1.MongoDB shell
MangoDB其实是数据库shell.一般假定它和mongod运行在同一台机器上,还假定了mongod绑定了默认端口.
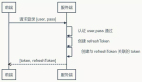
如果不是这样的话,可以在启动时指定这些参数,让shell连接另一台服务器:
- mongo 192.168.10.10:10000
这样就会连接运行在192.168.10.10上端口为10000的mongod
shell默认连接test数据库,要使用别的数据库,在服务器地址后添加斜杠和数据库名:
mongo 192.168.10.10:10000/refactor
这样会连接192.168.10.10:10000上的refactor数据库
也可以用--nodb选项启动shell,而不连接任何数据库,而只是试试javascript
mongo --nodb
db绝不是仅有的数据库,从shell中可以连接任意多的数据库,这对多个服务器的环境很方便.调用connect(),
并将结果赋值给变量.如在分片环境中,可能想用mongos表示mongos服务器,还想要有每个片的连接,可以
如下操作:
mongos=connect("127.0.0.1:10000")
shard0=connect("127.0.0.1:10001")
shard1=connect("127.0.0.1:10002")
这样就能将mongos,shard0,shard1作为db变量使用.
shell工具
对于管理多个数据库,有多个数据库变量就比简单的db有用处,如在分片中,
要维护一个单独的只想配置服务器的变量:
config=db.getSisterDB("config")
config.shards.find()
2.BSON
MongoDB的文档是个抽象概念,其具体的呈现形式取决与使用的驱动和编程语言.
因为MongoDB中的通信大量依赖于文档,所以需要一种所有驱动,工具和进程都能共享的文档表达方式.
这种表达方式叫Binary JSON(BSON)
BSON是轻量级的二进制格式,能将MongoDB的所有文档表示为自己字符串.数据库能理解BSON,存在磁盘上的文档
也是这种格式.
当驱动要插入文档,或者将文档作为查询条件,驱动会将文档转化成BSON,然后再发往服务器.同样,返回到客户端的文档
也是BSON格式的字符串.驱动需要将这些数据解码,编程本机的文档表示,***返回给客户端.
用BSON的三个主要原因:
a.效率
BSON设计用来更有效的表示数据,暂用更好的空间.最差的情况下,BSON比JSON效率略低,***的情况下(
比如存放二进制数据或着大多数),BSON要比JSON要高效的多.
b.可遍历行
有些时候BSON牺牲了空间效率,换取更容易遍历的格式.如,在字符串前面加入其长度,而不是在结尾处使用一个终结符
这对MongoDB的内嵌文档很有用.
c.性能
BSON编码和解码速度都很快.它用C风格的表现方式表示类型,在大多数编程语言中都很快.
2.MongoDB的传输协议
驱动在TCP/IP协议的基础上简单封装了MongoDB传输协议,用来与MongoDB交互.
MongoDB的传输协议基本上是对一个简单封装的BSON数据,如,插入消息会有20字节的头部数据(包括
告知服务器执行写入操作的代码,以及消息长度,要插入的集合名,要插入的BSON文档列表)
3.数据文件
MongoDB的数据目录中,每个数据库都有几个独立的文件.每个数据有一个.ns文件和若干数据文件,数据文件以
递增的数字结尾,所以,数据库refactor会被存放在refactor.ns,refactor.0,refactor.1等文件中.
每个新的以数字结尾的数据文件大小会加倍,直到达到***值2GB.这是为了让小数据库不浪费太多的磁盘空间,
同时让大数据库使用磁盘上连续的空间.
MongoDB为了保证性能还会预分配数据文件(可以用--norealloc关闭这一功能).预分配在后台完成,有数据文件
被填满时就会自动启动.这意味着MongoDB服务器总是视图在每一个数据库保留一个额外的空数据文件来避免
文件分配产生的阻塞.
4.命名空间和数据域
在数据文件内部,每个数据库都是按照 命名空间 组织的,一种类别的数据与其它类别的分开存放.每个集合的文档都有
自己的命名空间,索引也是.命名空间的元数据存放在数据库的.ns文件中.
每个命名空间的数据都被分成若干组,放到数据文件的某一个区域内,这个区域成为数据域.
如图:
数据库foo有3个数据文件,其中第3个是预分配的空文件.前两个数据文件被分成几个数据域,属于几个不同的命名空间
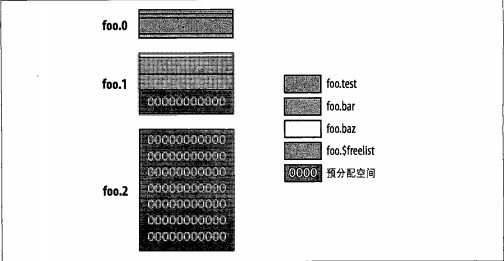
每个命名空间可以有几个不同的数据域,在磁盘上不必连续.类似于数据库的数据文件,每次新分配的命名空间
的数据域大小也会增加.这是为了平衡命名空间浪费的控件和尽量让一个命名空间的数据连续做出的这种.
图中还有个特殊的命名空间$freelist,存放这不再使用的数据域(如删除集合或索引产生的数据域).
当命名空间分配新的数据域时,系统会先查找空闲列表,看看有没有适合大小的数据域可用
5.内从映射存储引擎
MongoDB默认的存储引擎是内存映射引擎,当服务器启动后,将所有数据文件映射到内存,然后由操作系统来
负责将缓冲数据写入磁盘并将数据调入调出内存页面
这样的移情有若干重要的特性:
a)MongoDB管理内存的代码非常精炼,原因是将大部分工作交给了操作系统.
b)MongoDB服务器进程的虚拟大小通常会非常大,超过整个数据集的大小,这没关系,
因为操作系统会处理让那些数据常驻内存.
c)MongoDB不能控制数据写入到磁盘的顺序,也就不能用预写日志提供单机的持久性.
d)32位的MongoDB服务器有个限制,每个mongod最多处理2GB数据,这是因为所有数据必须能用32位地址访问到.
原文链接:http://www.cnblogs.com/refactor/archive/2012/08/15/2602348.html
【编辑推荐】