【2013年2月21日 51CTO外电头条】使用信用卡进行的支付数量巨大。很显然,分析所有交易后得到的数据本身就有固有的价值。客户忠诚、人口统计数据、活动热图、商店推荐以及其他许多统计数字对客户和店家来说都很有用,店家可用来改进与市场的关系。在Datasalt,我们联合西班牙毕尔巴鄂比斯开银行(BBVA)开发出了一款系统,能够分析多年来的数据,并且提供不同的低延迟Web和移动应用程序方面的洞察力和统计数字。
除了处理大数据输入外,我们面临的主要挑战在于,输出的也是大数据,而且比输入的大数据还要庞大。而且必须在高负载环境下,迅速提供这种输出。
我们开发的解决方案其基础设施成本每月只有几千美元,这归功于使用了云服务(AWS)、Hadoop和Voldemort。我们会在下文解释这个提议架构的几个主要特点。
数据、目标和首要决策
系统使用BBVA银行在全球各地商店进行的信用卡交易,作为用来分析的输入源。很显然,数据是匿名的、非个人的、分离的,目的是为了防止出现任何隐私问题。信用卡号经过了散列处理,故意弄乱。任何因而得到的洞察力始终是聚合信息,所以无法从中获得任何个人的信息。
我们计算了每家商店、每个不同时间段的许多统计数字和数据。下面是其中一些:
■每家商店的支付数额的直方图
■客户忠诚
■客户人口统计数据
■商店推荐(在此购物的客户还在…购物)。按地点和商店类别等标准来过滤。
该项目的主要目标是,通过低延迟的Web和移动应用程序,把这一切信息提供给不同的代理人(商店和客户)。所以一个很高的要求就是,能够在高负载情况下提供结果,而延迟不到1秒。又由于这是个研究项目,需要兼顾代码和需求方面的高度灵活性。
由于每天只更新一次数据不是问题,我们选择了一种面向批处理的架构(Hadoop)。我们还选择了Voldemort,作为只读存储区,用于提供Hadoop生成的洞察力;Voldemort是一种简单而超快速的键/值存储区,与Hadoop整合得很好。
平台
系统搭建在亚马逊网络服务(AWS)的环境上。具体来说,我们使用简单存储服务(S3)来存储原始输入数据,使用Elastic Map Reduce(亚马逊提供的Hadoop)用于分析,使用弹性计算云(EC2)来提供结果。使用云技术让我们得以实现快速迭代,迅速交付实用原型,这正是我们对这种项目提出的要求。
架构
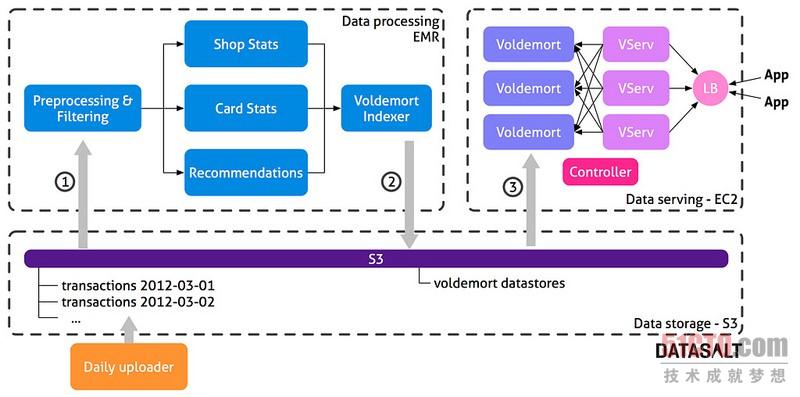
架构有三个主要部分:
■数据存储:用于维护原始数据(信用卡交易)和因而获得的Voldemort存储区。
■数据处理:在Elastic Map Reduce上运行的 Hadoop工作流程执行所有计算,并创建Voldemort所需的数据存储区。
■数据提供:Voldemort集群从数据处理层提供预计算的数据。
该银行每天把当日进行的所有交易上传到S3中的一个文件夹中。这让我们得以保留所有的历史数据——每一天进行的所有信用卡交易。所有这些数据是处理层的输入部分,所以我们重新计算一切,每天都是如此。重新处理所有数据让我们得以非常敏捷灵活。要是需求发生变化,或者要是我们找到了一个愚蠢的错误,我们只需更新项目代码,下一次批处理后,所有数据都得到了修复。这个开发决策为我们带来了:
