同样属于架构革新的2012
过去的2012年里,无论是AMD还是NVIDIA都在图形架构技术层面上锐意进取,为我们带来了Compute Unit以及GPU Boost等等先进的技术,这些技术对于显卡产品的推动和促进作用是显著的。但对于我们以及整个业界来说,光有这些技术的进步还远远不够。
如果孤立存在,即便再优秀再精妙的技术,也无法转变成任何对我们有益的结果。只有将这些技术系统的融合在一起,调整好彼此的关系并令其发挥最佳的效果,技术的进步才能为我们带来切实的好处。所以对技术融合在一起所形成的架构进行回顾,也就变得有意义了。
技术的进步带动了AMD及NVIDIA在GPU架构层面的进步,让2012年不仅是技术进步年,更是GPU架构进步年。先后出现的GCN和开普勒(Kepler)体系都是双方技术进步的集大成者,它们成功地将双方全部的技术进步转化成了产品性能的提升,但细化到架构内部,双方的表现却并不都是积极向好的。同样的甚至是彼此一一对应的各种先进技术所组成的Tahiti和开普勒,最终却并没有一起收获成功。
胜利者从不缺乏赞美,赞美本身对胜利者以及旁观者都没有任何意义。只有找到导致问题的本源,并从由此探究更深层次的问题,我们才能明白图形界在过去的2012年里究竟经历了些什么。友站ZOL今天就带我们一览了2012年里出现在我们面前的所有图形架构,并揭示了决定AMD/NVIDIA架构之战结局的原因。

令人眼前一亮的Tahiti
AMD从2011年年中便曝光了全新一代的GCN(Graphic Core Next)架构体系,其后陆续到来的Tahiti、Pitcairn以及Cape Verde均基于该体系。GCN的整个信息披露过程相当系统和全面。按照AMD公布的信息,GCN将会带来大量革命性的技术革新,几乎将先前AMD GPU架构的各种问题一扫而空。在这些新技术情报带来的希望中,人们迎来了GCN的首款核心——Tahiti。

GCN的Tahiti架构打开了2012显卡架构年的大门
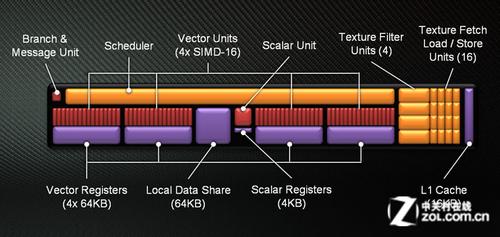
Tahiti是GCN体系的旗舰级核心,拥有超过43亿的晶体管规模。与上代的Cayman构架相比,其运算资源总量提升到了2048个流处理器,纹理拾取和载入与存储单元则提升至恐怖的512个,纹理过滤单元由Cayman的96个增加到了128个,但同时构成后端的ROP光栅单元与Cayman维持相同,均为32个。HD7970拥有全新设计的MC结构,6个64bit双通道显存控制器组合形成了全新的384bit显存控制单元,HD7970也因此采用了容量达3072MB的显存体系。

Tahiti构架特性
Tahiti架构的特色由五个主要的部分组成:
1、基于HKMG的台积电新28nm工艺。
2、包含了几何引擎、光栅化引擎以及一级线程管理机制的前端ACE( Asynchronous Compute Engine)。
3、负责处理运算任务及Pixel Shader的32个CU(Compute Unit)集群,包含在CU内部负责处理材质以及特种运算任务如卷积、快速傅里叶变换等的Texture Array,二级线程管理机制以及与它们对应的shared+unified cache等缓冲体系。
4、负责完成fillrate过程以及输出最终画面的ROP阵列,显存控制器MC(Memory Controller)以及PCI-Express3.0总线传输控制端。
5、负责视频回放及处理的UVD3.0单元,以及全新的负责视频编码部分的VCE。

