在去年Techonomy会议上参加讨论时,谷歌CEO Eric Schmidt引用一个惊人的事实指出,我们现在每两天创造的信息和2003年以来整个历史上所创建的信息一样多。信息泛滥带来了一系列的技术突破,这让企业的数据存储扩展到数千亿字节甚至是数拍字节。谷歌在此领域的贡献是尤其值得注意,包括它在MapReduce上的工作,它是一种大型分布式数据处理的方法,谷歌采用此方法来记录位于索引资源(映射这些数据)收藏里的关键字或短语,接着再把这些位置的记录和清单返回给用户(将映射数据减少到紧密相关的结果)。映射和减少操作可以涵盖模式识别、图解分析、风险管理和预测模式。
虽然谷歌的MapReduce安装是专有的,还存在MapReduce概念的很多开源安装,包括Apache Hadoop。事实上,Hadoop已经是分布式数据处理的实际解决方案了,数十个国际公司已经从执行和开发两个方面大力投资该项目。Adobe、Amazon、AOL、Baidu、EBay、Facebook、Hulu、IBM、Last.fm、LinkedIn、Ning、Twitter和Yahoo等已成为用户,很多大学、医院和研究中心也都成为用户,采用并不受互联网重要人物的限制。
Hadoop项目介绍
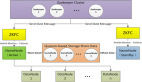
和Apache软件基金会(ASF)的很多项目一样,Hadoop是一个涵盖性术语,它分配基金会的全部措施来产生“可信、可扩展且分布式计算的开源软件”。现在的措施由四个子项目组成,包括:
- Hadoop Common:Hadoop Common形成Hadoop项目的核心,通过紧跟着的同胞项目提供所需的“管道装置”。
- HDFS:Hadoop分布式文件系统(HDFS)是遍及计算集群负责复制和分配数据的存储系统。
- MapReduce:MapReduce是开发人员用来编写应用的软件架构,这些应用处理那些存储在HDFS中的数据。
- ZooKeeper:ZooKeeper负责协调配置数据、进程同步和其它所有被分配应用有效运作所需的网络相关服务。因此,虽然你确实会以单一档案文件的形式下载Hadoop,记住,你正在下载的实际上是四个子项目,它们齐心协力来实施映射和归算处理。
用Hadoop做实验
尽管Hadoop试图解决的问题本质复杂,从运用这个项目开始会非常容易。作为一个例子,我认为用Hadoop来完成我“用PHP简化贝宝”一书中的词频率分析会很有趣。这个任务会仔细查看整本书(长度大概在130页左右),并且产生一个所有书中出现词语的分组列表,连同其中每个词出现在频率。
安装Hadoop之后,我用Calibre把我的书从PDF转成文本文档。Hadoop wiki还包含相似的指令,但由于比较近期的Hadoop配置过程改变,以前的资源包含略有更新的指令。
接下来我用下面的命令从临时位置把这本书复制到Hadoop分布式文件系统:
$ ./bin/hadoop dfs -copyFromLocal /tmp/easypaypalwithphp/ easypaypalwithphp
你可以通过运用以下命令确认复制成功:
$ ./bin/hadoop dfs -ls
drwxr-xr-x - hadoop supergroup 0 2011-01-04 12:48 /user/hadoop/easypaypalwithphp
紧接着,运用和Hadoop一起打包的示例WordCount脚本来执行词频率分析:
$ ./bin/hadoop jar hadoop-mapred-examples-0.21.0.jar wordcount \
> easypaypalwithphp easypaypalwithphp-output ...
11/01/04 12:51:38 INFO mapreduce.Job: map 0% reduce 0%
11/01/04 12:51:48 INFO mapreduce.Job: map 100% reduce 0%
11/01/04 12:51:57 INFO mapreduce.Job: map 100% reduce 100%
11/01/04 12:51:59 INFO mapreduce.Job: Job complete: job_201101041237_0002
11/01/04 12:51:59 INFO mapreduce.Job: Counters: 33
FileInputFormatCounters
BYTES_READ=274440
最后,你可以用以下命令查看输出内容:
$ ./bin/hadoop dfs -cat easypaypalwithphp-output/part-r-00000
...
Next 21
Next, 8
No 5
NoAutoBill 1
Norwegian 1
Not 2
Notably, 2
Note 5
Notice 6
Notification 13
...
示例WordCount频率分析脚本非常基本,对书中文本里的每一列分配同等的重量,包括代码。但是为了解析例如DocBook格式的文件并忽略代码而修改脚本则会是很烦琐的事情。无论如何,考虑一下你想要创建谷歌全球书籍词频统计器一类服务的情况,它查看超过520万本书的关键词语。
【编辑推荐】