HBase设计:看上去很美
HBase是模仿Google bigtable的开源产品,又是hadoop的衍生品,hadoop作为离线计算系统已经得到业界的普遍认可,并经过N多公司大规模使用的验证,自然地认为HBase也将随之获得成功。
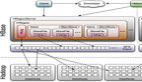
《HBase: The Definitive Guide》第8章讲述HBase的架构,从架构上看,其架构很***:
LSM - 解决磁盘随机写问题(顺序写才是王道);
HFile - 解决数据索引问题(只有索引才能高效读);
WAL - 解决数据持久化(面对故障的持久化解决方案);
zooKeeper - 解决核心数据的一致性和集群恢复;
Replication - 引入类似MySQL的数据复制方案,解决可用性;
此外还有:自动分拆Split、自动压缩(compaction,LSM的伴生技术)、自动负载均衡、自动region迁移。
看上去如此美好,完全无需人工干预,貌似只要将HBase搭建好,一切问题HBase都将应对自如。面对如此***的系统,不动心很难。
但是,如此***的系统或许也意味着背后的复杂性是不容忽略的。HBase的代码量也不是一星半点的。假如系统工作不正常,谁来解决?这是至关重要的。
性能与测试
HBase系统自身提供了性能测试工具:./bin/HBase org.apache.hadoop.HBase.PerformanceEvaluation,该工具提供了随机读写、多客户端读写等性能测试功能。根据工具测试的结果看,HBase的性能不算差。
对于HBase这样的系统长期稳定运行比什么都重要。然而,这或许就不那么"***"。
测试版本:HBase 0.94.1、 hadoop 1.0.2、 jdk-6u32-linux-x64.bin、snappy-1.0.5.tar.gz
测试HBase搭建:14台存储机器+2台master、DataNode和regionserver放在一起。
HBase env配置:
- ulimit -n 65536
- export HBASE_OPTS="$HBASE_OPTS -XX:+HeapDumpOnOutOfMemoryError -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode"
- export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xmx20g -Xms20g -Xmn512m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSIn
- itiatingOccupancyFraction=60 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.lo
- g"
HBase-size.xml关键配置(根据《HBase: The Definitive Guide》第11章优化):
- <property>
- <name>hbase.regionserver.handler.count</name>
- <value>16</value>
- <description>Count of RPC Listener instances spun up on RegionServers.
- Same property is used by the Master for count of master handlers.
- Default is 10.
- </description>
- </property>
- <property>
- <name>hbase.regionserver.global.memstore.upperLimit</name>
- <value>0.35</value>
- <description>Maximum size of all memstores in a region server before new
- updates are blocked and flushes are forced. Defaults to 40% of heap
- </description>
- </property>
- <property>
- <name>hbase.regionserver.global.memstore.lowerLimit</name>
- <value>0.3</value>
- <description>When memstores are being forced to flush to make room in
- memory, keep flushing until we hit this mark. Defaults to 35% of heap.
- This value equal to hbase.regionserver.global.memstore.upperLimit causes
- the minimum possible flushing to occur when updates are blocked due to
- memstore limiting.
- </description>
- </property>
- <property>
- <name>hfile.block.cache.size</name>
- <value>0.35</value>
- <description>
- Percentage of maximum heap (-Xmx setting) to allocate to block cache
- used by HFile/StoreFile. Default of 0.25 means allocate 25%.
- Set to 0 to disable but it's not recommended.
- </description>
- </property>
- <property>
- <name>zookeeper.session.timeout</name>
- <value>600000</value>
- <description>ZooKeeper session timeout.
- HBase passes this to the zk quorum as suggested maximum time for a
- session (This setting becomes zookeeper's 'maxSessionTimeout'). See
- http://hadoop.apache.org/zookeeper/docs/current/zookeeperProgrammers.html#ch_zkSessions
- "The client sends a requested timeout, the server responds with the
- timeout that it can give the client. " In milliseconds.
