某台「Nginx / PHP」服务器时不时出现HTTP服务卡住的现象。
开始我怀疑PHP有问题,但是通过查询Nginx的access日志,发现里面记录的PHP响应时间「$upstream_response_time」非常小,此外还通过Strace命令仔细核对了是否存在耗时的操作,结果一无所获,所以基本排除了PHP的嫌疑。
接着我把目光转移到了Nginx身上,琢磨着是不是Nagle算法导致的网络延迟,不过Nginx缺省就通过「tcp_nodelay」指令关闭了Nagle算法,所以基本排除了Nginx的嫌疑。
既然Nginx和PHP都有不在场的证据,那会不会是Linux内核参数的问题呢?因为这台Web服务器前面有NAT方式的LVS,所以如果「tcp_timestamps」和「tcp_tw_recycle」等内核参数设置不当的话,会导致网络故障,可是通过检查再次否定了这个推断。
问题到了这里似乎陷入了僵局,看来瞎蒙是没戏了,只好硬着头皮用tcpdump了,说硬着头皮是因为我这个山寨OPS对TCP协议实在是不熟悉,但是为了解决问题,只能赶鸭子上架了,找一个客户端重现故障,然后在服务端监听:
shell> tcpdump -i eth0 host <CLIENTIP> and port 80- 1.
不出意外是一大堆天书般的结果,一句话:法海你不懂爱。好在菜鸟有菜鸟的玩法,祭出神器:Wireshark,可以通过它来可视化分析tcpdump生成的日志文件:
shell> tcpdump -w /path/to/log -i eth0 host <CLIENTIP> and port 80- 1.
本例中最终的效果图大致如下所示:
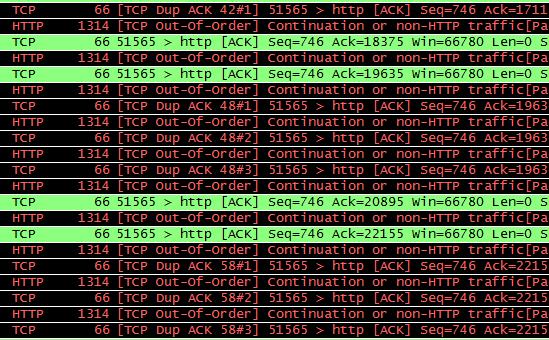
通过wireshark分析tcpdump结果
黑色一看就有问题,果断搜索:TCP Dup ACK,TCP Out-Of-Order,结果发现此类问题基本都意味着网络状况不好,推测网络可能存在丢包。
如何判断网络是否存在丢包呢?非常简单,通过常用的「ping」命令即可:
shell> ping -f <IP>- 1.
关于其中的「-f」选项,在手册中是这样解释的:
Flood ping. For every ECHO_REQUEST sent a period “.” is printed, while for ever ECHO_REPLY received a backspace is printed. This provides a rapid display of how many packets are being dropped. If interval is not given, it sets interval to zero and outputs packets as fast as they come back or one hundred times per second, whichever is more. Only the super-user may use this option with zero interval.
简单点说:发送洪水请求,每个请求打印一个点,每个响应删除一个点。如果网络存在丢包,那么会呈现出一长串不断增加的点,简单易用,童叟无欺。
…
最终确认了网络确实存在丢包。总算抓住了真凶,对一个山寨的OPS来说,问题分析到这里就算差不多了,至于为什么会丢包的问题,可能是网线的问题,也可能是网卡的问题,还可能是带宽的问题,等等等等,这些就留给真正的OPS去折腾吧。