正在纽约进行的大数据技术会议Strata Conference + Hadoop World传来消息,Cloudera发布了实时查询开源项目Impala 1.0 beta版,称比原来基于MapReduce的Hive SQL查询速度提升3~90倍,而且更加灵活易用。Impala是高角羚的意思,这种羚羊主要分布在东非。
同时,这个项目也将以Cloudera Enterprise RTQ(Real-Time Query)为名进入CDH发行版。可以部署到生产环境的版本将到2013年一季度就绪。不过,据ComputerWorld和MarketWatch的报道,Capgemini金融服务、Karmasphere、MicroStrategy、Pentaho、Qlikview和Tableau等已经在Impala上做了几个月的实际产品测试。
众所周知,Hadoop及HBase、HDFS其实是在Google的MapReduce、BigTable和GFS三篇论文的启发下开发出来的。而近年来Google的基础架构又有了一波新的革新,有媒体称之为后Hadoop时代的三驾马车Caffeine、Pregel和Dremel。当然,这种说法有混淆了辈份之嫌,而且并不十分科学。Pregel是图数据库,据说在MapReduce之外担负了另外20%的数据处理任务,与三大论文之间没有承继关系。项目的创始人之一Grzegorz Malewicz去年来过北京,是Hadoop in China大会的主题演讲嘉宾。今年加盟了Facebook。前几天我在GTalk里询问他的近况,他说正在开发Pregel的开源版本。其实某种程度上,Caffeine是MapReduce的演进,在今年OSDI上大火的Spanner可以视为BigTable的演进,而Dremel则是新出的。
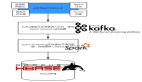
无论如何,有了好东西,开源社区当然会很快跟进,仿照Dremel的Apache Drill项目已经进行一段时间了。而Cloudera在官方博客中也明确承认,“对每个Hadoop用户都具有革命性的技术”Impala是在Dremel的启发下开发的。也就是说,Impala不再使用缓慢的Hive+MapReduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或者HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如下图所示。

Impala的架构
Impala采用与Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),这样在使用CDH产品时,批处理和实时查询的平台是统一的。目前支持的文件格式是文本文件和SequenceFiles(可以压缩为Snappy、GZIP和BZIP,前者性能最好)。其他格式如Avro, RCFile, LZO文本和Doug Cutting的Trevni将在正式版中支持。
博客同时还比较了Impala与Dremel。文中说:
Dremel之所以能在大数据上实现交互性的响应速度,是因为使用了两方面的技术:一是对有嵌套结构的嵌套关系型数据采用了全新的列式存储格式,一是分布式可扩展统计算法,能够在几千台机器上并行计算查询结果。
而后一技术是从并行关系型数据库那里借鉴而来的。与2010年Dremel论文只能处理单表查询相比,Impala已经能够支持完整的JOIN操作。此外,除了Trevni列式存储格式之外,Impala还支持广泛的其他格式。也就是说:
Impala+Trevni已经完全实现了Dremel论文中的查询性能,而且在SQL功能上还超过了它。
文章也强调Impala并不会取代传统的数据仓库和MapReduce+Hive。数据仓库在对数量有限的结构化数据集做复杂的分析处理时仍然更加适用,而长期运行的数据转换负载还是MapReduce的用武之地。
有意思的是,这篇官方博文的作者之一是Impala的架构师Marcel Kornacker,在加盟Cloudera之前,是Google F1项目查询引擎的主开发人员,F1项目的任务,正是将AdWords的存储从MySQL转到Spanner。