- </description>
- </property>
- <property>
- <name>hbase.zookeeper.property.tickTime</name>
- <value>60000</value>
- </property>
- <property>
- <name>hbase.regionserver.restart.on.zk.expire</name>
- <value>true</value>
- </property>
- <property>
- <name>hbase.hregion.majorcompaction</name>
- <value>0</value>
- <description>The time (in miliseconds) between 'major' compactions of all
- HStoreFiles in a region. Default: 1 day(86400000).
- Set to 0 to disable automated major compactions.
- </description>
- </property>
- <property>
- <name>hbase.hregion.max.filesize</name>
- <value>536870912000</value>
- <description>
- Maximum HStoreFile size. If any one of a column families' HStoreFiles has
- grown to exceed this value, the hosting HRegion is split in two.
- Default: 1G(1073741824). Set 500G, disable file split!
- </description>
- </property>
测试一:高并发读(4w+/s) + 少量写(允许分拆、负载均衡)
症状:1-2天后,HBase挂掉(系统性能极差,不到正常的10%)。其实并非全部挂掉,而是某些regionserver挂了,并在几个小时内引发其他regionserver挂掉。系统无法恢复:单独启regionserver无法恢复正常。重启后正常。
测试二:高并发读(4w+/s)
症状:1-2天后,HBase挂掉(系统性能极差,不到正常的10%)。后发现是由于zookeeper.session.timeout设置不正确导致(参见regionserver部分:http://HBase.apache.org/book.html#trouble)。重启后正常。
测试三:高并发读(4w+/s)
症状:1-2天后,HBase挂掉(系统性能极差,不到正常的10%)。从log未看出问题,但regionserver宕机,且datanode也宕机。重启后正常。
测试四:高并发读(4w+/s)+禁止分拆、禁止majorcompaction、禁止负载均衡(balance_switch命令)
症状:1-2天后,HBase挂掉(系统性能极差,不到正常的10%)。从log未看出问题,但regionserver宕机,且datanode也宕机。重启后正常。
测试期间,还发现过:无法获取".MATE."表的内容(想知道regionserver的分布情况)、HBase无法正确停止、HBase无法正确启动(日志恢复失败,文件错误,最终手动删除日志重启)。
其他缺陷
HBase使用JAVA开发,看上去很美的GC使用中代价可不小。HBase为了保证数据强一致性,每个key只能由一个regionserver提供服务。在下列情况下,HBase服务质量都将受损:
1) GC CMS -- CMS回收内存极其耗时,当HBase运行1-2天后,CMS可能耗时10分钟,这期间该regionserver无法服务。CMS经常被触发,这意味着HBase的服务经常会因为GC操作而部分暂停!
2) regionserver宕机 - 为了强一致性,每个key只由一个regionserver提供服务,故当regionserver宕机后,相应的region即无法服务!
3) major compaction、split不可控 - 大量磁盘操作将极大影响服务。(levelDB也需要major compaction,只是使用更加可控的方式做压缩,比如一次只有一个压缩任务。是否影响服务,待测试)
4) 数据恢复 - 数据恢复期间设置WAL log的相关操作,在数据恢复期间regionserver无法服务!
结论
或许通过研究HBase的源码可让HBase稳定运行,但从上述测试结果看:1)HBase还无法稳定长期运行;2)HBase系统很脆弱,故障恢复能力差。基于此,判断HBase还无法满足大规模线上系统的运维标准,只能放弃。考虑到HBase重启基本可恢复正常,故HBase还是可作为离线存储系统使用。
替代方案
面对大规模数据,基于磁盘的存储系统是必不可少的。google虽然公开了bigtable的设计,但未开源,但google开源了levelDB KV存储系统库(http://code.google.com/p/leveldb/)。levelDB采用C++实现,1.7版本的代码量大概2W,实现了LSM(自动压缩)、LevelFile(基本同HFile),WAL,提供了简单的Put、Get、Delete、Write(批量写、事务功能)等接口。levelDB库实现了单机单库的磁盘存储方案,开发者可根据自己需要开发定制的存储系统(比如:数据Replication、自动调度、自动恢复、负载均衡等)。
参考文献
HBase: The Definitive Guide
The Apache HBase™ Reference Guide
HBase运维碎碎念(尤其***的参考文献): http://www.slideshare.net/NinGoo/HBase-8433555