在大数据领域存在诸多挑战,比如成本和技术,另外服务模式也为企业应用大数据造成了很大的挑战。企业内部数据集中以后,如何向用户、企业的前端和后端提供服务呢?日前中国通信学会大数据专家委员会在京成立,该组织是由中国通信学会牵头组建,我国首个专门研究大数据应用和发展的学术咨询组织。此次会议上,TechTarget中国有幸听到中国科学院计算技术研究所何清研究员、博士生导师的演讲。何清表示大数据为企业带来了创新机会,也带来了挑战,而关于数据挖掘云服务更是并不简单。
大数据演化
根据Cisco的预测,2013年互联网的数据就要达到667EB,而在2015年,在智利的巡天望远镜那里也会产品类似的数据,到2013年我们生成1.8ZB这样规模的数据只需要10分钟。何清表示:“大数据规模的增长实际上给我们的技术创新,给我们的市场竞争以及生产活动实际上带来了一个全新的前沿的领域。现在经济活动的增长根本就离不开数据,我们的创新活动,我们的经济活动,一刻也离不开数据,离开了数据不可能产生创新。大数据是一个技术问题,但是实际上带来了更多的商业机会。”
大数据规模从定义来看是一个不断演化的指标,现在指单一数据集从数10TB到10几个PB的数据规模。大数据有什么样的特征呢?何清解释道,现在有三维表述、四维表述,甚至有五维的表述,对于数据挖掘来说,实际上我们所关注的是大数据里面的这种特征,稠密与稀疏是共存的。表现在数据在局部可能分布极其稠密,但全局来看,我们所收集来的数据又是极其稀疏的。冗余和缺失是并存的,数据是存在大量的冗余的,但是局部的数据又是缺失的。再有一个特征就是静态和动态互现,就是多元数据的事态持续动态演进。
在大数据上最重要的技术问题是如何理解这么多的数据?如何理解这些大数据?大数据所带来的技术上的挑战包括描述与存储的挑战,另外一个挑战就是面临着挖掘与预测的挑战。大数据挖掘增加样本十分容易。但是,数据挖掘算法要降低复杂度非常难。#p#
数据挖掘发展历程
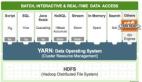
何清认为数据挖掘的发展是以数据存储和管理技术的发展为基础的,每当数据存储与管理技术向前发展一步,相应的数据挖掘技术、系统和平台也就会得到相应的升级。最初的传统式、卡片式的数据存储是不可能实现大数据挖掘的,也不可能用于大数据存储。现在,HBASE和HDFS这两种方式为大数据的存储提供了基础。在这个基础上,为大数据的挖掘奠定了基础。关于大数据管理方面有很多具体的要求,最主要的是大数据的容量问题、数据存储与管理。大数据管理格式多样,速度规模复杂性超出传统的数据管理技术的要求。这时候,甚至也需要内存的数据管理。
在大数据管理基础上进行数据挖掘,需要使用MapReduce技术。何清表示:“未来我们的数据挖掘不可能在单一的数据仓库上来做,可能要按需整合多个原信息的逻辑数据仓库,代替单一数据仓库的模式。数据挖掘技术的发展从第一代的独立算法,独立的系统单个机器向量数据,现在实际上已经发展成了基于云计算的并行数据挖掘与服务。在这个时候,同一个算法分布在多个节点上并行运行,多个算法之间也可以并行来执行。计算资源按照虚拟化技术是按需分配的,其数据管理已经是NoSQL的这些方式,HDFS、HBASE等等。”
大数据挖掘算法需要什么样的算法呢?根据何清所述,包含了传统的关联分析、矩阵分析、异常分析、演变分析等等。大数据管理主要取决于数据的容量,但是大数据挖掘受到算法的复杂度、并行度以及数据存储速度的制约。大数据挖掘我们要求能够处理高维、多模态、多类的大数据。
大数据挖掘云服务
目前大数据挖掘面临诸多方面的挑战。在算法上要结合不同的分布式计算环境;系统性能方面要考虑减少同步与分布的开销;而从实现方式来看,并行数据挖掘各节点间是采用高速网络来连接的,而分布式一般是广域网。何清解释道,大数据挖掘要寻求的是具有分布式和并行两种特征兼具的计算环境,而云计算就提供了这种方式。云计算模式提供的首先是存储,比如说以Hadoop为例,它实际上是在大型集群上,能够可靠的存储大数据的数亿级的文件系统,容错性比较好。由于采用了虚拟化技术,因此简化了要把计算资源的分配交给编程者的方法
数据挖掘云服务也存在诸多要求。服务要保证可用性、可靠性还有高性能。在这是隐私是安全的,不允许未授权的访问,也不允许其他人能够对他所挖掘的数据能够理解。“除了挖掘者本人以外,或者是本公司以外,其他的即使看到数据,也对他的数据不可理解,要做到这样。我们实现的途径按行业来做这个数据挖掘,云服务的平台。专业的数据挖掘人士就是提供数据挖掘算法服务,大众和各种组织就成为服务的受益方。我们在这个实现过程当中,肯定离不开虚拟化的技术,我们要做到可信和安全,”何清如是说道。
何清为我们介绍了PDMiner体系结构,这是一个集成各种并行算法的数据挖掘工具平台,其中的并行计算模式不仅包括算法之间的并行,而且包括算法内部的并行、接口系统和工作流子系统。这个系统做到了并行,而且提供了一系列灵活的算法组件。相对来说,它的容错性、开放性、可控、可移动都是很好的。在这个基础之上开发了COMS,实际上是数据挖掘后台,开发出前台的云服务界面。用户通过互联网就可以去定制数据挖掘任务,可以上载和加密数据,来做到数据挖掘。
最后,何清说道:“我们大数据挖掘要注意两点,首先是要选择复杂度低的算法,就是说N方的是很难想像的处理大数据的。我们尽量要把全局最优的问题转化为局部最优的问题,尽量的使用低阶的多项式复杂度算法。我们要使用高效并行的策略,尽量避免使用全局信息。”
专家简介:何清,中国科学院计算技术研究所研究员,博士生导师,2008年底开发完成了我国最早的基于云计算的并行数据挖掘平台,用于TB级实际数据的挖掘,实现了高性能、低成本的数据挖掘,先后主持完成多个有关数据挖掘的国家自然科学基金项目和863项目,提出了一系列有效的数据挖掘算法,组织开发的多个数据挖掘软件获得了软件著作权,并实际应用到电信、国家电网、信息安全、环保等多个行业,为企业带来了可观的经济效益和社会效益。