












一、读写机制
首先来看文件读取机制:尽管DataNode实现了文件存储空间的水平扩展和多副本机制,但是针对单个具体文件的读取,Hadoop默认的API接口并没有提供多DataNode的并行读取机制。基于Hadoop提供的API接口实现的云盘客户端也自然面临同样的问题。Hadoop的文件读取流程如下图所示:
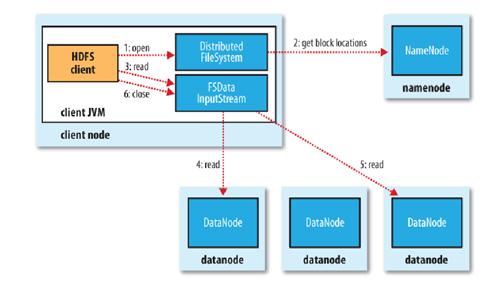
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
- 客户端开发库会选取离客户端最接近的datanode来读取block;
- 读取完当前block的数据后,关闭与当前的datanode连接,并为读取下一个block寻找***的datanode;
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读取。
这里需要注意的关键点是:多个Datanode顺序读取。
其次再看文件的写入机制:
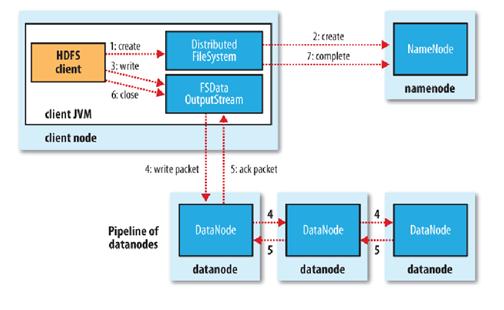
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表, 列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入***个 datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到***一个 datanode,这种写数据的方式呈流水线的形式。
- ***一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的 pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的 datanode,保持replicas设定的数量。
关键词:开发库把packet以流的方式写入***个datanode,该datanode将其传递给pipeline中的下一个datanode,知道***一个Datanode,这种写数据的方式呈流水线方式。
二、解决方案
1.下载效率优化
通过以上读写机制的分析,我们可以发现基于Hadoop实现的云盘客户段下载效率的优化可以从两个层级着手:
1.文件整体层面:采用并行访问多线程(多进程)份多文件并行读取。
2.Block块读取:改写Hadoop接口扩展,多Block并行读取。
2.上传效率优化
上传效率优化只能采用文件整体层面的并行处理,不支持分Block机制的多Block并行读取。
原文链接:http://www.cnblogs.com/hadoopdev/archive/2013/03/07/2947447.html
【编辑推荐】

















