












将模型简单化,假设有三个表:tblA, tblB, tblC. 每个表包含三列:col1, col2, col3. 表的其它属性不考虑。
在不创建index的情况下,我们使用以下语句关联三个表:
- SELECT
- *
- FROM
- tblA, 5 tblB, 6 tblC 7 WHERE
- tblA.col1 = tblB.col1 9 AND tblA.col2 = tblC.col1;
对该语句使用EXPLAIN命令查看其处理情况:
+-------+------+---------------+------+---------+------+------+-------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra | +-------+------+---------------+------+---------+------+------+-------------+ | tblA | ALL | NULL | NULL | NULL | NULL | 1000 | | | tblB | ALL | NULL | NULL | NULL | NULL | 1000 | Using where | | tblC | ALL | NULL | NULL | NULL | NULL | 1000 | Using where | +-------+------+---------------+------+---------+------+------+-------------+
[http://www.cnitblog.com/aliyiyi08/archive/2008/09/09/48878.html]
查询机制
对于命令的查询机制,可以参照下MySQL manual(7.2.1)中的一段说明:
The tables are listed in the output in the order that MySQL would read them while processing the query. MySQL resolves all joins using a single-sweep multi-join method. This means that MySQL reads a row from the first table, then finds a matching row in the second table, then in the third table, and so on. When all tables are processed, MySQL outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.
正如上面所说,MySQL按照tblA, tblB, tblC的顺序依次读取数据,从EXPLAIN输出的信息结构看,之前的表查询的数据用来查找当前表对应的内容。即用tblA的值来查找tblB中满足条件的值,tblB的值用来查找tblC中满足条件的值。而当一次查找完成时(即三个表的值都查找过一次),MySQL并不会重新返回到tblA中的下一个数据重新开始,而是继续返回到tblB中的数据,来看tblB中是否还有其它行的值和tblA相匹配,如果有的话,继续到tblC,重复刚才的过程。这整个过程的关键原则就是:使用前一个表查询的数据来查找当前表对应的内容。
