近日,《连线》杂志编辑凯德·梅茨近日在这份杂志的网络版上撰文称,谷歌的大数据工具Hadoop已经衍生出了两个开源平台,这两个平台分别是由硅谷创业公司Cloudera和MapR所构建的。其中,MapR已经发布了一个名为Drill的开源项目,寻求模仿谷歌的数据分析工具。
以下是这篇文章的全文:
在硅谷邱吉尔俱乐部最近召开的一次会议上,迈克·奥尔森和约翰·施罗德共用了一个讲台,但这两人的观点并不完全一致。
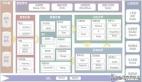
奥尔森是一家名为Cloudera的硅谷创业公司的首席执行官,施罗德则是MapR的首席执行官,这家公司很明显是Cloudera的竞争对手。两家公司都在开源云计算软件平台Hadoop上经营自身业务,这个平台以数据中心技术为基础,这种技术为谷歌占据互联网市场主导地位的搜索引擎提供支持。但在构建各自业务的问题上,这两家创业公司是从两个十分不同的方向靠近这个平台的。
Cloudera与开源Hadoop项目密切合作,目的是增强这个平台免费向全世界提供的软件代码;而与此相比, MapR则决定从头开始重新建设这个平台,而当这项工作完成以后,这家公司会将新的代码作为专有软件出售。在上个月专为Hadoop召开的一次专题讨论会上,奥尔森和施罗德登上讲台,就哪家公司的方法最有意义进行了面对面的辩论。正如开源项目成为讨论主题的许多时刻那样,他们两人之间的争论也引发了听众们的热议。
施罗德表示,MapR不一定非要反对开放式的开发。他解释称,这家公司之所以保密其所开发的代码,至少有部分原因在于那些推动这个开源项目的人不愿迅速地作出MapR希望作出的改变。“在开源社区中有很多政治性的问题需要考虑。”他说道。“情况会因你所处的状况而有所不同。”
似乎是为了证明他的这一观点,MapR已经推出了另一个开源项目,旨在将其作为Hadoop平台的重大补充。MapR最近向阿帕奇软件基金会——负责管理Hadoop的非盈利开源组织——提出了一个项目,其目标是模仿Dremel,这是一种由谷歌开发和使用的十分有效的数据分析工具。这个项目名为Drill,管理该项目的MapR负责人托莫·希兰表示,该项目适合完全开放式的开发,这是该公司最初的Hadoop项目所不具备的特点。通过Hadoop平台,MapR以往的作法是与一个根深蒂固的开发者社区就一个现有的项目展开合作。而在有了Drill以后,这家公司正在开创某种新的东西。
希兰表示,MapR之所以将Drill的开发对外开放,其原因在于该公司希望将这个平台变成能迅速分析在Hadoop上所存数据的业界标准。这家公司希望能促进Drill的应用程序接口的使用,允许用户将其他工具嵌入这个平台。
“这是一套新的应用程序接口,这是一个新的系统。”希兰说道,他此前曾供职于惠普和IBM旗下的研究部门。“如果这些新的应用程序接口是开放的,那么肯定会有助于提高使用量。”
通过建设开放式的Drill项目,这家公司可能还希望赢得全球开发者和IT经理的某种认同;在构建自己专有版本的Hadoop平台时,该公司失去了这种认同。希兰对此作出了否认,但开源社区中的政治性问题会在许多不同的地方出现——正如上个月在邱吉尔俱乐部召开的主题讨论会所明确表明的那样。当时,施耐德表示MapR对开源“意识形态”问题并不感到担心,因此招来了激烈的质问。开源软件代码的理由几乎从来都不明确,但很明显的一个问题是,在当今的软件市场上,保持代码的开源性正日益成为从事相关业务的重要组成部分。
这不仅有助于扩大软件代码的使用度,同时还能有助于传播商誉——而商誉对于一家公司来说也是非常重要的。#p#
当MapR从2009年开始致力于在Hadoop平台上进行开发工作时,这个平台已经在整个互联网范围内被广泛使用。基于描述了MapReduce和谷歌文件系统——这是两个意义深远的软件平台,它们重新创造了谷歌构建自身搜索索引的方式——的研究报告,Hadoop被雅虎、Facebook及其他公司作为使用数以千计的廉价服务器来运算海量数据的工具。作为这种工具来说,Hadoop是非常有效的——一名Facebook工程师曾将其比作我们所呼吸的空气——但从某种程度上来说,象雅虎和Facebook这样缺乏工程专业知识的公司并不太适合使用这种工具。
