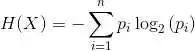决策树是一种简单的机器学习方法。决策树经过训练之后,看起来像是以树状形式排列的一系列if-then语句。一旦我们有了决策树,只要沿着树的路径一直向下,正确回答每一个问题,最终就会得到答案。沿着最终的叶节点向上回溯,就会得到一个有关最终分类结果的推理过程。
决策树:
- class decisionnode:
- def __init__(self,col=-1,value=None,results=None,tb=None,fb=None):
- self.col=col #待检验的判断条件
- self.value=value #对应于为了使结果为true,当前列必须匹配的值
- self.results=results #针对当前分支的结果
- self.tb=tb #结果为true时,树上相对于当前节点的子树上的节点
- self.fb=fb #结果为false时,树上相对于当前节点的子树上的节点
下面利用分类回归树的算法。为了构造决策树,算法首先创建一个根节点,然后评估表中的所有观测变量,从中选出最合适的变量对数据进行拆分。为了选择合适的变量,我们需要一种方法来衡量数据集合中各种因素的混合情况。对于混杂程度的测度,有几种度量方式可供选择:
基尼不纯度:将来自集合中的某种结果随机应用于集合中某一数据项的预期误差率。
维基上的公式是这样:

下面是《集体智慧编程》中的python实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def uniquecounts(rows): results={} for row in rows: # The result is the last column r=row[len(row)-1] if r not in results: results[r]=0 results[r]+=1 return results
def giniimpurity(rows): total=len(rows) counts=uniquecounts(rows) imp=0 for k1 in counts: p1=float(counts[k1])/total #imp+=p1*p1 for k2 in counts: if k1==k2: continue p2=float(counts[k2])/total imp+=p1*p2 return imp#1-imp |
每一结果出现次数除以集合总行数来计算相应概率,然后把所有这些概率值的乘积累加起来。这样得到某一行数据被随机分配到错误结果的总概率。(显然直接按照公式的算法(注释中)效率更高。)这一概率越高,说明对数据的拆分越不理想。
熵:代表集合的无序程度。信息论熵的概念在吴军的《数学之美》中有很好的解释:
我们来看一个例子,马上要举行世界杯赛了。大家都很关心谁会是冠军。假如我错过了看世界杯,赛后我问一个知道比赛结果的观 众“哪支球队是冠军”? 他不愿意直接告诉我, 而要让我猜,并且我每猜一次,他要收一元钱才肯告诉我是否猜对了,那么我需要付给他多少钱才能知道谁是冠军呢? 我可以把球队编上号,从 1 到 32, 然后提问: “冠军的球队在 1-16 号中吗?” 假如他告诉我猜对了, 我会接着问: “冠军在 1-8 号中吗?” 假如他告诉我猜错了, 我自然知道冠军队在 9-16 中。 这样只需要五次, 我就能知道哪支球队是冠军。所以,谁是世界杯冠军这条消息的信息量只值五块钱。 当然,香农不是用钱,而是用 “比特”(bit)这个概念来度量信息量。 一个比特是一位二进制数,计算机中的一个字节是八个比特。在上面的例子中,这条消息的信息量是五比特。(如果有朝一日有六十四个队进入决赛阶段的比赛,那 么“谁世界杯冠军”的信息量就是六比特,因为我们要多猜一次。) 读者可能已经发现, 信息量的比特数和所有可能情况的对数函数 log 有关。 (log32=5, log64=6。) 有些读者此时可能会发现我们实际上可能不需要猜五次就能猜出谁是冠军,因为象巴西、德国、意 大利这样的球队得冠军的可能性比日本、美国、韩国等队大的多。因此,我们第一次猜测时不需要把 32 个球队等分成两个组,而可以把少数几个最可能的球队分成一组,把其它队分成另一组。然后我们猜冠军球队是否在那几只热门队中。我们重复这样的过程,根据夺 冠概率对剩下的候选球队分组,直到找到冠军队。这样,我们也许三次或四次就猜出结果。因此,当每个球队夺冠的可能性(概率)不等时,“谁世界杯冠军”的信 息量的信息量比五比特少。香农指出,它的准确信息量应该是
= -(p1*log p1 + p2 * log p2 + ... +p32 *log p32), 其 中,p1,p2 , ...,p32 分别是这 32 个球队夺冠的概率。香农把它称为“信息熵” (Entropy),一般用符号 H 表示,单位是比特。有兴趣的读者可以推算一下当 32 个球队夺冠概率相同时,对应的信息熵等于五比特。有数学基础的读者还可以证明上面公式的值不可能大于五。对于任意一个随机变量 X(比如得冠军的球队),它的熵定义如下:

《集》中的实现:
|
1 2 3 4 5 6 7 8 9 10 |
