七、骚年,这就是你的***速度了吗?
在介绍了前面的几个排序算法之后,这一次我准备写写快速排序,快速排序之所以叫快速排序是因为它很快,它是已知实践中最快的排序算法(不过曾经我看过一个叫google的位图排序算法,传说能更快,但从那以后我再也没有找到过相关的资料了,所以说江湖小报上的消息还是不要信的比较好),它的平均运行时间能达到O(NLOGN),而且在绝大部分情况下很容易达到这个时间界。
快速排序算法过程分为如下几步:
1.如果数列中的元素只有0个或者1个,那么算法结束,
2.在待排序数列中任意选取一个数,记为p好了,
3.将剩下的元素划分成两个子序列,一个子序列里面的数全部比p小,另一个全部比p大,
4.分别对两个子序列进行上述过程的排序。
看完这四步,我相信很多人又要开始退缩了,这里面又有递归,其实不用怕,仔细分析一下先,快速排序和归并排序挺像的,可以看出来这是一个思想的延伸,不同的是归并排序在递归(排序)之前并不对数列进行任何处理,而快速排序是要进行一些排序的预处理,得到两个子序列,然后再将这两个子序列进行排序。在这里面要特别提到的一个就是如何选取p值对于这个算法的效率是有影响的,这也是快速排序很微妙的一个事情,基本思想说完了,惯例是贴个代码了。
- void quickSort(int numbers[], int array_size)
- {
- q_sort(numbers, 0, array_size - 1);
- }
- void q_sort(int numbers[], int left, int right)
- {
- int pivot, l_hold, r_hold;
- l_hold = left;
- r_hold = right;
- pivot = numbers[left];
- while (left < right)
- {
- while ((numbers[right] >= pivot) && (left < right))
- right--;
- if (left != right)
- {
- numbers[left] = numbers[right];
- left++;
- }
- while ((numbers[left] <= pivot) && (left < right))
- left++;
- if (left != right)
- {
- numbers[right] = numbers[left];
- right--;
- }
- }
- numbers[left] = pivot;
- pivot = left;
- left = l_hold;
- right = r_hold;
- if (left < pivot)
- q_sort(numbers, left, pivot-1);
- if (right > pivot)
- q_sort(numbers, pivot+1, right);
- }
***个函数你可以理解为一个驱动程序,为的是隐藏一些实现细节,让调用者调用时传递更少的参数,减小出错的可能性,这也是一种有技巧的设计方法。第二个函数是真正的快速排序函数,从代码上看,这里选取每个序列的***个点作为p点,然后分别从两端开始和这个p点进行比较,先从右端一直找到***个小于p点的值,然后停住,交换左端左边现在扫描到的值(也就是p点的值),两个值,然后换从左边开始扫描,找到目前比p点大值,交换,如此继续,***当从左端扫描的坐标和右端扫描的坐标相遇时,记下这个点,将p点和这个点的值交换,这样就可以保证p点左边的值都是比p点的值小(但是不一定是有序的),右边的值都比p点的值要大,如此循环,然后依次对两个子序列进行一样的排序过程,因为在上一篇里我已经详细的分析了递归的调用过程,所以在这里我就不再分析了,唉,人还是懒的。
先看下效果好了。
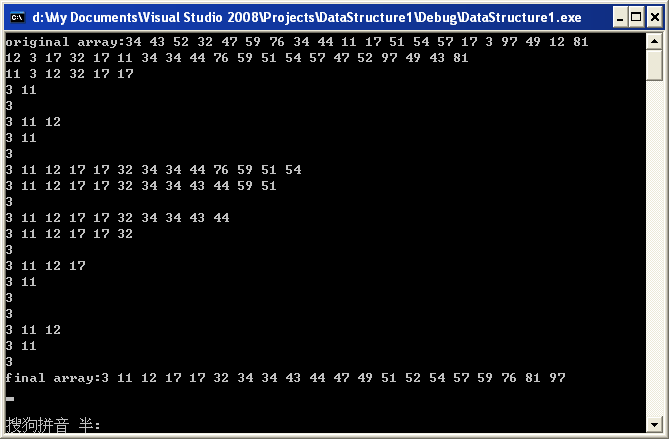
分析下结果好了,就看***行,***行里面我们选取的p是34,那么从右端开始,81大于34,不用交换,继续扫描,12小于34,交换两个值,12交换到***位,34交换到倒数第二位,现在换从左边扫描,43大于34,又开始交换,43变到倒数第二位,34交换到第二位,如此往复,得到以34为分界点的,左边的序列的元素全部比34小,右边的元素全部比34大。
下面来简单说明一下为什么p点的选取对于快速排序的效率有一定的影响,因为看到第三步,是要将序列划分成为两个序列然后进行递归,试想如果一个逆序的数列,也就是54321这种,如果按照我们上述的方法选取p点,会出现的问题就是划分成了的两个子序列,一个子序列里面是原数列的所有数,一个子序列里面没有数,这样会导致效率的大大降低。那么如果是随机选取p点呢?这样会减少我上面说的这个问题,但是会带来的负面效应就是随机数的生成也是要耗费大量时间的,所以说这也是一种得不偿失的方法。那么有没有好一点的方法呢?有一种通用的方法叫做三中值分割法,如果让快速排序效率尽量高,那么我们的选取的p值尽量是中值,这样的话分成的两个序列比较平均,其实就是对于一个带排列的数列,选取其中间位置上的那个元素,在实践中,因为大部分应用背景的关系,所以这样的方法往往能神奇的提高效率。
原文链接:http://www.cnblogs.com/ZXYloveFR/archive/2012/09/27/2705463.html
【编辑推荐】