HD7970构架
相对于前代的Cayman构架,Tahiti构架有了诸多触及灵魂深处的改动。它改进了Cayman的双前端并行体系,用更加灵活且效率更高的CU单元替代了强调吞吐但在效率层面显得“笨重”的VLIW Core,首次引入完善的Unified Cache并大幅改进了过往架构带有明显缺陷的缓冲体系,进一步强化了任务管理、仲裁机制以及架构的几何处理能力。
Tahiti所做出的一系列改进不仅明快而且目的性强烈,它扭转了AMD“以吞吐换延迟”的错误GPU架构方向,补完了先前架构的种种缺失并一扫AMD传统GPU架构笨拙且低效的痼疾,非常积极地迎合了DirectX 11对运算灵活度和效率的要求,将整个架构的运算和动作效率提升到了全新的高度,更为AMD通往通用计算等先进应用领域打下了基础。
#p#
宿命,开普勒登场
Tahiti的革新可以说是2012年架构革新的一剂强心剂,它不仅让我们看到了希望,更对竞争对手NVIDIA的新架构充满了期待。与Tahiti的开放和释放信心不同,NVIDIA接替Fermi的开普勒架构一直做足了保密工作,直到发布的一瞬间才让整个世界为之一顿。

性能功耗比革新巨大的开普勒
开普勒图形构架拥有超过35亿的晶体管规模,核心面积294平方毫米。与上代的Fermi构架相比,其运算资源总量提升到了1536个ALU,Texture Filter Unit由Fermi的64个增加到了128个,构成后端的ROP则下降为32个。GTX680同样拥有全新设计的MC结构,4个64bit双通道显存控制器组合形成了全新的256bit显存控制单元,GTX680也因此采用了容量达2048MB的显存体系。
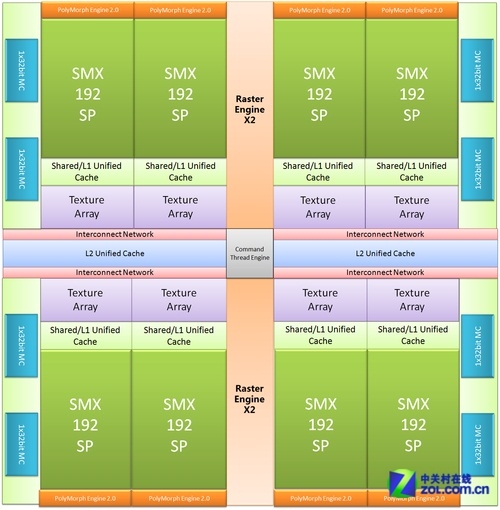
完整的GK104架构
GTX680的特色由六个主要的部分组成:
1、与Tahiti同样基于HKMG的TSMC全新28nm工艺。
2、与Fermi完全相同的4XGPC宏观并行设计。
3、8个包含了几何引擎、光栅化引擎以及线程仲裁管理机制的SMX单元。每个SMX单元包含一组改进型的负责出力几何任务需求的PolyMorph Engine,192个负责处理运算任务及Pixel Shader的ALU,16个负责处理材质以及特种运算任务如卷积、快速傅里叶变换等的Texture Array,二级线程管理机制以及与它们对应的shared+unified cache等缓冲体系。
4、负责完成fillrate过程以及输出最终画面的32个ROP单元阵列,以及对应L2 cache的4个64bit显存控制器MC(Memory Controller),负责视频回放及处理的PureVideo HD单元,以及全新的负责视频编码部分的NVENC。
5、根据功耗以及用户自定义负载需求实时调节GPU的GPU Boost功能,全新的TXAA以及抑制画面撕裂和顿挫的Adaptive VSync主动垂直同步技术。

