自从2007年Facebook提出Apache Hive和HiveQL后,他们已经成为事实上的Hadoop上的SQL接口。如今,各种类型的大公司或小公司都在使用Hive这中非常普遍的方法来访问Hadoop数据,从而给公司或者用户带来更多的价值。同时,还有许多公司通过大量已存的BI工具生态系统来达到相同的目的,这些BI工具同样使用Hive作为接口。
最初,Hive用于建立大规模的成批计算,这在数据报告、数据挖掘以及数据准备等应用场景很有效。这些应用场景很重要,但是Hadoop的需求十分广阔,企业用户越来越需要Hadooop具备更高的实时性和交互性。在Hortonworks,我们相信开源社区的创新力要超过任何一个专有的提供商,Stinger initiative再次证明了这一点,我们会联合(社区)伙伴一起提升Hive的性能。
什么是Stinger Initiative?
能让Hive回答问题的速度满足普通人(例如一个问题的返回时间在5-30秒),如大数据探索、可视化、参数化报告等场景,而且并不依赖其它工具,并分发到用户社区,可以很好的维护企业原有的投资和开发者的Hive技能。
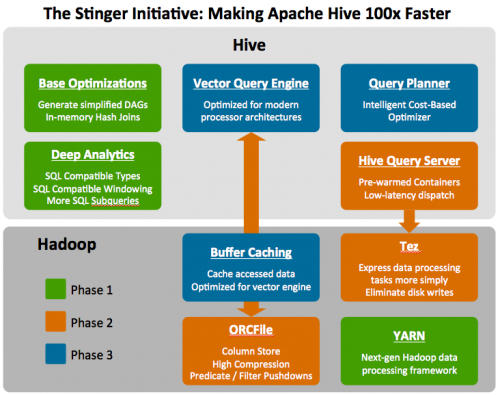
图:Stinger Initiative的roadmap
为此,我们发布了Stinger Initiative,并进入社区进行分享,为的是让Hive支持更多SQL,并实现更好的性能。一直以来,HiveQL都没有什么变化,而这次HiveQL将变得更强大。同时,与现有的工具保持一致形成***的互补。
首先,我们让Hive与人们在Hadoop上想要的查询想匹配。这包括增加类似OVER子句的分析功能,支持WHERE子查询,以及调整Hive的样式系统更多的符合标准的SQL模型。
其次,我们优化了Hive的请求执行计划,我们内部某些测试结果显示,优化后的请求时间减少了90%。我们也着眼于在Hive执行引擎中增加一些改动,我们确信这可以增加单一Hive task每秒钟处理记录的数量。
第三,我们在Hive社区中引入了新的列式文件格式(如ORC文件),提供一种更现代、高效和高性能的方式来储存Hive数据。
***,我们引入了一种新的runtime框架—— Tez,它的目标是消除Hive的延迟以及吞吐量限制。Tez通过消除不必要的task、障碍同步和对HDFS的读写作业来优化Hive job。这将优化Hadoop内部的执行链,彻底加速Hive负载处理。
所有这些对Hive的调整仍在公开的进行中,内部预览版将在今年三月举行的由Hortonworks主办的Hadoop大会上公开。
拥抱社区和Hive
许多不同的团队在Hive社区贡献着他们成果。来自SAP的Harish Butani的团队负责为Hive增加一个分析和数据窗口函数。这个函数将增加到OVER子句中用于已经存在的聚集函数,就像RAND、NTILE和LEAD、LAG等函数一样, 这里可以看到详细的说明。Facebook的Namit Jain已经花了大量时间来优化Hive的查需执行计划,这让Join等操作变的更高效,并减少来自用户的提示。Hortonworks已经参与到这些项目中。
Owen O’Malley,Hortonworks联合创始人,早期的Hadoop的开发者,已经在Facebook为ORC文件格式进行了大量工作,这项工作将帮助提升Hive读、写、处理数据的性能,在 这里可以看到详情。我们还在为一些更长远的目标工作,如重写Hive的运算符来处理上千的记录,其效率和现在相比将有大幅提升。
为什么要重新造轮子呢?