def entropy(rows): from math import log log2=lambda x:log(x)/log(2) results=uniquecounts(rows) # Now calculate the entropy ent=0.0 for r in results.keys(): p=float(results[r])/len(rows) ent=ent-p*log2(p) return ent |
熵和基尼不纯度之间的主要区别在于,熵达到峰值的过程要相对慢一些。因此,熵对于混乱集合的判罚要更重一些。
我们的算法首先求出整个群组的熵,然后尝试利用每个属性的可能取值对群组进行拆分,并求出两个新群组的熵。算法会计算相应的信息增益。信息增益是指当前熵与两个新群组经加权平均后的熵之间的差值。算法会对每个属性计算相应的信息增益,然后从中选出信息增益最大的属性。通过计算每个新生节点的最佳拆分属性,对分支的拆分过程和树的构造过程会不断持续下去。当拆分某个节点所得的信息增益不大于0的时候,对分支的拆分才会停止:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
def buildtree(rows,scoref=entropy): if len(rows)==0: return decisionnode() current_score=scoref(rows)
# Set up some variables to track the best criteria best_gain=0.0 best_criteria=None best_sets=None
column_count=len(rows[0])-1 for col in range(0,column_count): # Generate the list of different values in # this column column_values={} for row in rows: column_values[row[col]]=1 # Now try dividing the rows up for each value # in this column for value in column_values.keys(): (set1,set2)=divideset(rows,col,value)
# Information gain p=float(len(set1))/len(rows) gain=current_score-p*scoref(set1)-(1-p)*scoref(set2) if gain>best_gain and len(set1)>0 and len(set2)>0: best_gain=gain best_criteria=(col,value) best_sets=(set1,set2) # Create the sub branches if best_gain>0: trueBranch=buildtree(best_sets[0]) falseBranch=buildtree(best_sets[1]) return decisionnode(col=best_criteria[0],value=best_criteria[1], tb=trueBranch,fb=falseBranch) else: return decisionnode(results=uniquecounts(rows)) |
函数首先接受一个由数据行构成的列表作为参数。它遍历了数据集中的每一列,针对各列查找每一种可能的取值,并将数据集拆分成两个新的子集。通过将每个子集的熵乘以子集中所含数据项在元数据集中所占的比重,函数求出了每一对新生子集的甲醛平均熵,并记录下熵最低的那一对子集。如果由熵值最低的一对子集求得的加权平均熵比当前集合的当前集合的熵要大,则拆分结束了,针对各种可能结果的计数所得将会被保存起来。否则,算法会在新生成的子集继续调用buildtree函数,并把调用所得的结果添加到树上。我们把针对每个子集的调用结果,分别附加到节点的True分支和False分支上,最终整棵树就这样构造出来了。
我们可以把它打印出来:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def printtree(tree,indent=''): # Is this a leaf node? if tree.results!=None: print str(tree.results) else: # Print the criteria print str(tree.col)+':'+str(tree.value)+'? '
# Print the branches print indent+'T->', printtree(tree.tb,indent+' ') print indent+'F->', printtree(tree.fb,indent+' ') |
现在到我们使用决策树的时候了。接受新的观测数据作为参数,然后根据决策树对其分类:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def classify(observation,tree): if tree.results!=None: return tree.results else: v=observation[tree.col] branch=None if isinstance(v,int) or isinstance(v,float): if v>=tree.value: branch=tree.tb else: branch=tree.fb else: if v==tree.value: branch=tree.tb else: branch=tree.fb return classify(observation,branch) |