开普勒架构GK104芯片核心照片
开普勒构架与Fermi构架在宏观层面上非常接近,其改进主要集中在微观结构层面,它使用了全新的SMX单元来替代传统ALU团簇结构,弃用了沿用数年的ALU分频机制,进一步改进了包括Cache/shared以及寄存器在内的缓冲体系,调整了线程仲裁机制并引入了全新的scheduling过程,为今后的架构发展做出了铺垫,引入了开创性的功耗性能管理机制,同时还强化了单卡多屏输出等功能性环节。
Tahiti与开普勒在宏观和微观结构对比中互有异同,Tahiti可以被看做是一个不同于AMD既往产品的,对称并行分布、core部分神似larrabee而uncore部分接近Fermi的全新结构,开普勒则可以被看做是一个4GPC并行,内部结构大幅调整优化的同时保留了之前产品优势的作品。Tahiti架构在维持吞吐的同时转向强调灵活性并进行了针对改进,而开普勒则在维持灵活性的前提下做出了平衡性能与功耗的努力。两者都在向着中线,也就是最佳的性能功耗比去靠拢。
#p#
AMD的致命伤——寄存器
开普勒与Tahiti都是双方积蓄许久之后爆发的革新之作,都应用了双方最全面的新技术和各项突破,其中Tahiti架构的革新不仅目的性更强烈而且也应该更加行之有效,但它们在旗舰级领域的对决结局却是出人意料的。尽管提前发布了73天,同时兼顾了大量革新且具有纠偏意义的理念和技术,但基于Tahiti的HD7900系列依旧在性能、功耗和成本等所有环节全部落败。大核心在功耗和成本层面输给小核心尚属正常,但在此基础上还在性能对决中输给小核心,这在GPU发展史上是非常罕见的——即便是功耗和成本令人诟病的GF100,起码也在性能和DirectX 11效率层面保住了面子。
是什么让Tahiti对各项先进技术的整合出现了状况并输掉了竞争呢?这个问题对我们来说既熟悉又陌生——让Tahiti陷入这样境地的根本,来自其架构内部的寄存器设计,而且早在一年半以前的GCN情报分析中,我们就已经对寄存器的隐患提出了预警。
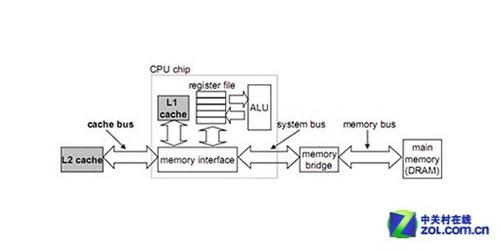
寄存器在处理器中的地位
作为最重要的缓冲单元,寄存器需要面对来自线程(Thread)和数据的缓冲需求。如果设计者缺乏寄存器的使用和管理经验,寄存器对于每个线程的复用率较低,或者说每个线程在特定时间片段内可以占用的寄存器数量不足,要满足大并行度Thread的性能需求就必须通过增大寄存器总量的手段来完成。在此基础上,双精度数据通常需要组合单精度寄存器来完成缓冲需求,因此双精度数据对寄存器的需求量要来的更大,如果此时寄存器复用状况不佳,要保证线程充分并行和DP运算的性能需求,唯一的做法就只有进一步加大寄存器总量一途而已了。
为方便理解,我们将寄存器数量折合成3项指标,分别是Reg per Thread(每线程寄存器数量),Reg per ALU(每ALU寄存器均摊数量)和DP Reg(双精度寄存器)。Reg per Thread越高,架构就能以越少的寄存器总量来满足尽可能多的线程并行处理需求,进而在等量寄存器的前提下腾出更多的空间给提升DP性能做准备。Reg per Thread越低,架构就需要以更多地寄存器总量来满足并行处理需求。寄存器的整体需求量可以被不严谨但简单的量化成Reg per ALU数值,一个架构的Reg per Thread越低,它实现更高线程并行度和DP性能所需要的Reg总量就越高,摊到每一个ALU身上的Reg per ALU数值也就越高。
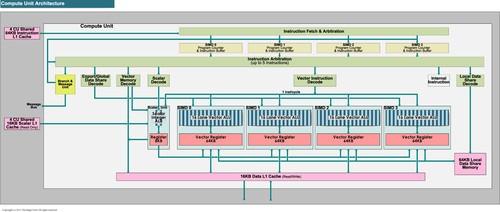
包含缓冲体系的CU单元内部结构
好了,现在我们来到了问题的关键环节。根据AMD和NVIDIA公布的数据,Tahiti架构拥有总计8192KB的32bit Vector Reg,在不考虑Scalar Reg等其他特殊需求寄存器的前提下,其Reg per ALU为4KB,它可以实现1/4速的DP性能。而开普勒架构的Reg per ALU数量则为1.33KB,NVIDIA可以以这一数值的实现1/3速的DP性能(GK110)。另外作为参考,Fermi的这一数值为4KB per ALU/半速DP。
4KB per ALU的Tahiti和1.33KB per ALU的开普勒,这样的数据意味着什么事呢?我们来算一笔通俗的帐——1个最基本的1bit sram单元需要6个晶体管来实现,更高的频率以及更低的延迟会让单元的晶体管数量进一步增加,我们并不清楚AMD和NVIDIA目前所处的频率水平需要多少晶体管来实现1bit的寄存器,但即便忽略一切其他相关单元,单纯考虑纯sram部分并用最保守的6晶体管方案来计算,4KB per ALU意味着Tahiti架构每个ALU均摊的寄存器晶体管数为786432个(6*32*1024*4),而NVIDIA每个ALU均摊的寄存器所占用的晶体管数则仅为261489个(6*32*1024*1.33)。
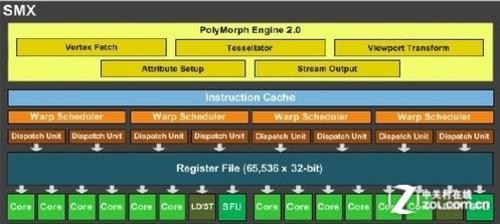
SMX单元中的寄存器数量
对于每一个ALU及其周边资源来说,Tahiti需要比开普勒多付出最少超过50万个晶体管的代价,而Tahiti架构总计拥有2048个Vector ALU,换句话说,就是即便以最保守的方式来计算,AMD在Tahiti架构中为寄存器所多付出的晶体管代价也在10亿以上。如果AMD进一步扩大Tahiti架构的Vector ALU规模,或者在寄存器单元中使用的是可以应对更高频率的7晶体管甚至8晶体管方案,这一数值还将继续扩大。
而Tahiti架构,一共只有4.3个“10亿晶体管”。

