【51CTO快译】Facebook的工程师们开发出了一种方法,以规避Hadoop数据分析平台的一个根本缺点:只依赖单单一台名称服务器来协调所有运营。
在本周于加利福尼亚州圣何塞召开的Hadoop峰会上,Facebook工程师Andrew Ryan讨论了这种变通方法。他还在Facebook上发布了其演讲的摘要内容。
Facebook拥有可能是世界上规模最庞大的基于Hadoop分布式文件系统(HDFS)的数据集,总共超过100PB,散布于其诸数据中心的100个不同的集群之间。
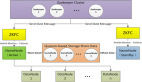
尽管Hadoop越来越经常用于大规模数据分析任务,但是用专业的话来说,它存在单一故障点。虽然部署的Hadoop系统可能横跨数百台、乃至数千服务器,但是整个运营依赖一台叫做名称节点(namenode)的单一服务器,负责协调诸数据节点之间的所有流量。要是这一个名称节点停止运行,那么诸数据节点就无法通信,整个系统将停止运行。
Facebook估计,如果可以克服这个缺点,就能将其数据仓库的停机时间缩短几乎一半。
为了解决这个问题,Facebook开发出了一款名为Avatarnode的软件:万一主名称节点由于某种原因而失效,该软件就会切换至备用名称节点。在这种架构中,每个数据节点会向主名称节点和备用名称节点定期发送***数据。万一主名称节点停止运行,那么备用名称节点就会顶上来,继续运行。这款软件以詹姆斯•卡梅隆执导的影片《阿凡达》命名,它依赖Hadoop Zookeeper配置管理工具。
这家公司将阿凡达节点作为一款开源软件来提供,希望Hadoop管理员们能够得益于使用该软件。Facebook早在2010年发布了该软件,后来被用于处理该公司的生产任务。
Ryan写道:“如今,阿凡达节点在运行我们Facebook内部要求***的生产工作负载,它会继续大幅提升HDFS集群的可靠性和可管理性。展望未来,我们会努力进一步改进阿凡达节点,并且将它与一种可以自动安全地进行故障切换的通用高可用性框架集成起来。”
不止Facebook这一家公司在试图解决Hadoop存在的这个问题。MapR和Cloudera的Hadoop发行版同样都随带冗余的名称节点功能。
原文:Facebook tackles Hadoop Achilles' Heel