对于比较复杂的互联网应用业务场景,比如海量数据商品搜索、广告点击算法、用户行为挖掘、关联推荐模型等等,由于数据量极大,对于数据处理的速度会要求非常高。要大幅提升算法的效率,最直接的方法就是:使用并行计算。
但是,并行计算有一个很大的问题:传统的程序都是基于单机编写的。要更改为多机并行的程序,需要耗费较大的学习成本。尤其在真实的场景当中,业务本身很复杂,初学者一头扎进去,容易绕晕了头。
因此,我们需要一个通俗易懂的例子来直接看到并行计算的优势。
下面,淘宝网高级专家千峰就编写了这样的一个例子,51CTO受邀将这篇文章分享给大家。
文章概述
问题:
请写一个程序,输入M,然后打印出M个数字的所有排列组合(每个数字为1,2,3,4中的一个)。比如:M=3,输出:
1,1,1 1,1,2 …… 4,4,4
共64个
注意:这里是使用计算机遍历出所有排列组合,而不是求总数,如果只求总数,可以直接利用数学公式进行计算了。
传统的单机解决方案:
1)单机递归
将n(1<=n<=4)看做深度,输入的m看做广度。当m数字很大时,会超出单台机器的计算局限导致缓慢。
2)单机迭代
求m个数字的排列组合,实际上都可以在m-1的结果基础上得到。但是,当m=14的时候,结果已经上亿了。无论以什么格式存,最终在单机上都会内存溢出。
分布式并行计算解决方案:
1)多机递归
这是本篇文章的重点。
核心思想:重新设计算法,按多机进行拆分和合并,利用并行计算优势去完成结果。
按照并行计算的算法,n台计算机可以将递归降一级,n*n台计算机可以将递归降两级。理论上,只要机器足够多,就能持续降低递归的复杂度。
运行步骤:
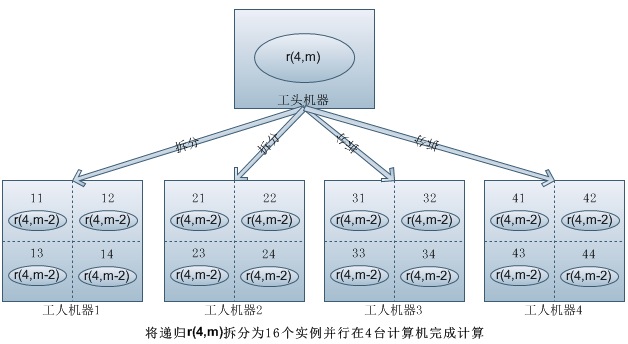
使用fourinone框架设计分布式并行计算。整个框架通过一个ParkServerDemo做整体的工人注册和分布式协调,中间有作为包工头的CombCtor(分配工作+统计结果),最下面有多个CombWorker作为工人实现(干活儿+返回结果)。
文中有多机递归实现的完整代码。
2)多机迭代
本文提供了三个多机迭代的思路。相对多机递归的方式,多机迭代的方式在这个例子中并不高效,因此没有提出实现方式。