Intel 45nm工艺下的6T sram单元
并未超越对手的计算特征和效率、比竞争对手高的Reg per ALU还有更大的DP衰减幅度,这些现象都反映了AMD在寄存器使用策略和算法上的存在的差距,它表明AMD无法完全解决诸如Reg pool以及rename之类许多环节的问题,所以只能以极大的寄存器总量来同时满足Thread性能/DP性能的需求,而这种解决方案恰恰是最致命的。单纯增加规模不仅低效,而且增加出来的晶体管并不会直接产生任何Flops或者图形性能。想要提升DP性能和Thread性能,AMD必须在扩充运算单元规模的同时付出比对手更多的寄存器晶体管代价,而对寄存器的过量使用不仅造成了Tahiti架构更容易受到D线的压迫,让功耗控制变得更加困难,还引发了一系列多米诺骨牌效应并挫伤了其在图形领域的表现。
#p#
多米诺骨牌
整体而言,一颗芯片在特定工艺下的规模是存在上限的,制造者不可能无限制的放大芯片的规模。而上限的存在又意味着两个截然不同的结局,你可以用更小的规模换取更好的可制造性,或者在触及上限时面对晶体管使用方向的平衡问题。AMD面临的由寄存器导致的多米诺骨牌效应,就是后者作用的结果。
其实这说起来很简单——Tahiti为寄存器付出了10亿甚至更多的晶体管代价,这些晶体管让它更快的达到了芯片规模的上限。如果没有这层负担,Tahiti本来可以获得更小的芯片面积以及更好的功耗表现,或者用这些晶体管来制造更多“针对图形”的单元来获得更好的图形性能。它可以被塑造成一个与开普勒架构的GK104规模相当,功耗表现比现在更加优秀的产品,或者可以用这10亿晶体管来强化并行度设计,也继续补足曲面细分性能,还能增加ALU、Tex或者MC/ROP的规模等等,对于10亿个晶体管来说,有太多美好的可能可供Tahiti去选择了。
Tahiti构架CU结构细节
但是现在,由于寄存器使用策略和算法的问题,AMD不得不背负这10亿晶体管的负担。少了这10亿晶体管,以上那些美好的可能全都无法实现,Tahiti架构不得不止步于当前的规模,各项针对过去积累架构错误的先进技术改进都没有进行彻底,传统图形领域相对强势的后端优势得不到发挥,而且还要因此而承受规模释放困难,功耗难以控制等各种各样的问题。无论技术改进和愿景多美好,没有晶体管可用,一切都是空谈。所以由寄存器引发的一个又一个不利的因素像多米诺骨牌那样倒下,最终造就了Tahiti“什么改进和技术革新都好就是效果不好”的结局。
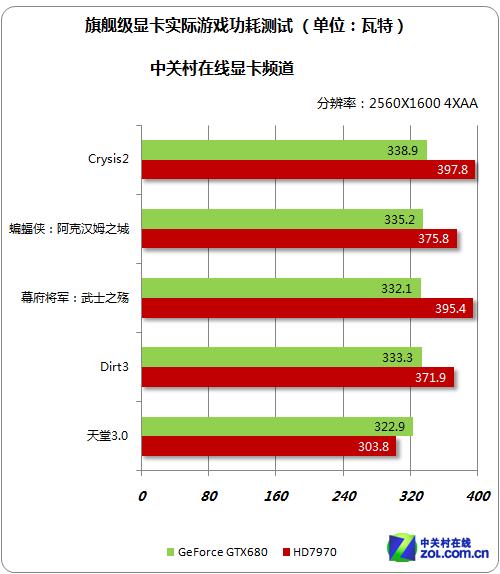
Tahiti架构与开普勒架构在实际游戏测试中的功耗对比
而没有这层负担的开普勒,则利用这份优势强化了并行化结构、曲面细分以及各种各样的图形相关部分,并在突出图形性能和运算性能平衡的同时依旧维持了比Tahiti少8亿的晶体管规模。其所要经历的事情也就非常简单直接了——性能和效率高于Tahiti,芯片面积小于Tahiti,功耗低于Tahiti……
不光开普勒,即便是在GCN阵营内部,同样也存在着Tahiti的对立面,那就是面向甜品级的Pitcairn架构。
#p#
甜品级首发,Pitcairn
Pitcairn构架与Tahiti以及Cape Verde同属GCN体系,它拥有212平方毫米的尺寸和28亿晶体管的总规模。定位于旗舰及中端之间的Pitcairn拥有更加合适的规模及芯片面积,同时具备了Tahiti架构的绝大多数技术革新。

