













非功能性要求
废话不说,这里先脱离系统的整体架构,后续在不断完善整体架构,这里首先讨论的是数据库层面的设计,因为对于整个架构系统来说,数据库的设计是最为关键重要的,数据库的设计好与坏,决定了整个系统的性能,可用性,扩展性。在考虑数据库的设计之前,我们可以先抛开非业务功能的需求,先看看非功能性需求,主要包括
1 数据库的类型选择
目前市场上数据库主要有:关系型数据库(Oracle,DB2,Mysql),NOSQL类型数据库(MogonDB),对象数据库(不是很了解),面向文档的数据库(apache couchBD),面向统计的数据库(HBASE)
根据客票系统的类型,应该是属于OLTP类型的系统,但是考虑到商业上分析需求,也属于OLAP型系统,由于本次讨论OLTP系统的设计,优先选择Oracle。为啥,用的公司多,市场上相关的技术工程师多,DBA管理员多,安全性和性能都不错。就是有点贵,不过考虑到是铁道部,完全忽略。对于部分客票系统非关键性业务也不重要的,这一部分数据可以考虑使用Mysql。至于NOSQL,没有用过,这个主要是面向web2.0的,对于事务要求高的系统,不太适合。
2 多数据中心
在金融行业,都必须部署多个数据中心,避免在一个数据库机房故障之后,全部数据都不可用。比如假如某地地震,数据库所在机房宕机了,如果这个时候检票或者买票,就sb了,所以需要尽快恢复。这样必须马上启动另外一个数据库机房配置。
除去灾备情况,考虑到铁路售票系统数据库的巨大访问量,2011年的铁道部的旅客发送量---2011年全国铁路运输目标:旅客发送量19亿人次,根据这个,初略估计一下一年估计要20亿张票,这个只是2011年的量,按照未来的几年的增长,按照目标值100亿人次估计,相当于一天有2700W独立UV,1亿PV。考虑到春节这个变态的高峰期,瞬间的并发量比平时会高上千倍。如果只在一个数据库只有一台,数据库就会存在单点,一旦数据库挂掉了,需要尽快的恢复。这个时候不太可能启用灾备数据库,因为灾备是异地备份,备份数据库同步数据比较慢(网络延迟),所以必须必须在同一个城市在部署一套数据库。这样在单点数据库故障的时候,可以马上切到备份数据库。
下面两幅图主要介绍异地灾备以及同城异机房备份的实现原理。
同城备份
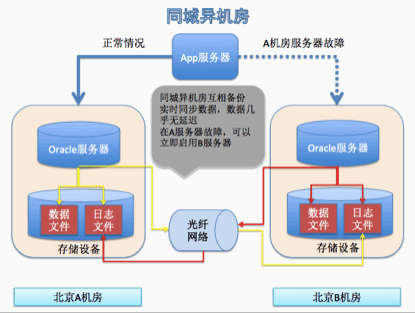
数据一次写一份,日志写两份。由于日志文件实时同步,A服务器写完B服务器的日志文件,B服务器马上就写自己的数据文件。这样不会丢失数据。当A服务器故障,应用马上就可以切换到B服务器。不会存在单点故障。但是考虑特殊情况,北京地震,A,B机房同时故障,整个数据都丢失了。所以必须由异地灾备的数据中心。不过还有其他的方式,这里就不做叙述了。总之是要做好去除单点。
异地备份
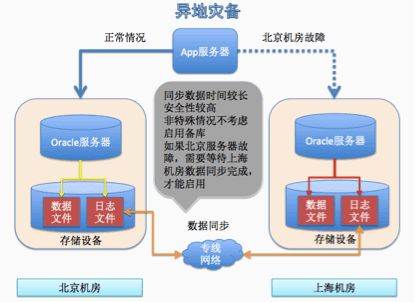
这个架构和同城备份有一点区别,就是A服务器只会写A机房的日志文件,然后A异步同步日志到B机房的日志文件。这里面会有几分钟的网络延迟。这里不实时写B机房的日志文件,主要是性能。如果实时写B机房的数据,一次更新操作,就会至少有一次网络延迟(上海到北京的网络传输时间)。会影响数据库的性能。而同城市通过光纤连接,传输速率快,可以忽略网络延迟。如果A机房故障(灾难性的故障,比如地震,机房被恐怖分子袭击),就会丢失一部分数据,丢失的数据就是网络延迟同步的数据。对于购票业务来说,数据丢失几分钟的,是可以接受的,大不了我铁道部亏一点,这几分钟丢失的数据我全部免票。也可以做一次好的营销。但是对于金融行业来说,数据是不能丢失的,这里的异地备份就不符合金融业的要求。用性能换取可用性。就像atm取钱一样,一次交易涉及几分钟。你的交易数据银行至少会备份2份,一份同城的,一份异地的。
