













本文目录如下:
1、概述 1、1 系统性能定义 1、2 目的意义 2、性能优化技术 2、1 前端优化 2、2 后端优化 3、总结
1、概述
最近看了很多关于系统性能调优的文章,发现很多文章都是介绍某一方面的,例如专门数据库方面的优化、前端页面的优化等等都不是很全面,这里结合我在工作中的一些实践对系统性能调优技术来一个综合性的分享。
1、1 系统性能定义
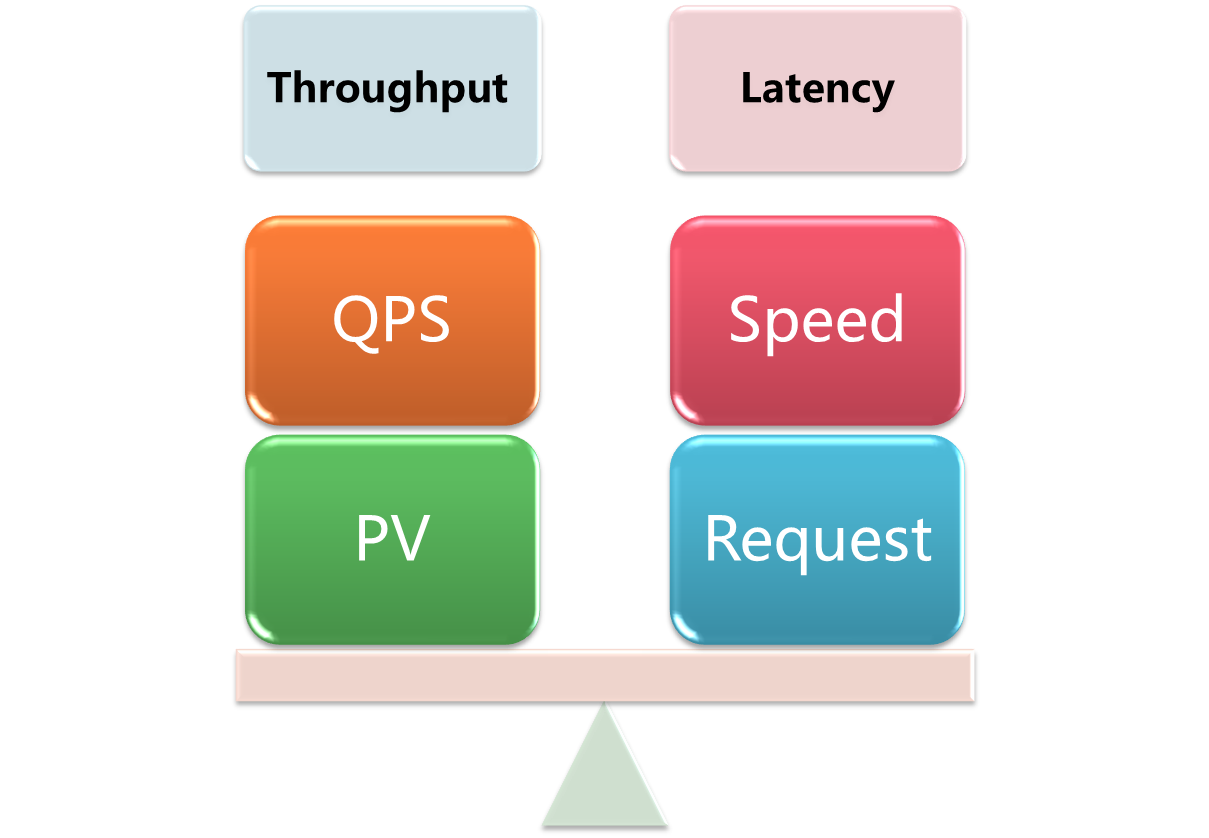
如上图,性能就是吞吐量加延迟,这两个相互矛盾又相互协调构成了一个系统性能的定义:
- Throughput ,吞吐量。也就是每秒钟可以处理的请求数,任务数。
- Latency, 系统延迟。也就是系统在处理一个请求或一个任务时的延迟。
一般来说,一个系统的性能受到这两个条件的约束,缺一不可。比如,我的系统可以顶得住一百万的并发,但是系统的延迟是2分钟以上,那么,这个一百万的负载毫无意义。系统延迟很短,但是吞吐量很低,同样没有意义。所以,一个好的系统的性能测试必然受到这两个条件的同时作用。 有经验的朋友一定知道,这两个东西的一些关系:
- Throughput越大,Latency会越差。因为请求量过大,系统太繁忙,所以响应速度自然会低。
- Latency越好,能支持的Throughput就会越高。因为Latency短说明处理速度快,于是就可以处理更多的请求。
1、2 目的意义
本文的目的是通过讲解系统性能让大家在后续的工作中能够带着产品化的思路去优化自己的代码包括前后台、数据库等,自测过程中我们可以利用压力性能测试pylot、Fiddler、单元测试等工具去发现系统的问题从而去优化提高系统的质量,这样通过团队的配合和努力来提高增强用户的体验从而提高我们公司的竞争力!#p#
2、性能优化技术
以下性能优化技术需要我们在自己工作过程中不断积累和总结,在工作中配合一些专业的测试工具去发现性能的瓶颈,这里把性能优化技术分为两块分别是前端和后端的优化。
2、1 前端优化

2.1.1 负载均衡
通过DNS的负载均衡器(一般在路由器上根据路由的负载重定向)可以把用户的访问均匀地分散在多个Web服务器上。这样可以减少Web服务器的请求负载。因为http的请求都是短作业,所以,可以通过很简单的负载均衡器来完成这一功能。***是有CDN网络让用户连接与其最近的服务器(CDN通常伴随着分布式存储)。
CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。
CDN的通俗理解就是网站加速,可以解决跨运营商,跨地区,服务器负载能力过低,带宽过少等带来的网站打开速度慢等问题。
CDN的特点和优势:
1、本地Cache加速 提高了企业站点(尤其含有大量图片和静态页面站点)的访问速度,并大大提高以上性质站点的稳定性
2、镜像服务 消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量。
3、远程加速 远程访问用户根据DNS负载均衡技术智能自动选择Cache服务器,选择最快的Cache服务器,加快远程访问的速度