基于Pitcairn架构的HD7870规格
Pitcairn拥有20组结构上同Tahiti相同的CU单元,每组CU单元拥有4个SIMD Core,每组SIMD Core包含16个Vector ALU,因此其运算资源总规模为1280个Vector ALU。除了Vector ALU之外,每组CU单元还包含4个Texture Filter Unit和16个Texture Fetch Load/Store Unit,因此Pitcairn拥有80组Texture Arroy。后端方面,Pitcairn的ROP阵列规模与Tahiti相同,均为32个,而显存部分则由4个64bit MC进行管理,构成256bit的显存位宽。不难看出,HD7870的规格是旗舰级的HD7970的62.5%,同时刚好是Cape Verde的整整一倍。

游戏玩家是HD7800的目标用户
由于同属GCN体系,Pitcairn的宏观结构同Tahiti保持了一致,但由于双ACE的宏观对称格局下辖了比Tahiti更少的运算资源,后端的比例也因此而灯下的获得了放大,这些要素配合高频让Pitcairn获得了相当不错的架构效率和性能。在此基础上,Pitcairn的成本控制和功耗表现较之Tahiti也有了更大的提升,无论板卡物料成本还是芯片良率,Pitcairn都具备成为AMD盈利重点的资质。以甜品级架构而言,Pitcairn的结构和性能/功能表现全面完善,是一款相当合格的架构。
削减后的开普勒,GK106
由于NVIDIA在2012年中将产品线的常规架构总量从4个变更到了3个,对抗Pitcairn也就变成了GK104和GK106共同完成的任务。基于开普勒图形构架的GK106核心拥有221平方毫米的芯片面积。与完整规格的GK104相比,GK106运算资源总量从1536个ALU下降到了960个,Texture Filter Unit由128个减少到了80个,构成后端的ROP为原生24个。与ROP相对应的,GK106的MC结构也变成了3个64bit双通道显存控制器,显存位宽192bit。GK106拥有2048/3096MB两种显存容量搭配方案,其中2048MB采用了非对称显存布局体系。
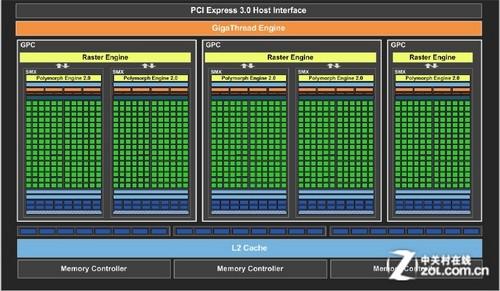
NVIDIA公布的GK106架构
GK106架构具备5组SMX单元,分别居于3个GPC中来组成并行结构。3 GPC的传统结构让它具备了3套前端以及光栅化处理部分,其单周期的几何输出以及光栅化能力为同频旗舰级架构的75%。更好的几何性能、更低的时间成本以及研发成本是它的优势。GK106架构让NVIDIA在下位甜品级以及上位中端产品区间里拥有了更好的产品可操作性,同时在面积和成本空间层面获得了较好的平衡。
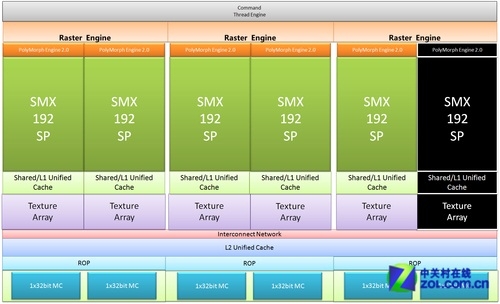
我们预期中的完整GK106架构
GK106可以被看做是削减一组GPC之后“再砍一刀”的开普勒。除了规模之外,它的各种结构细部特征均与开普勒架构保持一致。与微观结构进行了一定调整的GCN系列架构不同,开普勒系列架构保持了高度的一致性,它们之间仅有的规模差异表现出了高度的模块化特征,我们甚至可以从一款架构的表现以及特定的规模限定规则来推定出其他所有开普勒架构产品的大致性能。只要规则合理,开普勒系列架构的性能控制会更加容易且具有规律性。
与之相对应的,GCN架构内部的表现就要相对差一些,Pitcairn在宏观结构上虽然保持了与Tahiti的一致,但它的微观结构却存在着与Tahiti架构的不同,而Pitcairn较之Tahiti更加优秀的综合表现,正是这一不同所导致的。
#p#
为什么甜品架构更“健康”?
相对于Tahiti高达43亿晶体管的规模以及365平方毫米的核心面积,仅有28亿晶体管规模和212平方毫米的Pitcairn要小上很多。但Pitcairn顶级产品HD7870的绝对性能,却并未因此而落后Tahiti的次级旗舰产品HD7950很多,它与GK104/GK106架构的NVIDIA甜品级产品在性能层面上的竞争也并未落得下风,我们完全可以讲Pitcairn看做是与GK106乃至整个开普勒架构表现相当的架构,其性能功耗比更是超越了整个Tahiti架构。无论从何种角度来讲,Pitcairn都要比Tahiti“健康”很多。是什么让同属GCN架构,采用几乎完全相同技术的两款架构表现出了迥异的结果呢?
答案还是万恶的源头——寄存器。