3 硬件配置
这一块不是很熟悉,交给dba专业的人去做吧。小机 + 存储(SAS)。不过对于铁道部有钱,上大机即可。不过我们还是按照互联网方式去分析设计系统,使用普通的存储以及服务器。
功能性分析
1 业务流程分析
先简单的了解一下购票系统的业务流程:旅客到互联网(也可能是其他渠道)登录,根据出发日期,起始站,终点站查询车票,确定车次和座位,预定车票,然后进行支付,支付成功之后,发短信,之后客户到线下去取票。一个简单的流程就结束了。
从上面的流程可以看出,整个业务流程中有几个以下几个实体以及实体的重要属性信息
1 旅客信息:假设都是实名的,至少有三个重要信息 姓名,身份证,手机号
2 车次信息:车次,起始站,终点站,类型,发车时间,到达时间
3 车次停靠信息:车次,停靠站,达到时间,停靠时间
4 余票信息:车次,起始站,终点站,发车日期,剩余座票,剩余卧铺。。。
5 车票信息:车次,起始站,终点站,发车日期,购票日期,旅客姓名,身份证,手机号,状态,购票渠道,支付日期
6 支付信息:金额,支付日期,支付银行,支付金额,支付方式
7 短信信息:车票信息,验证码,短信内容
整个购票过程包括以上几个重要的实体,其他的几个字段可以先不管。我们可以假设一下每一个实体的数据规模
| 实体 | 数据量 | 日增量 |
| 旅客信息 | 上限-中国人口数 16亿 | 这个真不好估计 |
| 车次信息 | 比较少,假设10万 | 日增应该也不会超过10 |
| 车次停靠信息 | 车次信息 ×200 == 200W | 日增应该也不会超过100 |
| 车票信息 | 巨大,目前年增20亿,未来年曾100亿 | 自己换算一下,不过不会很平均,春节几天会暴增 |
| 支付信息 | 和车票信息同数量级 | 和车票信息一样 |
| 短信信息 | 少于车票信息,毕竟只有网络订票才会有短信,线下购票不会有 | 未知,假设100W |
| 余票信息 | 一年交易量 365×车次信息 == 5000W | 日增数据量 和 车次信息数量一致 假设10W |
从数据量来看 车票信息 > 支付信息 > 短信信息 > 余票信息 > 旅客信息 > 车次停靠信息 > 车次信息
从如此数据量来看,必须进行分库分表。所以分库分表就在设计库的时候就显的非常重要。
2 简单分库策略
旅客信息相关的信息单独分在一个库,这些数据相对来说是读多写少,并且可以大量进行缓存,是基础相数据。
车次相关的信息,比如车次,车次停靠可以单独放在一个标里面,这个标是保存原数据信息,数据量不大,数据完全可以缓存。可以考虑和余票库放在一次。
剩下就是四大的实体信息,余票信息,车票信息,支付信息,短信通知信息,首先短信通知信息相对来说比较通用的,可能未来很多业务都会涉及到短信通知,所以短信相关的信息放在一个库
在剩下就是考虑业务上比较耦合的三个实体:余票,车票,支付。
余票查询频繁,每出一张票,就会更新余票数
车票数据量巨大,有查询和更新需求
支付信息:单笔查询和更新需求
考虑到车票和支付信息在数据量级上远远高于余票信息,余票信息单独一个库,而车票信息和支付信息业务上差异比较大,也单独分出来。
根据以上的分析,可以分出来5个逻辑库:旅客库,车票库,短信库,车次库(车次信息,余票信息),支付库。
