云计算是在网格计算基础上新兴的计算模型,是互联网公司争相追逐的新技术。云计算作为一种商业计算模型,可以把任务分布在大量的计算机构成的资源池上。介绍了云计算的关键技术,这些技术包含虚拟机和计算模型等,还基于Hadoop对云计算模型进行了研究。
引言
云计算是由企业界开始发展,然后才进入学术界引起重视的,这与网格计算相反。经过对迄今为止的云计算相关学术论文进行统计分析后,显示学术界对于云计算的研究主要集中在云技术关键技术方面。云计算研究的关键技术包括虚拟机、安全管理、数据管理、云监测、能耗管理和计算模型等。云计算的计算模型是研究如何针对某类应用特点提出效率更高的编程方式,目前云计算模型众多,而Hadoop是一个开源的分布式系统基本架构,正日益成为具有较强实用性的开发平台.淘宝就是国内率先使用Hadoop的公司之一。
1云计算关键技术
1.1虚拟机
虚拟机是云计算的关键技术之一。目前在云计算中使用的主要虚拟机之一就是VMwareInfrastructure。它是一个虚拟数据中心操作系统,可以将离散的硬件资源统一起来以创建共享平台。其优点有:①整合服务器以降低IT成本;②暗哨计划内和计划外停机以改进业务连续性;⑧运行较少的服务器并且动态关闭不使用的服务器。
1.2安全管理
云计算是计算机资源的整合,通过云计算设施中的任何一台计算机,任何隐私信息都能够被找到。云计算安全问题已经成为急需解决的重要问题。其中,SianiPersion等提出了在云计算服务设计过程中保护用户隐私的一些设计原则:①发送尽量少的个人信息到云中,或者对系统进行分析后只对一小部分个人信息进行必要的收集和采集;②采用安全措施防止未授权的访问、复制、使用或者修改个人信息来保护云中的个人信息:③***限度地实现用户控制。在云计算环境中,让用户完全控制个人信息是比较困难的。要加强对个人信息的控制:一可以允许用户控制最重要的个人信息;二可以委托信任的第三方来管理:④允许用户对个人信息的使用进行选择,即加入、退出机制;⑤明确以及限制数据使用的目的。个人信息必须被身份明确的人使用和处理;⑥有反馈机制。即设计人及界面清楚地表明云服务中采取的安全措施,用其向用户提供安全提示。
1.3数据管理
云计算具有计算能力可变、数据储存在不信任的主机上、数据是远程复制等3个特点。从这3个特点分析而出,只有两种数据管理应用程序可能适合部署到云计算中:一是和事务处理相关的数据管理系统:另一种是和分析相关的数据管理系统。前者未采用共享的体系结构,在进行远程数据复制时很难满足ACID的需求,同时在不信任的主机上存储数据也有比较大的风险。ACID要求对于基于分析的数据管理系统来说不是必须的,同时可以保证敏感数据在分析之外,从而保证其安全。因此,基于分析的数据管理系统应该很合适部署到云计算环境中去。
1.4云监测和能耗管理
云监测是随着云计算的推广、云设施不断增加、为了更好地体现云计算的强大计算处理能力而设置的对虚拟机监控的能力:能耗管理是如何节省云设施中计算设施所需要的能源、有效整合资源、降低成本。
1.5云计算的计算模型
现行的分布式计算系统可以提供强大的计算能力.但非专业用户并不能有效地利用,一个庞大的任务很可能由于初学者的偶然操作导致性能的大幅下降。为了解决这些问题,应该提供给用户一个高度抽象的产品系统.这些就是云计算的计算模型。提到云计算模型,就不得不说一个开源框架,那就是Hadoop。
Hadoop是一个分布式系统基本架构。由Apache开发,使用户在不了解分布式底层细节的情况下,开发分布式程序。简单点说。Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(HadoopDistributedFileSystem),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX标准的要求。这样可以流的形式访问文件系统中的数据。
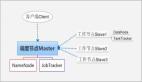
Hadoop采用Master/Slave结构(如图1),会有一台Mas.ter,主要负责NameNode的工作以及JobTracker的工作,Job.Tracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
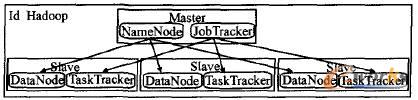
图1 Hadoop结构#p#
2 Windows下使用Hadoop实例的研究
2.1Windows下使用Hadoop的环境配置:
(1)安装Hadoop前,首先需要安装Cygwin
Cygwin是一个在Windows平台上运行的Unix模拟环境,提供了shel1支持。安装中需要选中Netcategory中的openssh。如图2所示。
图2 下载Cygwin安装包
(2)配置Windows系统变量
新建系统变量CYGWIN.变量值为ntsec tty编辑系统变量里的Path变量.加入C:\eygwin\bin
(3)安装Java,即安装idk,配置JAVA环境变量。
2.2 单机模式
(1)启动Cygwin,解压缩Hadoop安装包,例如Hapoop安装包位于e:\下,则解压命令为$tar—zxvf/cygdrive/e/hadoop一0.19.2.tar.gz。
解压默认目录在C:\cygwin\home\user文件夹下。
(2)编辑C:\cygwin\home\Administrato ad0op-0.19.2\conf里的hadoop-env.sh,将JAVA_HOME变量设置成JDK安装目录,如果路径中有空格,需要把Program Files改成Progra~1。
(3)配置完后即可运行WordCount实例。
在C:\cygwiI ome dministrator\hadoop-0.19.2下创建一个输入目录input.新建2个本文文件:
txt1.txt:yangshenyuan hello world hello hadooop
txt2.txt:yangshenyuan bye hadoop
然后运行实例,并将结果输出到output目录下:
$bin/hadoop jar hadoop-0.1 9.2-examples.jar wordeount inputoutput
2.3 伪分布模式

(2)安装配置SSH
启动eygwin,执行命令:$ssh-host—eonfig。
当询问“Shouldprivilegeseparationbeused”时.输入no;当询问”Doyouwanttoinstallsshdasaservice?”选yes;当提示“EnterthevalHeofCYGWINforthedaemon:[ntsee]”时,选择ntsec。
提示sshd服务已经在本地系统安装完毕。输入命令$netstartsshd,启动SSH,或者在Windows服务项里启动CYGWINsshd。
然后执行$ssh—keygen来生成密钥对.然后一直回车键确定。这样会把生产的密钥对保存在.ssh目录下。使用命令将RSA公钥加入到公钥授权文件authorized_keys中:


访问http://grid1:50070可以查看NameNote以及整个分布式文件系统的状态.访问http://gridl:50060可以查看TaskTraeker的运行状态。
运行完数据处理.查看结果和关闭Hadoop的操作和伪分布模式相同。#p#
3 结束语
虽然Hadoop支持Windows,但官网上同时声明Hadoop尚未在Windows下严格测试,建议只作为开发平台。
而且,格式化Hadoop文件系统是Hadoop启动的第一步,每次格式化前,要清空$HADOOP_HOME\tmp目录下的所有文件.因为Hadoop格式化时会重新建立NameNoteID.而tmp里还包含上次格式化留下的信息。格式化虽然清空了NameNote的数据,但是保留了DateNote的数据,这样会导致启动失败。
另外,在{HADOOP_HOME}\logs目录下,NameNode、DataNode、SecondaryNameNode、JobTracker、Tasktracker各有一个日志文件,当出现故障时,分析这些文件也许会有帮助。