你有可能也会遇到这种情况,公司没有任何安全设备,也没有资金采购,应付层层攻击,那么作为公司唯有一个安全工程师,如何来自动化保障公司的web安全呢?
下面,结合我的一些经验,说说一些实际操作。由于全部是手工,维护web安全来做到实时过滤安全攻击,那必须在web服务器前方做一个代理,或者在代码层有一个代理
层,实时的检测过来的请求,再传给应用,这涉及到编写web应用防火墙呢,相对而言,对一个独立安全工程师比较复杂,简单一点的呢?
其实,退而求其次,我当时做法分两步走,第一步我是做自动化巡检。第一次服务器的安全巡检,网络上有一些checklist,这就不列举了,不是本文重点,对每个核心
服务器一开始做一次全面详细的checklist检查,修复后,基本能做到基准安全了。接下来,就是要每日巡检了。那么巡检的主题是什么呢?关键文件的变更。我当时使用的ruby,
核心代码改编于网上:
#ruby比较两个文件
def cmpfile(source_file,tmp_file,security_type)
num=0
f1=File.open(source_file)
f2=File.open(tmp_file)
if !File.zero?("source_file") and !File.zero?("tmp_file") then
num1,f1array=getFileLine(f1)
num2,f2array=getFileLine(f2)
#ensure the numberof loop
if num1>num2
num=num1
else
num=num2
end
for i in(0..num-1)
mesg1="Exception:Maybe file"
mesg2="was not enough lines. Cant find the data when check line"
if f1array[i] != nil and f2array[i] != nil
if f1array[i] != f2array[i]
$rrp.write("\n--#{security_type}--num:"+i.to_s+"\n"+"source_file: "+f1array[i].to_s+"\n"+"new_file: "+f2array[i].to_s)
end
else
if f1array[i] = nil
$rrp.write("\n--#{security_type}--num:"+i.to_s+" "+mesg1+'1'+ mesg2+(i+1).to_s)
break
else if f2array[i] = nil
$rrp.write("\n--#{security_type}--num:"+i.to_s+" "+mesg1+'2'+ mesg2+(i+1).to_s)
break
else
break
end
end
end
end
end
f1.close
f2.close
end
def getFileLine(f)
farray=[]
num=0
f.each do |fi|
num+=1
farray+=[fi.strip]
end
return num,farray
end
我的思路即是,把所有需要监控的东西,保留一个最初的原始文件,存于一个专门的文件夹内,每次巡检,通过如下:
#执行命令 提取源信息
def cmd_source(cmd,source_path_file)
cont=`#{cmd}`
if !File.exist?(source_path_file)
File.new(source_path_file,"w").write(cont)
end
end
#执行命令 提取临时信息
def cmd_tmp(cmd,tmp_path_file)
cont=`#{cmd}`
File.new(tmp_path_file,"w").write(cont)
end
这样,每次手工检测执行命令的结果都存在专门文件里,跟原始文件进行对比(内容对比函数见上)。于是,再稍微优化整理一下,一个自动化的检测脚步就执行了,
具体可以以一周为期限或碰到特殊情况变更原始文件,将新的标准文件换为原始文件进行对比。做定时任务,每5分钟左右执行一次检测,那么一旦出现文件变更,挂马等
则立刻能在生成的变更报告文件里检测出来。
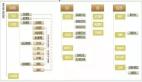
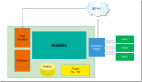
前期个人这样搞了1个月,工作轻松很多,后来公司有一个哥们用ruby比较熟,于是公司需求做一个ruby的风险监控系统,那么,下面就是本文重点了,这个风险监控系统
关键点就是把实施检测的信息,发送给后端,显示。我们用的消息平台是amqp。先说一下整体思路,然后下面见核心代码解释。风险监控系统,可以将手工检测生成的报文信息
与日志里重要的关键信息进行提取整理,发送给后端,后端根据得到的数据进行图形或表格等不同展现。这分为三部分。信息的来源:原始日志与前期自动化检测生成的信息;
信息的分析:对分析进行整理,取出含有关键字的特殊信息进行分类分级,放在不同管道里,发给后台;信息的展现:后台先将发来的信息存于数据库,再根据需要取出数据库进行
图形或表格形式展现。
其实这个进行详细改编和优化,就是一个完整的soc系统了,目前国内的soc系统也不外如此,却要买几十万甚至上百万,甚鄙视之。其实soc核心的关键是规则关联和
设备联动,就是在咱们信息分析这一部分,定义大量规则进行各种日志关联分析,这个我在自己的程序里没做,当时就只搞apache、resin日志分析,都是些简单的,整个系统
花了一两个星期跟另一个工程师配合上线,运行正常,后种种情况,搁置,但是给一些孤独工程师提供一下借鉴思路,还是能省一些事情,希望能给一些人有所帮助。下面看
代码,不多说:
#! /usr/local/ruby/bin/ruby
=begin
author:kn1ghtc