了解到MySQL在执行多表查询时使用前一个表查询的数据来查找当前表对应的内容这一原理后,那么创建Index的目的就是告诉MySQL怎么去直接找到下一个表的对应数据,如何按照MySQL需要的数据顺序来关联(JOIN)一个表。
再拿刚才的例子,tblA和tblB两个表通过条件 ”tblA.col1 = tblB.col1” 关联起来。我们首先获得tblA.col1,接下来MySQL需要的是来自tblB.col1的值,所以我们为它创建INDEX tblB.col1. 创建index后再次EXPLAIN之前的查询命令如下:
+-------+------+---------------+----------+---------+-----------+------+-------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra | +-------+------+---------------+----------+---------+-----------+------+-------------+ | tblA | ALL | NULL | NULL | NULL | NULL | 1000 | | | tblB | ref | ndx_col1 | ndx_col1 | 5 | tblA.col1 | 1 | Using where | | tblC | ALL | NULL | NULL | NULL | NULL | 1000 | Using where | +-------+------+---------------+----------+---------+-----------+------+-------------+
从结果中可以看出,MySQL现在使用key ‘ndx_col1’来关联tblB到tblA。也就是说,当MySQL查找tblB中的各行数据时,它直接使用key ‘ndx_col1’ 对应的tblA.col1来找到对应的行,而不是像之前那样进行全表扫描查找。
例子
举一个实例说明用法
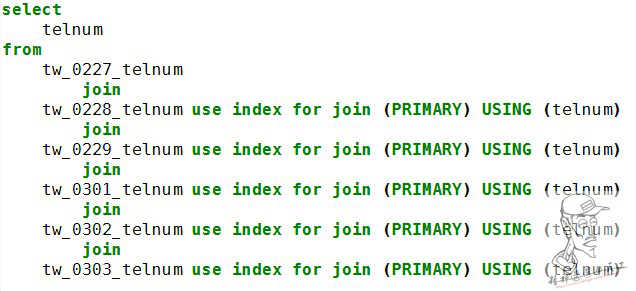
其中USING选择的参数,要求是每个表所共有且在每个表中值不重复,以保证index***。
join (PRIMARY)中PRIMARY参数为Index名,
表的属性中,作为index需要将参数勾选PK属性,即Primary Key。
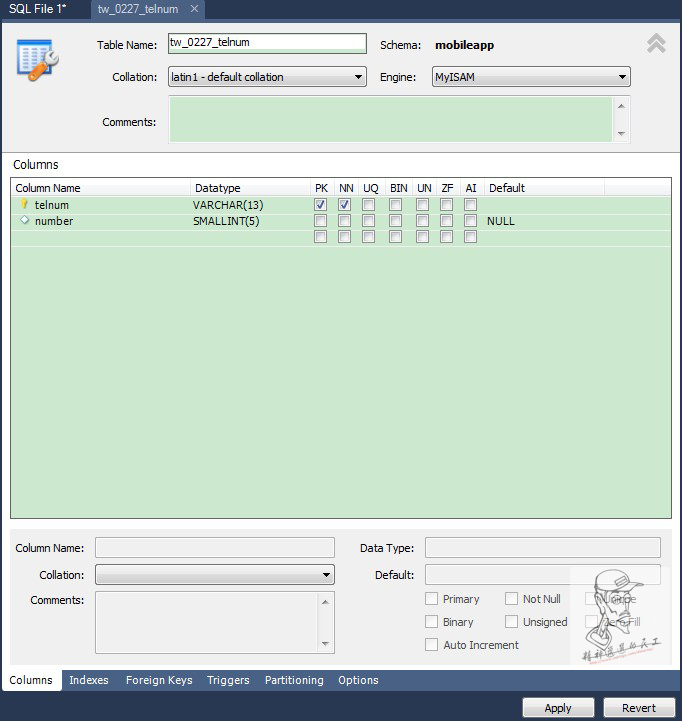
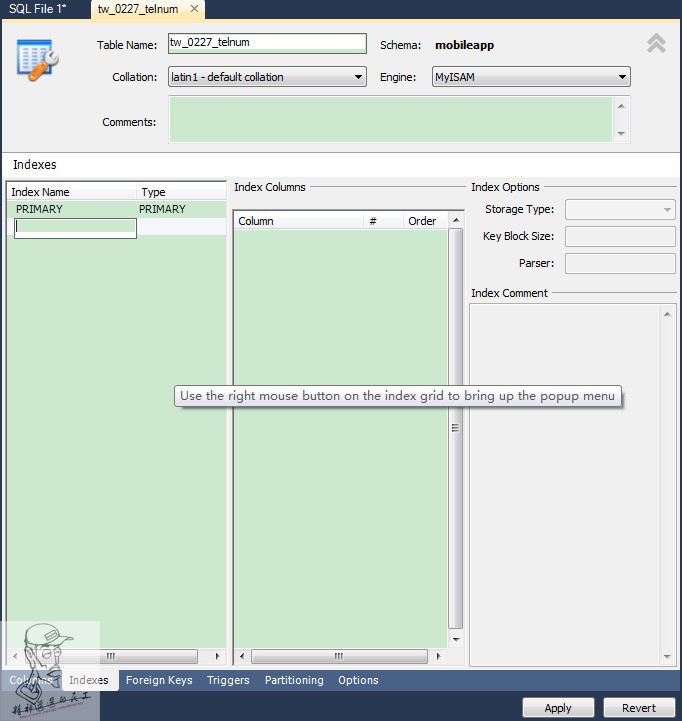
勾选telnum作为主键,需要将Default值中默认的NULL删除,PRIMARY_KEY不允许包含NULL值。
为每一个表创建了Index值后,EXPLAIN输出为:

对于MySQL,不管多复杂的查询,每次只需要按照EXPLAIN显示的顺序关联两张表中的内容。创建Index是为了让MySQL能够利用已经查找到的内容来快速找到下一张表的对应行内容。
原文链接:http://www.cnblogs.com/dwayne/archive/2012/07/06/MySQL_index_join_wayne.html
【编辑推荐】