HD7870满载功耗相当“正常”
Pitcairn的定位在游戏级的甜品市场,它不需要承担旗舰级架构探索和收集经验的负担,只需要利用现有技术更加合理的打造产品即可。所以Pitcairn的双精度浮点运算能力仅有单精度浮点运算能力的1/16,更低的DP性能目标让它卸下了沉重的寄存器负担,进而也就避免了每个ALU多50万晶体管的窘境。
利用这部分晶体管所换来的空间,Pitcairn维持了与Tahiti接近的后端规模,这种等效放大后端/ALU比例的做法强化了Pitcairn在“纯图形”层面的表现,而更少的晶体管总量又让Pitcairn更加远离D线,这使它获得了更好控制的功耗以及挑战更高频率的机会,规模和高频率的交替作用进一步增加了Pitcairn的图形以及综合表现的得分。我们完全可以把Pitcairn看作是AMD版本的开普勒,它不仅在甜品级架构之战中为AMD守住了阵地,更为我们展现了如果Tahiti没有遇到问题时所可能的表现。

Pitcairn特性一览
以GPU这种简单单元大规模并行的逻辑结构而言,决定性能的根本要素其实就是并行度和缓冲机制。大家的ALU结构,尤其是进入到Tahiti/开普勒时代之后的ALU结构和能力基本上都是相当的,谁能为ALU提供更好的缓冲并让其获得更高的复用率,谁就能获得更好的效率。Tahiti和Pitcairn同属GCN,在结构和技术应用上基本相当,唯一造成两者不同命运的重要诱因就是寄存器层面的差异。另外,历史上并不是没有出现过因为寄存器导致的悲剧,名留GPU展史册的NV3X就结结实实的栽在了寄存器使用经验不足上。命运在10年后的今天只是改改演员和台词,就把一幕内容相同的悲喜剧本拿来再一次的重演,这不能不让我们唏嘘。
#p#
最小GCN——Cape Verde
Cape Verde构架是整个GCN体系中最小的成员,它的使用了GCN架构的几乎全部成熟技术,同时对这些技术进行了更加有效和合理的组合。它拥有123平方毫米的芯片面积,晶体管数为15亿,这一规模仅为Pitcairn的一半和Tahiti的三分之一。