describe:that's true
=end
require 'rubygems'
require 'amqp'
#ruby是一时心血来潮搞了一下,其实还是不大懂,刚看完一本书就写了这个,所以有很多山寨用法,大牛勿笑,服务器上存的日志按时间每天自动追加到下面几个文件,
#咱们先定义一下几个变量,取源文件路径
$con_source_path_ssl="../../access_ssl_#{Time.now.strftime("%Y%m%d")}.log"
$con_source_path_access="/../access_#{Time.now.strftime("%Y%m%d")}.log"
$con_source_path_error="/../error_#{Time.now.strftime("%Y%m%d")}.log"
#定义几个变量,存一些规则过滤后的文件内容,这里图简便,人为分配了四个等级和方向,读者可自行优化规则和分类
$tmp_scan=[]
$tmp_attack=[]
$tmp_app=[]
$tmp_abnormal=[]
#服务器上日志格式有自己生成的规则,没关系,我们按我们的需要标准化成我们的格式,便于后面分析规则应用与存储展现
#log_format
def message_format(str_line,str_type,str_risk,str_format)
@str_time=""
@str_ip=""
@str_data=""
@str_result=""
@str_format=str_format
@str_line=str_line
if @str_format=="error"
@str_time=/[a-zA-Z]{3}.[a-zA-Z]{3}.\d{2}.\d{2}:\d{2}:\d{2}.\d{4}/.match(@str_line)
@str_ip=/\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}/.match(@str_line)
@str_data=@str_line.gsub(/^\[[a-zA-Z]{3}.[a-zA-Z]{3}.\d{2}.\d{2}:\d{2}:\d{2}.\d{4}\].\[[a-zA-Z]{3,5}\].\[[a-zA-Z]{6}.\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\]/,"").strip
else
@str_time=/\d{2}\/[a-zA-Z]{3}\/\d{4}:\d{2}:\d{2}:\d{2}/.match(@str_line)
@str_ip=/^\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}/.match(@str_line)
@str_data=@str_line.gsub(/^\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}.....\[\d{2}\/[a-zA-Z]{3}\/\d{4}:\d{2}:\d{2}:\d{2}.\+\d{4}\]/,"").strip
end
@str_result=@str_ip.to_s+"=>"+@str_data.to_s+"=>"+@str_time.to_s+"=>"+str_type+"=>"+str_risk+"\n"
end
#取出日志里的每一行,放进下面的函数,设定规则,匹配规则的放进相应数组里
#line_rule_match
def line_rule(rule_line,rule_log_type)
@rule_str_line=rule_line
@rule_log_type=rule_log_type
@new_line=""
@rule_data=[]
if @rule_str_line=~/error/
$tmp_abnormal<<message_format(@rule_str_line,"abnormal","M",@rule_log_type)
else
@new_line=message_format(@rule_str_line,"unknown","unknown",@rule_log_type).split(/=>/)[1]
@rule_data=@new_line.split(/"/)
if @rule_data.size>6
$tmp_scan<<message_format(@rule_str_line,"scan","M",@rule_log_type)
else
if @rule_data.size>1
if @rule_data[3]=~/script>|<script|passWord|password/
$tmp_attack<<message_format(@rule_str_line,"attack","H",@rule_log_type)
#做了一些状态号检测
elsif @rule_data[1]=~/'|alert|script>|cat|union|order by|;|\.\.\/|and|--/ or @rule_data[2].lstrip.split(/\s/)[0]=~/400|403|404|500/
$tmp_scan<<message_format(@rule_str_line,"scan","M",@rule_log_type)
end
end
end
end
end
#log_ids
def invade_log(source_path_file,log_type)
@path_source=source_path_file
@log_type=log_type
i=0
@line_num_tmp=-1 www.hack6.com
#山寨想法,当时各种服务器性能限制和原因,所有为了实时取日志内容(web日志是实施增加的),服务器上设置定时任务,每隔1分钟运行一次脚本