■简化的代码库及架构;
■灵活应对变化的能力;
■易于处理人为错误的能力(只要修复错误,重新启动过程)。
控制器启动Elastic Map Reduce上的新Hadoop集群,并启动处理流程,每天执行一次。这个流程由大约16个计算不同洞察力的Tuple MapReduce作业(http://www.datasalt.com/2012/02/tuple-mapreduce-beyond-the-classic-mapreduce/)组成。流程的***一个部分(Voldemort检索器)负责创建数据存储区文件,这些文件以后将部署到Voldemort。一旦该流程完成,因而获得的数据存储区文件将上传到S3。控制器关闭Hadoop集群,并将部署请求发送到Voldemort。然后,Voldemort从S3下载新的数据存储区,并执行热交换操作,完全更换旧的数据存储区。
技术
Hadoop和Pangool
整个分析和处理流程使用基于Hadoop上的Pangool作业(http://pangool.net/)来实现。这让我们很好地兼顾了性能、灵活性以及敏捷性。使用tuples让我们得以使用简单的数据类型(int和string),在流程之间传输信息;与此同时,我们可以添加其他的复杂对象(比如直方图),连同它们自己的自定义序列化。
此外,由于Pangool仍是一种低级API(应用编程接口),我们可以在需要时,对每一个作业进行多次微调。
Voldemort
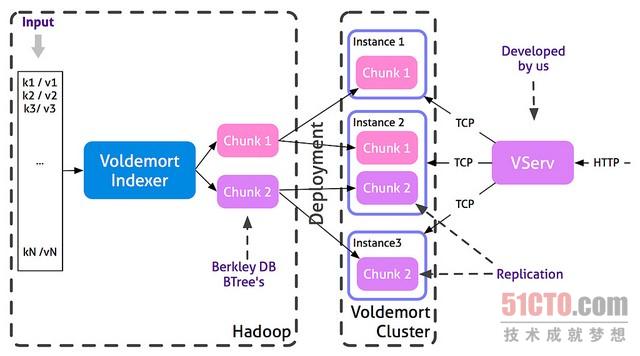
Voldemort是由LinkedIn开发的一种键/值NoSql数据库,基于亚马逊的Dynamo(http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html)概念。
Voldemort背后的主要想法是,把数据分成多个部分。每个部分在Voldemort集群的节点中加以复制和提供。每个Voldemort守护程序都能将查询传送到为某一个键保留值的那个节点。Voldemort支持快速读取和随机写入,但是就这个项目而言,我们使用Voldemort作为只读数据存储区,在每个批处理过程后更换所有数据部分。由于数据存储区由Hadoop预先生成,查询服务并不受部署过程的影响。这是使用这种只读批处理方法的优点之一。我们还可以根据需要,灵活地更改集群的拓扑结构,并重新均衡数据。
Voldemort提供了Hadoop MapReduce作业,可以在分布式集群下创建数据存储区。数据的每个部分只是Berkeley DB B树(http://en.wikipedia.org/wiki/B-tree)。
Voldemort的接口是TCP,但我们希望使用HTTP来提供数据。VServ是一种简单的HTTP服务器,可以把进入的HTTP请求转变成Voldemort TCP请求。负载均衡系统负责在所有VServ之间分配查询。
经过计算的数据
统计数字
