最近真是忙翻天了,该是有三个月没写博客了。
这次的需求是在Mongo的使用中碰到的,但是我觉得把这个需求放进传统的RDBMS中更易于理解。需求是这样的:假设你数据库使用的是Sqlserver,有一张表,500W条数据,你要做一个随机在表中选择一条数据的功能。
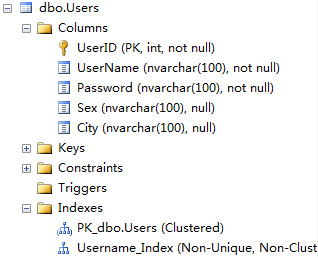
假设本文所探讨的数据结构如图(聚集索引在Pk上,UserName上加了非聚集索引):
你的***反应大概是:哎呀妈呀忒巧了,正好主键使用的是Int自增的,我只用生成一个随机数,然后找这个随机数对应的主键就好了
实现的步骤大概是:
①返回数据库中ID的***值IdMax
②生成1到IdMax中间一个的随机数 int random = new Random().Next(1,IdMax);
③使用UserID = random作为条件查询
④如果没有查询到数据,则重新生成一个随机数,再次查找(因为某个UserID的数据可能被删除了)
这种方法简单,暴力,但是有一个致命的问题:我这里在建表的时候为了说明这种方法,所以主键使用的是Int,但是在大多数我所知道的生产环境中,其实是用Guid的。这个致命的问题会直接导致上面的那个方法不可用。
至于为什么大多数我所知道的生产环境中用Guid而不用Int,我下一篇会做出对比。
既然Int在使用Guid作为主键的时候不能用,那么我们就用Row_Number吧。Sqlserver必然是支持Row_Number的,貌似Oracle和MySql中也有类似概念(不确定,问同事得到了肯定答复,没有深究)。
实现的步骤大概是:
①返回数据库中数据的总条数count
②生成1到count中间一个的随机数 int random = new Random().Next(1,count);
③查找Row_Number = random的那条数据
但是Row_Number有个极其不好的地方,就是查询越后面的数据越慢,越吃资源。但凡是将数据有序储存的数据库基本都有这个问题,比如说下面两条语句:
- select * from
- (SELECT UserID,UserName,Password,Sex,City,ROW_NUMBER()OVER(ORDER BY CURRENT_TIMESTAMP) as Number
- FROM [User_db].[dbo].[Users] ) as query
- where query.Number = 20
- select * from
- (SELECT UserID,UserName,Password,Sex,City,ROW_NUMBER()OVER(ORDER BY CURRENT_TIMESTAMP) as Number
- FROM [User_db].[dbo].[Users] ) as query
- where query.Number = 5000000
***条查Row_Number=20的数据,logical reads 5.elapsed time = 58 ms.
第二条查Row_Number=5000000的数据,logical reads 90208.elapsed time = 900 ms.
可以明显的看出,后者的逻辑读次数多了太多,而运行速度也慢了不少。如果这个功能比较频繁使用,比如说这是向用户随机推荐好用的功能,那么这个将会成为一个性能瓶颈
有的网友说使用这句:
- SELECT TOP 1 * FROM Users ORDER BY NEWID()
这个运行出来结果是正确的,但是效率却大打折扣。比如说我查到了第1336793条数据,logical reads 90208,elapsed time = 3026 ms
查看执行计划,发现Sort占用了98%:

有没有比Row_Number更好一点的方法?
答案是在表中再加一列Random列,使得数据结构变更成这样:
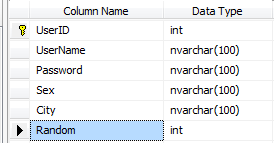
在添加数据的时候,就生成一个随机数插入进来。按照本篇的例子来说,一开始可以生成0到一亿之间的随机数插入。注意,要在Random上加索引。
实现的步骤大概是:
①插入数据的时候添加一个随机
②生成一个随机数,查询 select top(1) * from Users where Random > 随机数
③这个查询的结果可能会有多条(但不会很多),再在这个多条数据中随机筛选其一(使用Linq可以很方便的实现,不赘述)
好了,基本说完了,请允许我在结尾卖个萌:聪明的读者,开动脑筋,您还有更好的方法么?如果有,请留言。
原文链接:http://www.cnblogs.com/CrazyJinn/archive/2013/03/19/2968769.html