最近开始看Hadoop的一些源码,展开 hadoop 的源码包,各个组件分得比较清楚,于是开始看一下IPC的一些源码。
IPC模块,也就是 进程间通信模块,如果是在不同的机器上,那就可以理解为 RPC 了,也就是远程调用。事实上, hadoop 中的 IPC 也就是基于 RPC 实现的。
使用 sloccount 统计一下 ipc 包中代码的行数,一共是 2884 行。也就是说,IPC 作为hadoop的基础组件,仅仅用了不到3000行的代码,就完成得稳定且富有效率。
IPC 中的关键类关系:
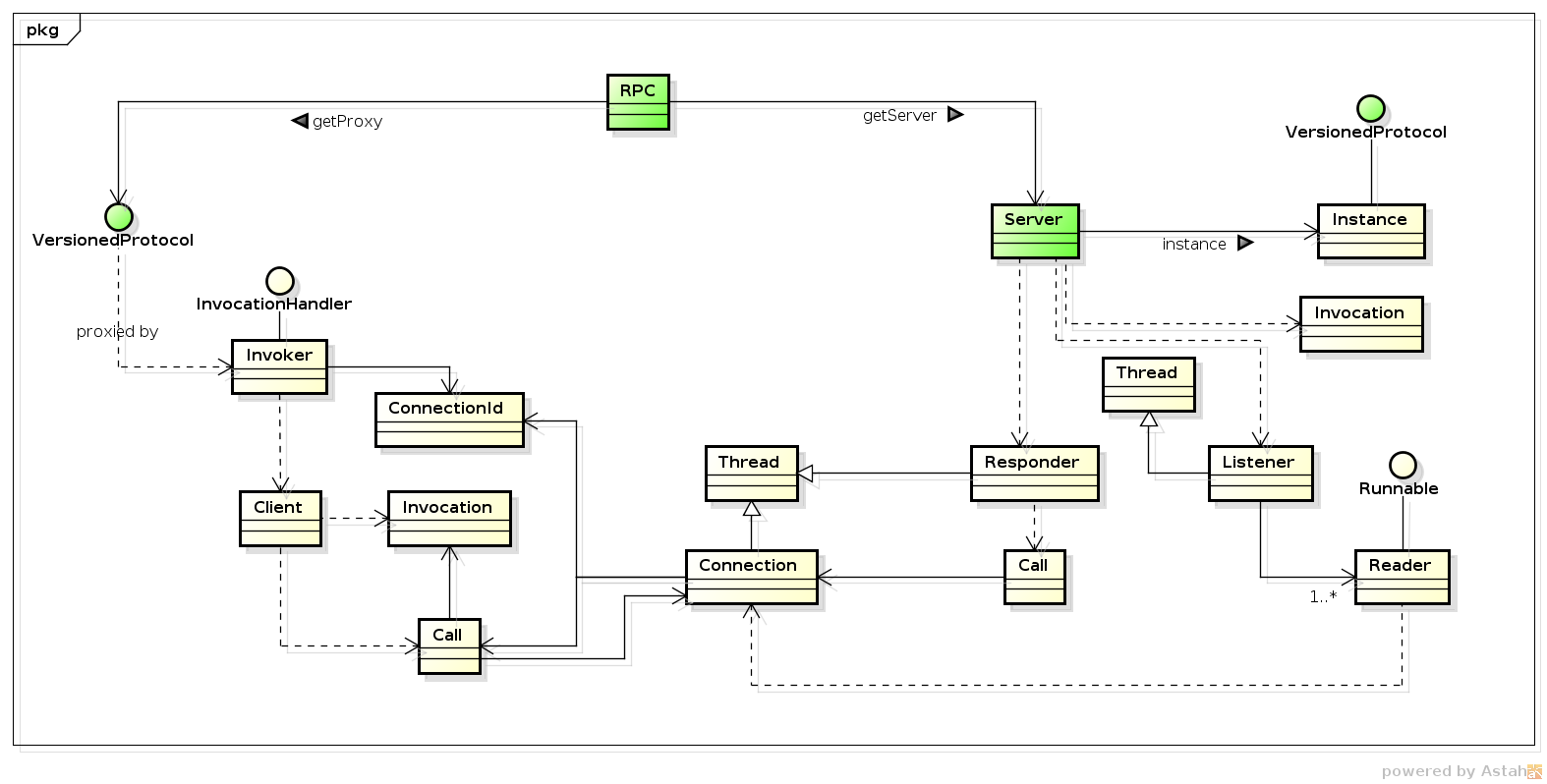
对用户而言,可以直接使用的就是绿色的类。
通过 RPC 这个门面:
- 客户端可以创建相应的 proxy,接着就可以进行远程调用。
- 而服务提供者则可以创建相应的 server,并进行相应的生命周期管理(start、stop),从而提供服务。
序列化
从上图也可以看出,client 和 server 的交互,是通过网络 connection, 而走网络的调用,是需要走序列化/反序列话的过程的。
这个过程, IPC 使用了 Hadoop 的自己的序列化机制,一切都在 Writable 接口中,只要给定 writable 的 DataOutput 和 DataInput,就可以让 Writable 自己实现序列化。
一些问题和思考
-
client 是单例的吗 —— 可以理解为是,但其实不一定。可以跟踪 getProxy 的代码,虽然每次都会新建一个代理对象,但底层的 Client 还是和 SocketFactory 对应的。一般默认的,都是使用默认的 SocketFactory, 但如果你设置了 "hadoop.rpc.socket.factory.class.default" ,则会有新的Client与你自定义的 SocketFactory 对应。这时候, client 就不是单例的。
-
client 与同一个 server 有几个连接 —— 一个 client与一个 server 只有一个连接,具体可以看生成的代理中,有一个 remoteId, 这个 remoteId 是和 client关联的,client 进行调用的使用,会将此 remoteId 作为一个 connectionId。因此,一般一个 client 是一个连接。
-