分析过程的一个环节包括计算简单的统计数字:平均值、***值、最小值、标准差、独特的计数等。它们使用众所周知的MapReduce方法来实现。但我们还计算了一些直方图。为了使用Hadoop高效地实现它们,我们创建了一种自定义直方图,只需要一遍就可以计算。此外,我们还能计算每次交易的所有简单统计数字以及与之相关的直方图,只要使用一个MapReduce步骤,可以是随意的时间段。
为了减少直方图所使用的存储量,并且改进可视化,许多颜色区间(bin)形成的原始的计算直方图被转换成颜色区间宽度可变的直方图。下列图表显示了某个直方图的3个颜色区间的***直方图。
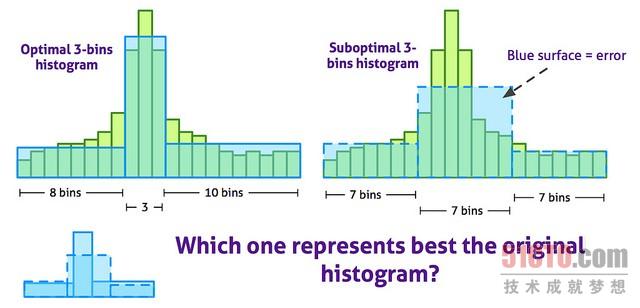
***直方图使用一种随机重复爬山法(random-restart hill climbing)近似算法来计算。下列图表显示了每一次爬山迭代过程中可能出现的变化:
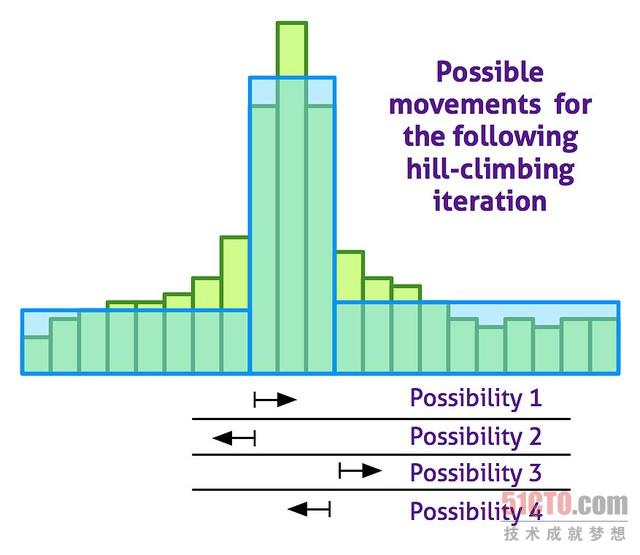
事实证明这种算法非常快速、非常准确:与精确的动态算法相比,我们获得了99%的准确性,而速度提高了一倍。
商务方面的推荐
使用同现(co-ocurrences)来计算推荐。也就是说,如果某人在A商店和B商店都购买了东西,那么A商店与B商店之间就存在一种同现。即使顾客在A商店和B商店都购买了数次,被考虑进来的也只有一次同现。
但需要对这个简单的同现概念加以一些改进。首先,使用一种简单的频切方法(frequency cut),将***的商店过滤出来,因为差不多每个人都在这些商店购物。所以推荐它们毫无意义。可以按地点(彼此挨得很近的商店)、商店类别或这两者过滤推荐,这也有助于改进推荐。基于时间的同现形成了更热门的推荐与“总是适用”的推荐。限制同现可能出现的时间带来了这种商店推荐:人们在***家商店购物后马上到第二家商店购物。
Hadoop和Pangool是计算同现、生成推荐的***工具,不过一些挑战并不容易克服。尤其是,如果一个顾客在多家商店支付,该信用卡的同现数量就会呈平方增长,使得分析不呈现线性扩展。由于这是罕见情况,我们完全限制了每张卡的同现数量,只考虑顾客买得最多的情况。
成本和一些数据
就BBVA一年下来在西班牙的信用卡交易而言,用Voldemort提供的信息量是270 GB。整个处理流程在24个亚马逊EC2“m 1.large”实例组成的集群上需要耗时11个小时才完成。整套基础设施(包括提供随后数据所需的EC2实例)成本约为每个月3500美元。
仍然存在有待优化的空间。但是考虑到该解决方案敏捷、灵活,而且在云端,价格相当合理。在一套内部基础设施上运行的系统其成本将会低得多。
结论与展望
由于使用了Hadoop、亚马逊网络服务和NoSQL数据库等技术,有可能迅速开发出这样的解决方案:具有可扩展性和灵活性,准备经受得住人为失误,而且成本合理。
未来的工作将包括把Voldemort换成Splout SQL(http://sploutsql.com/),这便于部署Hadoop生成的数据集,并将低延迟键/值扩展到低延迟SQL。这将缩短分析时间以及提供的数据量,因为许多聚合可以“实时”执行。比如说,它允许在任意时间段进行聚合统计分析,如果进行预先计算是不可能实现的。