0发行版中的备注:这款VMware工具能够创建采用底层HDFS文件系统的HBase集群,并将其与MapReduce数据处理机制对接,同时利用Thrift与RESTful API对HBase加以管理。
Serengeti还懂得如何为数据仓储系统配置主动及使用频率较高的HMaster节点副本,并能够在数据仓储在HDFS基础上设置完毕后实现HBase RegionalServers扩展。HBase能够在Serengeti的帮助下部署在以Apache Hadoop、Cloudera、Hortonworks或Greenplum发行版为基础的虚拟化方案之中。(但出于某种原因, MapR发行版并未包含在内)
大家现在已经可以在VMware官方网站中下载采用Serengeti 0.8.0的虚拟机方案,而且是免费使用。