该函数采用与printtree相同的方式对树进行遍历。每次调用后,函数会根据调用结果来判断是否到达分支的末端。如果尚未到达末端,它会对观测数据评估,以确认列数据是否与参考值匹配。如果匹配,则会在True分支调用classify,不匹配则在False分支调用classify。
上面方法训练决策树会有一个问题:
过度拟合:它可能会变得过于针对训练数据,其熵值与真实情况相比可能会有所降低。剪枝的过程就是对具有相同父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否会小于某个指定的阈值。如果确实如此,则这些叶节点会被合并成一个单一的节点,合并后的新节点包含了所有可能的结果值。这种做法有助于过度避免过度拟合的情况,使得决策树做出的预测结果,不至于比从数据集中得到的实际结论还要特殊:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def prune(tree,mingain): # 如果分支不是叶节点,则对其进行剪枝操作 if tree.tb.results==None: prune(tree.tb,mingain) if tree.fb.results==None: prune(tree.fb,mingain)
# 如果两个分支都是叶节点,则判断它们是否需要合并 if tree.tb.results!=None and tree.fb.results!=None: # 构造合并后的数据集 tb,fb=[],[] for v,c in tree.tb.results.items(): tb+=[[v]]*c for v,c in tree.fb.results.items(): fb+=[[v]]*c
# 检查熵的减少情况 delta=entropy(tb+fb)-(entropy(tb)+entropy(fb)/2)
if delta<mingain: # 合并分支 tree.tb,tree.fb=None,None tree.results=uniquecounts(tb+fb) |
当我们在根节点调用上述函数时,算法将沿着树的所有路径向下遍历到只包含叶节点的节点处。函数会将两个叶节点中的结果值合起来形成一个新的列表,同时还会对熵进行测试。如果熵的变化小于mingain参数指定的值,则叶节点也可能成为删除对象,以及与其它节点的合并对象。
如果我们缺失了某些数据,而这些数据是确定分支走向所必需的,那么我们可以选择两个分支都走。在一棵基本的决策树中,所有节点都隐含有一个值为1的权重,即观测数据项是否属于某个特定分类的概率具有百分之百的影响。而如果要走多个分支的话,那么我们可以给每个分支赋以一个权重,其值等于所有位于该分支的其它数据行所占的比重:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def mdclassify(observation,tree): if tree.results!=None: return tree.results else: v=observation[tree.col] if v==None: tr,fr=mdclassify(observation,tree.tb),mdclassify(observation,tree.fb) tcount=sum(tr.values()) fcount=sum(fr.values()) tw=float(tcount)/(tcount+fcount) fw=float(fcount)/(tcount+fcount) result={} for k,v in tr.items(): result[k]=v*tw for k,v in fr.items(): result[k]=v*fw return result else: if isinstance(v,int) or isinstance(v,float): if v>=tree.value: branch=tree.tb else: branch=tree.fb else: if v==tree.value: branch=tree.tb else: branch=tree.fb return mdclassify(observation,branch) |
mdclassify与classify相比,唯一的区别在于末尾处:如果发现有重要数据缺失,则每个分支的对应结果值都会被计算一遍,并且最终的结果值会乘以它们各自的权重。
对与数值型问题,我们可以使用方差作为评价函数来取代熵或基尼不纯度。偏低的方差代表数字彼此都非常接近,而偏高的方差则意味着数字分散得很开。这样,选择节点判断条件的依据就变成了拆分后令数字较大者位于树的一侧,数字较小者位于树的另一侧。