如果 client 是一个连接,那么对此 client 的调用,不都是串行的吗? —— 看你怎么理解了,在用户层面,也就是 client 调用的方法,是可以并发的。client 底层是使用一个连接来进可能的完成吞吐量。每个 request 和 response 都会有一个 id 关联起来。因此一个连接上可以跑满请求和相应。
-
由于网络问题,client调用服务失败后,有重试机制吗 —— 在IPC中没有看到call的重试,需要上层去保证了。但是后面的调用会重新建立连接。
-
server 是单例的吗 —— 不一定。如果你只 getServer 一次的话。创建一个 server 的代价是非常重的。通过上图你也可以知道,他需要有一个线程 (Listener)来 accept socket,同时需要一些 Reader线程 来进行 socket 的 read,还有一个 Responder 来进行 socket 的 write,另外,还有若干个 handler线程 来进行业务处理。因此,如果可以减少 server 的个数,就应该减少 server 个数。
-
暴露出的服务是否应该是线程安全的 —— 是的,一定要线程安全。server 底层是通过 nio 进行 socket 操作的,因此虽然只有一个线程负责 accept,但是能够支持很多的client连接。这些连接在到达 server 端之后,很有可能就会并发执行同一方法(如果你的业务handler不止一个的话)
-
一个 server 要消耗多少线程资源? —— 让我们来算一下,一个 Listener 线程,若干个 Reader 线程(默认1个),若干个 Handler 线程(在 getServer 的时候指定,一般1 - 10个),一个 Responder 线程。如果都按照默认值来计算的话。最少需要 1 + 1 + 1 + 1 = 4 个线程。也许,不应该算多,如果请求量不大的话,这些线程应该都被 blocked 住的。
总结
- Hadoop 的 IPC 是一个比较轻量级别的 RPC
- 从代码来看,只支持 java 进程之间的通信
- 从没有重试机制、一个 Client 只有一个连接的机制来看,适合与应用网络环境较好的场景,适合同机架或者同机房的集群。
P.S. 看了一下 io 包中,其实有个 retry 的 package,里面就是一个重试机制。奇怪的是为啥这个 package 被包含在 io package 中。