继续往下分析,在5个逻辑库里面,由于旅客库数据量有上线,只需要分配一个实体库即可。 车次库增长有限,也暂时分配一个实体库里面。而车库票,支付库,短信库数据量比较大,分配一个实体库显然不够。下面单独分析这三个逻辑库的分库策略
3 车票库分库策略
对于车票信息的分库策略,需要考虑到以下几个因素
1. 功能需求
查询需求:按照购票日期 + 旅客信息 + 状态 或者 旅客 + 发车日期 + 状态
统计需求:按发车日期统计购票总数量和金额 或者其他几个维度
交易需求:创建车票信息,更新车票状态,创建关联支付信息
对账需求:(假设不考虑退票需求)按照支付日期统计支付流水总金额 以及 统计 支付成功的车票信息总金额
2. 负载均衡
按照数据库处理实时要求进行分析,响应要求高的请求和耗时类请求分开,优先保证能够卖出票,支付车票。同时不能所有的请求都指向一个库。
3 高可用性
避免单点,否则购票功能就不可用。所以数据库至少有备份机制。
4 数据均匀
避免大多数据都在同一个库,否则遇到大数据查询数据库负载会很高,进而影响系统整体的可用性。因为大多数请求都会排队,导致系统资源耗尽。
5 可扩展性
当数据增长过快时候,能够很灵活的添加数据库而整个应用不需要做太大的修改
根据以上几个因素考虑,每一张车票生成一个全局的唯一性id,根据id最后一位数字/N平均把数据分配到N个数据库中,这样每张车票库最多可以分成10个库,可扩展性不强。也可以考虑一致性hash算法进行分库,但是这个比较复杂。还有一种方式就是随机分库,好处是可以无限扩展数据库,但是会给查询带来很大的影响。考虑到查询需求,太多的库可能导致查询复杂,甚至在有限时间内无法查询出来。这里采用最后数字/N的方式进行分库,N为数据库的个数。在这个基础上,在增加一个库,就是历史库,暂时只需要一个即可,把完结的历史数据迁移到这个库,一个季度之前的数据不需要在进行操作,一般只是查询需求,就迁移到这个库里面,减少交易库的压力。
这里分10个线上库,一个历史库。一共11个库。能够支持年100亿的交易规模。不过对于对账的需求,可以考虑另外的方式来实现。这里以后在说。
下面一幅图展示了分库的模型:

通过以上的分库策略,如果某一个库宕机了,会影响1/10的购票用户。
4 余票库分库策略
余票库虽然数据量没有车票库数大,但是查询和更新需求远比车票库频繁。而且是整个业务的关键路径。在考虑这个库的只需要保持一个月的数据即可,一个月前的数据可以迁移走,不需要所有的数据。而在春运期间,这个库的瞬间访问量会飙升,相当于淘宝的秒杀,要求实时性比较高,所以不太可能读写分离。综合考虑,可以分为两个库, 线上库和历史库。历史库用来做分析。这个后续是设计的重点。
5 支付库分库策略
支付信息和车票信息这两个库有点类似,只是用户查询相对来说比较少。这个支付库分库策略和车票库的策略可以一样。
6 短信库分库策略
由于短信通知是全站业务,这个完全可以独立与购票业务。消息量大,但非关键业务,非系统关键路径,对实时行要求不高,所以简单分成两个库即可。
在分库之后,数据一致性要求就会比较高,涉及到分布式事务 ,后续会重点讨论分布式事务的设计。
先写到这里吧,下一篇 会分析表结构以及分表策略和索引。
原文链接:http://www.cnblogs.com/aigongsi/archive/2012/09/17/2683656.html
【编辑推荐】
- ASP.NET Web开发框架项目介绍
- YQBlog .NET MVC3博客系统之用户系统实战
- ASP.NET Cache的一些总结
- ASP.NET中常用的几种身份验证方式
- 各自为政:ASP.NET实现团队分工的思考