Cape Verde构架定位
Cape Verde拥有8~10组CU单元,合计512~640个向量ALU。由于与CU单元绑定这一特性,Cape Verde拥有了32~40个TA/TMU单元。作为一款中端显卡,其后端由4组ROP单元组成,每组拥有4个ROP单元,合计可以在一个周期内完成16个光栅化操作。显存控制器方面则由2个64bit MC构成128bit显存总线,每个MC对应256K的L2 Cache,这个数值是旗舰级的HD7900系列的2倍。
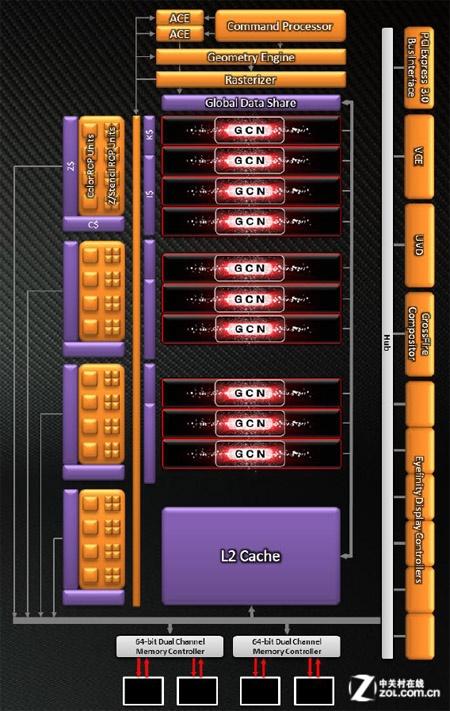
Cape Verde构架
上述这些特性,让Cape Verde拥有了Tahiti这一AMD当前旗舰级构架31%的ALU规模,50%的ROP规模,66%的L2 cache规模以及27%的显存带宽资源。按照AMD的说法,在1920X1080分辨率下Cape Verde的性能是优秀的,更高的分辨率和更大的AA设置会导致更多地性能下降,但作为一款中档显卡来说,这种下降是可以接受的。
Cape Verde的微观结构较之Pitcairn和Tahiti有了进一步的调整,它的宏观并行度异于其他GCN体系的架构。与Pitcairn一样,Cape Verde同样没有Tahiti的寄存器晶体管压力,所以可以有更宽裕的空间来强化其他部件,因此我们在Cape Verde上看到了更大的cache体系,这种调整为它带来了好于Pitcairn的效率表现,并最终让其成了性能功耗比表现最好的GCN体系架构成员。
市场化运作的GK107
相较于GK106,GK107要来得更加“单纯”一些。这款118平方毫米的芯片同GK106一样维持了开普勒高度的统一性,甚至其细分出来的GeForce GTX 650和GeForce GT 640两款产品的核心结构都是一致的,惟一的区别仅在于使用的显存颗粒的速度不同。
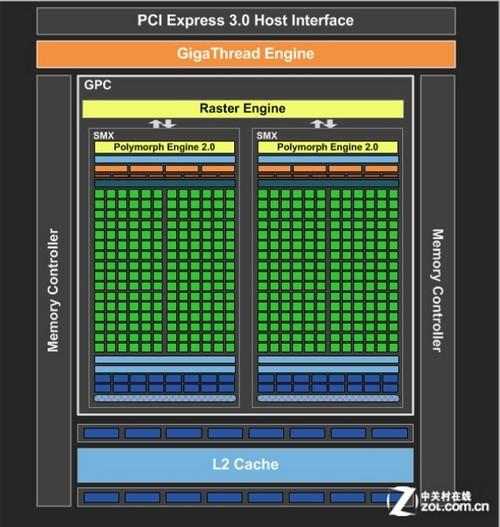
GK107架构
GK107拥有一组完整的GPC结构,内含2个SMX单元。它的实际规模是旗舰级的GK104的1/4,这种标本型的特征让GK107有了很高的参考价值,我们可以将GK107芯片的逻辑运算部分直接看做是GK100时代开普勒架构最基本的组成部分。

GeForce GTX 650规格一览
由于这种特性,GK107架构拥有了一套完整的前端以及光栅化处理部分,其单周期的几何输出以及光栅化能力为同频GK104架构的25%,或者同频GK106架构的三分之一。同时,与之搭配的显存控制器阵列扩展到了2个,GK107由此具备了128bit的显存位宽。除此之外,GK107的其他特性均可以和GK106一样参考整个开普勒家族的传统。
#p#
中低端的非技术战争
如果说旗舰级架构是技术之战,甜品级架构是技术之战面向市场方向的延续,那么中端和中低端架构的竞争更多地就是市场层面的战争了。无论GK107还是Cape Verde,它们都是市场化味道浓郁的架构。