4、带宽优化 自动生成服务器的远程Mirror(镜像)cache服务器,远程用户访问时从cache服务器上读取数据,减少远程访问的带宽、分担网络流量、减轻原站点WEB服务器负载等功能。
2.1.2 减少请求和2.1.3缩减网页
减少请求数
(1)系统某个页面的加载往往伴随着多个请求的发生,请求越多吞吐量越大,延迟就会变大,这里就要考虑优化请求数了,我们可以使用Fiddler等工具查看某个网页的请求数,如下图,如果我们的一个网页引用了很多样式和js,例如一个页面引用了10个css和10个js,那么我们应该考虑把某些样式和js合并起来;

(2)Css Sprites:有很多图片我们其实可以用一张图片来代替的,一般需要跟美工或UI设计器配合一起来做的,美工或UI设计师去设计出来之后告诉我们图片中具体元素的位置或者封装在css中,研发这边直接调用即可。
异步
系统某个页面中如果有一个请求的响应超过0.5秒以上或者请求的响应量大于300KB的话我们应该考虑进行异步请求,还有就是一些服务的调用这些尽量不要用同步,一阻塞整个网站的体验会非常差;
CSS/JS压缩
可以借助一些开源的压缩工具,像开源的yuicompressor,发布或发包时把js和css都压缩一下,这样js和css文件就会非常小了;
GZIP压缩
使用GZIP压缩可以降低服务器发送的字节数,能让客户感觉到网页的速度更 快也减少了对带宽的使用情况;
IIS里面也可以设置GZIP压缩,可以压缩应用程序文件和静态文件,具体百度。
精简代码
***效的程序就是不执行任何代码的程序,所以,代码越少性能就越高。关于代码级优化的技术大学里的教科书有很多示例了。如:减少循环的层数,减少递归,在循环中少声明变量,少做分配和释放内存的操作,尽量把循环体内的表达式抽到循环外,条件表达的中的多个条件判断的次序,尽量在程序启动时把一些东西准备好,注意函数调用的开销(栈上开销),注意面向对象语言中临时对象的开销,小心使用异常。
开源框架
现在开源的好东西太多了,关键是你要有一双慧眼,向大家推荐开源中国社区、github、codeplex,我发现现在比较厉害的开发者就是一个很牛逼的模仿者,消化掉成为自己的其实就是一种创新;
2.1.4 优化查询
(1)SQL语句的优化
关于SQL语句的优化,首先也是要使用工具,比如:MySQL SQL Query Analyzer,Oracle SQL Performance Analyzer,或是微软SQL Query Analyzer,基本上来说,所有的RMDB都会有这样的工具,来让你查看你的应用中的SQL的性能问题。 还可以使用explain来看看SQL语句最终Execution Plan会是什么样的。
还有一点很重要,数据库的各种操作需要大量的内存,所以服务器的内存要够,优其应对那些多表查询的SQL语句,那是相当的耗内存。
下面我根据我有限的数据库SQL的知识说几个会有性能问题的SQL:
全表检索。比如:select * from user where lastname = “xxxx”,这样的SQL语句基本上是全表查找,线性复杂度O(n),记录数越多,性能也越差(如:100条记录的查找要50ms,一百万条记录需要5分钟)。对于这种情况,我们可以有两种方法提高性能:一种方法是分表,把记录数降下来,另一种方法是建索引(为lastname建索引)。索引就像是key-value的数据结构一样,key就是where后面的字段,value就是物理行号,对索引的搜索复杂度是基本上是O(log(n)) ——用B-Tree实现索引(如:100条记录的查找要50ms,一百万条记录需要100ms)。