MapR解决了许多缺陷——其中包括曾困扰谷歌文件系统的一个显而易见的缺陷等——但据施耐德和公司联合创始人斯莱瓦斯M.C. Srivas称,那些推动开源项目的人不愿象MapR所希望的那样迅速地作出这些改变。因此,MapR自己对文件系统进行了重新构建,并在2011年发布了自己专有版本的Hadoop,决心为其所做的工程工作谋求财务利益。
正如奥尔森所指出的那样,开源Hadoop项目已经解决了许多同样的问题;而且他相信,从长期来看保持这个平台的核心代码的开放性是一种好得多的解决方案。“最重要的一个问题在于,你想要开源软件,因为这种软件能突破厂商的封锁。”他在上个月召开的主题讨论会上说道。“你可以把厂商踢出去,而且我们无法关闭数据的可获得性,无法关闭分析信息的可获得性,也无法关闭数据库的可获得性。”
但施耐德则极力主张,奥尔森和Cloudera同样也提供专有软件——以Hadoop管理工具的方式——而且他还指出,所有软件公司都必须找到某种方法来利用自己的代码赚钱。有许多方法能做到这一点,而在推出Drill项目以后,MapR也已经证明,这家公司同样也看重开放式开发的价值。
希兰指出,第三方开发者已经表现出自己对这个项目的兴趣。在MapR向阿帕奇软件基金会提交的Drill计划中,两名第三方开发者——分别是一家名为Concurrent的公司的创始人兼首席执行官克里斯·温瑟尔和Drawn to Scale的工程副总裁赖安·罗森——被列为这个项目的核心开发者。
虽然希兰指出MapR已经对Hadoop平台及其各个姊妹项目作出了开源贡献,但Drill则有所不同,原因是这家公司计划开放式地构建整个平台。按希兰所说,这样做是有必要的。虽然谷歌在2010年发布了一份描述Dremel的研究报告,但Hadoop社区仍有待复制其相当惊人的数据分析技术,而MapR则希望确保能以“正确的方法”做到这一点。希兰表示,这是MapR无法通过Hadoop做到的事情。
没错,Hadoop已经被作为一种数据分析工具来被人们使用,这种使用应归功于Hive和Pig等姊妹项目;但Hadoop是一个“批处理”工具,这意味着数据请求需要相当长的一段时间才能完成。而与此相比,Drill的设计目的则是效法Dremel,对海量数据进行几乎实时的分析。据谷歌基础设施专家乌尔斯·霍泽尔称,Dremel能在大约三秒钟时间里处理1拍字节的数据。
“你拥有一种类似于SQL的语言,能让制定专设的查询请求变得非常简单——而且,你不需要做任何编程工作,只需将查询请求输入到命令行里即可。”霍泽尔在上个月向我们说到,他所指的SQL是Structured Query Language,这是传统数据库用来处理数量少得多的数据的一种语言。
希兰表示,Drill的设计目的是为Hadoop提供补充,而并非取代后者。他指出,就转换一个庞大的数据集而言,Hadoop是一种最好用的工具。举例来说,你可以通过海量的网页集合来建设一个搜索索引;但Drill则允许你从同一个数据集中非常迅速地抽取一小部分信息。
“能对一拍字节的数据进行运算,将其变成新的数据。”希兰说道。“通过Dremel或是Drill,你能对一拍字节的数据进行分析,然后得出一拍字节或少于一拍字节的数据。”他表示,MapR的一些用户已在将该公司专有版本的Hadoop平台与谷歌在线服务BigQuery配合使用,后一种服务能让谷歌以外的公司使用Dremel。
希兰称,Drill这个名称是由一名谷歌员工提议的,MapR曾与这名员工合作开发BigQuer。MapR的联合创始人斯莱瓦斯也曾在谷歌供职,当时他曾是谷歌搜索基础设施建设团队的成员之一。就谷歌官方而言,这家公司并未正式参与Drill项目。通过这些庞大的基础设施平台,谷歌倾向于去做自己的事情。
MapR也一直都以做自己的事情而著称,但这一次则并非如此。