强调特性而非绝对性能是Cape Verde的特征
中端及中低端市场并不是游戏发烧友集中的领域,这一领域的市场需求会更多地考虑性能功耗比和应用的多样化。谁能以更低的功耗和售价来提供更丰富全面的特性,让解决方案变得性价比十足,谁就能够取得这一领域的胜利。至于性能,虽然同样是不能缺少的要素,但相对于性价比和全面表现而言,它只能算是锦上添花而不是雪中送炭的存在。这些要素,都在GK107和Cape Verde身上获得了体现。

GeForce GT640图形核心

GeForce GTX650图形核心
相比于GK104和Tahiti,GK107以及Cape Verde都是经过深度的规模限制。它们保留了30%左右的旗舰级架构规模,并按照各自对市场的理解进行了进一步的特性和性能控制。Cape Verde的方式是架构内部继续限制规模并降低频率,而GK107则使用了GDDR5和SDDR3的带宽差异。性能并不是它们的主要追求,如何限制性能并细分市场才是它们的目标。这两款架构的实际表现,更多地是在考验AMD和NVIDIA对市场需求的理解、把握以及操作等运作实力,是“软实力”的体现。
架构的对错究竟是谁的对错?
好的技术并没有带来一起向好的产品表现,这促使我们开始探寻更深层次的架构影响并寻找答案。在回顾了2012年全年的图形架构之后,我们找到了影响Tahiti以及整个AMD架构线表现的问题所在,同时也产生了更多问题和思考——架构左右了技术的命运,那又是什么左右了架构甚至是整个业界的命运呢?
Tahiti背负了寄存器的负担,这负担甚至掩盖了其诸多精彩的革新和种种努力,那是谁给了Tahiti寄存器的负担?为什么Tahiti要去背负这样的负担?为什么是现在?我们为什么称其为“AMD的致命伤”而不是“Tahiti的致命伤”?这负担对今后的AMD图形架构发展有什么影响?解药又在哪里?为什么开普勒不用面对同样的问题?

谁阻止了承诺向现实的转变?
Pitcairn和Cape Verde比Tahiti表现的都要健康许多,在与同级别开普勒的竞争中也未表现出劣势,但为什么Pitcairn和Cape Verde并没有因此而热卖,并未AMD带来更好的市占率表现以及盈利状况?我们提到的非技术战争的战场上究竟发生了些什么呢?
开普勒架构的表现在本轮架构竞争中可以被判定为优秀,但截至到目前为止,开普勒架构产品的市场表现却更多的集中在了旗舰和上位甜品级。中端及以下的GK106+GK107并没有在第一时间表现出应有的爆发态势,是什么妨碍了它们甚至整个中端及以下市场的需求?
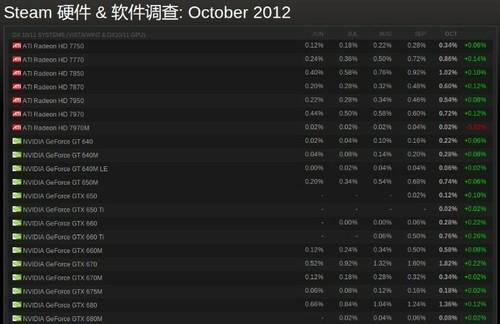
开普勒的旗舰级产品市场反响更强烈
整个2012年的GPU架构演进虽然精彩,其中不乏各种先进技术以及性能的明显提升,但整个图形业界似乎并没有受到对等的刺激并泛出波澜。我们没有看到更好的或者令我们眼前一亮的游戏和应用,没有看到图形以及DIY业界复苏的迹象,甚至看不到平板及智能手机以外的东西,这又是为什么呢?
其实,这些问题的答案就在AMD/NVIDIA两间公司的特征以及我们自身。这一年图形世界中发生的一切都不是孤立存在的事件,它们是一系列绵延数年,包含了技术、理念、选择、运作以及执行能力等等要素的,甚至是影响了整个业界前进脚步的漫长过程的结局。我们将会在下周为您带来《显示世界的2012终篇》,上面这些问题的答案,图形界乃至DIY界过往的各种精彩以及未来的命运,还有我们使用两周时间进行漫长技术和架构介绍准备的目的,都将在下周揭晓。敬请期待吧。