索引。对于索引字段,***不要在字段上做计算、类型转换、函数、空值判断、字段连接操作,这些操作都会破坏索引原本的性能。当然,索引一般都出现在Where或是Order by字句中,所以对Where和Order by子句中的子段***不要进行计算操作,或是加上什么NOT之类的,或是使用什么函数。
多表查询。关系型数据库最多的操作就是多表查询,多表查询主要有三个关键字,EXISTS,IN和JOIN(关于各种join,可以参看图解SQL的Join一文)。基本来说,现代的数据引擎对SQL语句优化得都挺好的,JOIN和IN/EXISTS在结果上有些不同,但性能基本上都差不多。有人说,EXISTS的性能要好于IN,IN的性能要好于JOIN,我各人觉得,这个还要看你的数据、schema和SQL语句的复杂度,对于一般的简单的情况来说,都差不多,所以千万不要使用过多的嵌套,千万不要让你的SQL太复杂,宁可使用几个简单的SQL也不要使用一个巨大无比的嵌套N级的SQL。还有人说,如果两个表的数据量差不多,Exists的性能可能会高于In,In可能会高于Join,如果这两个表一大一小,那么子查询中,Exists用大表,In则用小表。这个,我没有验证过,放在这里让大家讨论吧。另,有一篇关于SQL Server的文章大家可以看看《IN vs JOIN vs EXISTS》。
JOIN操作。有人说,Join表的顺序会影响性能,只要Join的结果集是一样,性能和join的次序无关。因为后台的数据库引擎会帮我们优化的。Join有三种实现算法,嵌套循环,排序归并,和Hash式的Join。(MySQL只支持***种)。
- 嵌套循环,就好像是我们常见的多重嵌套循环。注意,前面的索引说过,数据库的索引查找算法用的是B-Tree,这是O(log(n))的算法,所以,整个算法复法度应该是O(log(n)) * O(log(m)) 这样的。
- Hash式的Join,主要解决嵌套循环的O(log(n))的复杂,使用一个临时的hash表来标记。
- 排序归并,意思是两个表按照查询字段排好序,然后再合并。当然,索引字段一般是排好序的。
还是那句话,具体要看什么样的数据,什么样的SQL语句,你才知道用哪种方法是***的。
部分结果集。我们知道MySQL里的Limit关键字,Oracle里的rownum,SQL Server里的Top都是在限制前几条的返回结果。这给了我们数据库引擎很多可以调优的空间。一般来说,返回top n的记录数据需要我们使用order by,注意在这里我们需要为order by的字段建立索引。有了被建索引的order by后,会让我们的select语句的性能不会被记录数的所影响。使用这个技术,一般来说我们前台会以分页方式来显现数据,Mysql用的是OFFSET,SQL Server用的是FETCH NEXT,这种Fetch的方式其实并不好是线性复杂度,所以,如果我们能够知道order by字段的第二页的起始值,我们就可以在where语句里直接使用>=的表达式来select,这种技术叫seek,而不是fetch,seek的性能比fetch要高很多。