#每1分钟运行咱们的脚本,脚本便从建立的特殊文件夹里找特殊文件,文件里生成这次检测原文件的行号,对比行号,从新行号开始往下扫描,原后存行号
if @log_type=="ssl"
File.open("/tmp/num_ssl","r") do |file|
@line_num_tmp=file.gets.to_i
end
elsif @log_type=="access"
File.open("/tmp/num_access","r") do |file1|
@line_num_tmp=file1.gets.to_i
end
else
File.open("/tmp/num_error","r") do |file2|
@line_num_tmp=file2.gets.to_i
end
end
File.open(@path_source) do |files|
files.each_line do |line|
begin
line.force_encoding("gbk")
if i>@line_num_tmp
line_rule(line,@log_type)
else
i=i+1
next
end
i=i+1
rescue
i=i+1
$tmp_app<<message_format(line,"app","L",@log_type)
end
end
end
@line_num_tmp=i
@file_log=File.open("/tmp/num_#{@log_type}","w")
@file_log.write(@line_num_tmp)
@file_log.close
end
#行号文件,解决实施检测的问题
#time_question
#implement_method
def implement_meth(source_path_file,log_type)
@im_path_source=source_path_file
@im_log_type=log_type
@filename_old=""
if File.exist?(@im_path_source)
File.open("/tmp/time_#{@im_log_type}") do |file|
@filename_old=file.gets.to_s.strip
end
if @im_path_source!=@filename_old
@im_file_log=File.open("/tmp/num_#{@im_log_type}","w")
@im_file_log.write("-1")
@im_file_log.close
@im_file_log=File.open("/tmp/time_#{@im_log_type}","w")
@im_file_log.write(@im_path_source)
@im_file_log.close
end
invade_log(@im_path_source,@im_log_type)
end
end
#mq消息的应用,定义信道相关信息,这里基本格式都是这样,很好修改为自己的
#send_message_method_scan
def send_to_exchange_scan(message)
exchange=MQ.direct('guofubao')
exchange.publish message,:key=>'scan'
end
#send_message_method_atack
def send_to_exchange_attack(message)
exchange=MQ.direct('guofubao')
exchange.publish message,:key=>'attack'
end
#send_message_method_app
def send_to_exchange_app(message)
exchange=MQ.direct('guofubao')
exchange.publish message,:key=>'app'
end
#send_message_method_abnormal
def send_to_exchange_abnormal(message)
exchange=MQ.direct('guofubao')
exchange.publish message,:key=>'abnormal'
end
#test_data
#tmp_test="127.0.0.1=>kn1ghtc_test=>2012:12:31=>unknown=>unknown"+"\n"
#implement
implement_meth($con_source_path_access,"access")
implement_meth($con_source_path_error,"error")
implement_meth($con_source_path_ssl,"ssl")
#conn
#应用消息发送和方法体
AMQP.start :host => '127.0.0.1', :port => 5672 do
event_loop=Thread.new do
EM.run do
EM.add_timer(1) do
EM.stop
end
end
end
send_to_exchange_abnormal $tmp_abnormal.join().to_s
send_to_exchange_app $tmp_app.join().to_s
send_to_exchange_attack $tmp_attack.join().to_s
send_to_exchange_scan $tmp_scan.join().to_s
event_loop.join
end
结束:个人比较懒,当时写的比较仓促,主体思路都在上面,后面系统因为其它原因下线,几个月前写的,现在也只记得思路,觉得有用的看官自己缕一缕吧。