《Hadoop 权威指南》上用这么一句话来描述HDFS:
HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.
有几个关键性的词组:Very large files,Streaming data access,以及Commodity hardware。解下来一个一个解释。
① Very large files
在Hadoop中,“very large”是多大?运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。现如今,已经有不少的企业,存储在HDFS上的数据,已经超过了PB的级别,例如淘宝。
② Streaming data access
HDFS的设计的理想用法是一次写入,多次读取。这种方式的使用是最高效的。运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量,所以,从这方面来说,读取整个数据的时间延迟要比读取到第一条记录的数据延迟更重要(这一点很重要,这一思想,将在《HDFS学习(二) – HDFS Block介绍》中说明)。
③ Commodity hardware
Hadoop适合部署在廉价的机器上,即普通的机器上,不需要时昂贵且高可靠的机器。这样的话,机器节点的故障几率就会非常高。所以,Hadoop是一个高度容错的系统,错误检测和快速、自动的恢复是HDFS最核心的架构目标。Hadoop出现故障时,被设计成能够继续进行且不让用户察觉。
综上,HDFS是一个不错的分布式文件系统,但是,HDFS也有其不适合的场合,也有其缺点:
① 低延时数据访问
HDFS不太适合于要求低延时(数十毫秒)访问的应用程序,因为HDFS是设计用于高吞吐量数据访问的,这就需要以一定的延时为代价。而对于那些有低延时要求的应用程序,HBase是一个更好的选择。HBase的口号就是“Use Apache HBase when you need random, realtime read/write access to your Big Data”。
② 大量的小文件
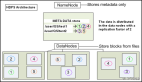
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有1000万个文件,每一个占据一个Block,你就至少需要2G内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,我们就需要几十G的内存。这样算来,Namenode内存,就严重制约了集群的扩展。
还有一个问题就是,因为Map task的数量是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。举个例子,处理10000M的文件,若每个split为1M,那就会有10000个Map tasks,会有很大的线程开销;若每个split为100M,则只有100个Map tasks,每个Map task将会有更多的事情做,而线程的管理开销也将减小很多。
对于第一问题,最新版本的Hadoop已经有了解决方案:HDFS Federation,将在《HDFS学习(四) – HDFS Federation》做详细介绍。
对于第二个问题,Hadoop本身也提供了一定的解决方案,将在《Hadoop学习(五) – 小文件处理》做详细介绍。
③ 多用户写,任意文件修改
目前Hadoop只支持单用户写,不支持并发多用户写。可以使用Append操作在文件的末尾添加数据,但不支持在文件的任意位置进行修改。《Hadoop 权威指南》第三版上说,现在尚无对这方面的支持。
Files in HDFS may be written to by a single writer. Writes are always made at the end of the file. There is no support for multiple writers or for modifications at arbitrary offsets in the file. (These might be supported in the future, but they are likely to be relatively inefficient.)
原文链接:http://shitouer.cn/2012/12/hdfs-design-introduction/
【编辑推荐】