字符串。正如我前面所说的,字符串操作对性能上有非常大的恶梦,所以,能用数据的情况就用数字,比如:时间,工号,等。
全文检索。千万不要用Like之类的东西来做全文检索,如果要玩全文检索,可以尝试使用Sphinx。
其它。
- 不要select *,而是明确指出各个字段,如果有多个表,一定要在字段名前加上表名,不要让引擎去算。
- 不要用Having,因为其要遍历所有的记录。性能差得不能再差。
- 尽可能地使用UNION ALL 取代 UNION。
- 索引过多,insert和delete就会越慢。而update如果update多数索引,也会慢,但是如果只update一个,则只会影响一个索引表。
(2)DBCC DBREINDEX重建索引#p#
优化实战
2.1.5 静态化
静态化一些不常变的页面和数据,并gzip一下。使用nginx的sendfile功能可以让这些静态文件直接在内核心态交换,可以极大增加性能。
一般我们可以做一个静态文件管理功能,可以把我们网站的一些栏目直接通过请求/响应的方式在服务器上直接生成静态文件,当然这里可以设置一个时间频率,用户直接访问静态页面访问效率肯定非常高!
2.1.6 缓存
通常,应用程序可以将那些频繁访问的数据,以及那些需要大量处理时间来创建的数据存储在内存中,从而提高性能;它包括应用程序缓存和页输出缓存;
一般我们大部分用的是应用程序缓存
缓存的应用场景主要有:

OutputCache
我们可以用Fiddler找出一些内容几乎不会改变的页面,给它们设置OutputCache指令即可;
对于设置过OutputCache的页面来说,浏览器在收到这类页面的响应后,会将页面响应内容缓存起来。 只要在指定的缓存时间之内,且用户没有强制刷新的操作,那么就根本不会再次请求服务端, 而对于来自其它的浏览器发起的请求,如果缓存页已生成,那么就可以直接从缓存中响应请求,加快响应速度。 因此,OutputCache指令对于性能优化来说,是很有意义的(除非所有页面页面都在频繁更新)。
应用程序缓存
应用程序缓存提供了一种编程方式,可通过键/值对将任意数据存储在内存中,这里提供一个asp.net对缓存有效封装的例子,见缓存机制理解及C#开发使用。
缓存可以用来缓存动态页面,也可以用来缓存查询的数据。缓存通常有那么几个问题:
1)缓存的更新。也叫缓存和数据库的同步。有这么几种方法,一是缓存time out,让缓存失效,重查,二是,由后端通知更新,一量后端发生变化,通知前端更新。前者实现起来比较简单,但实时性不高,后者实现起来比较复杂 ,但实时性高。
2)缓存的换页。内存可能不够,所以,需要把一些不活跃的数据换出内存,这个和操作系统的内存换页和交换内存很相似。FIFO、LRU、LFU都是比较经典的换页算法。
3)缓存的重建和持久化。缓存在内存,系统总要维护,所以,缓存就会丢失,如果缓存没了,就需要重建,如果数据量很大,缓存重建的过程会很慢,这会影响生产环境,所以,缓存的持久化也是需要考虑的。















