Memcached是由DangaInteractive开发的,高性能的,分布式的内存对象缓存系统,如何最佳地使用memcached,以提升站点性能?大家一起来了解一下。
一、Memcached简介
memcached 常被用来加速应用程序的处理,在这里,我们将着重于介绍将它部署于应用程序和环境中的最佳实践。这包括应该存储或不应存储哪些、如何处理数据的灵活分布以 及如何调节用来更新 memcached 和所存储数据的方法。我们还将介绍对高可用性的解决方案的支持,比如 IBM WebSphere® eXtreme Scale。
所有的应用程序,特别是很多 web 应用程序都需要优化它们访问客户机和将信息返回至客户机的速度。可是,通常,返回的都是相同的信息。从数据源(数据库或文件系统)加载数据十分低效,若是每次想要访问该信息时都运行相同的查询,就尤显低效。
虽然很多 web 服务器都可被配置成使用缓存发回信息,但那与大多数应用程序的动态特性无法相适。而这正是 memcached 的用武之地。它提供了一个通用的内存存储器,可保存任何东西,包括本地语言的对象,这就让您可以存储各种各样的信息并可以从诸多的应用程序和环境访问这些信息。#p#
二、基础知识
memcached 是一个开源项目,旨在利用多个服务器内的多余 RAM 来充当一个可存放经常被访问信息的内存缓存。这里的关键是使用了术语缓存:memcached 为加载自他处的信息提供的是内存中的暂时存储。
比如,考虑这样一个典型的基于 web 的应用程序。即便是一个动态网站可能也会有一些组件或信息常量是贯穿页面整个生命周期的。在一个博客站点内,针对单个 blog post 的类别列表不大可能在页面查看间经常性地变更。每次都通过一个对数据库的查询加载此信息相对比较昂贵,特别是在数据没有更改的情况下,就更是如此。从图 1 可以看到一个博客站点内可被缓存的页面分区。
图1.一个典型的博客页面内的可缓存元素

将这种结构放在 blog 站点的其他元素,poster 信息、注释 — 设置 blog post 本身 — 进行推断,可以看出为了显示主页的内容很可能需要发生 10-20 次数据库查询和格式化。 每天对数百甚至数千的的页面查看重复此过程,那么您的服务器和应用程序执行的查询要远远多于为了显示页面内容所需执行的查询。
通过使用 memcached,可以将加载自数据库的格式化信息存储为一种可直接用在 Web 页面上的格式。并且由于信息是从 RAM 而不是通过数据库和其他处理从磁盘加载的,所以对信息的访问几乎是瞬时的。
再强调一下,memcached 是一个用来存储常用信息的缓存,有了它,您便无需从缓慢的资源,比如磁盘或数据库,加载并处理信息了。
对 memcached 的接口是通过网络连接提供的。这意味着您可以在多个客户机间共享单个的 memcached 服务器(或多个服务器,如本文稍后所示的)。这个网络接口非常迅速,并且为了改善性能,服务器会故意不支持身份验证或安全性通信。但这不应限制部署选项。 memcached 服务器应该存在于您网络的内部。网络接口的实用性以及可以部署多个 memcached 实例的简便性让您可以使用多个机器上的多余 RAM 来提高您缓存的整体大小。#p#
三、存储方法
memcached 的存储方法是一个简单的键/值对,类似于很多语言内的散列或关联数组。通过提供键和值来将信息存储到 memcached 内,通过按特定的键请求信息来恢复信息。
信息会无限期地保留在缓存内,除非发生如下的情况:
- 为缓存分配的内存耗尽 — 在这种情况下,memcached 使用 LRU(最近最少使用)方法从此缓存删除条目。最近未曾使用的条目会从此缓存中先删除,最旧的最先访问。
- 条目被明确删除 — 总是可以从此缓存内删除条目。
- 条目过期失效 — 各条目均有一个有效的期限以便针对此键存储的信息在过于陈旧时可从缓存中清除这些条目。
上述这些情况可以与您应用程序的逻辑综合使用以便确保缓存内的信息是最新的。有了这些基础知识后,让我们来看看在应用程序内如何能最好地利用 memcached。#p#
四、何时使用memcached?
在使用 memcached 改进应用程序性能时,可以对一些关键的过程和步骤进行修改。
在加载信息时,典型的场景如图 2 所示。
图2.加载要显示的信息的典型顺序

一般而言,这些步骤是:
- 执行一个或多个查询来从数据库加载信息
- 格式化适合于显示(或进一步处理)的信息
- 使用或显示格式化了的数据
在使用 memcached 时,为配合这个缓存,可对应用程序的逻辑进行稍许修改:
- 尽量从缓存加载信息
- 如果存在,使用信息的被缓存版本
- 如果它不存在:
- 执行一个或多个查询来从数据库加载信息
- 格式化适合于显示或进一步处理的信息
- 将信息存储到缓存内
- 使用格式化了的数据
图 3 是对这些步骤的总结。
图3.在使用memcached时加载适合于显示的信息

数据加载成为了至多三个步骤的一个过程,从缓存加载数据或从数据库(视情况而定)加载数据并存储在缓存内。
当这个过程首次发生时,数据将正常地从数据库或其他数据源加载,然后再存储到 memcached 内。当下一次访问此信息时,它就会从 memcached 拉出,而不是从数据库加载,节省了时间和 CPU 循环。
问题的另一个方面是要确保如果更改了要存储在 memcached 内的信息,在更新后端信息的同时还要更新 memcached 的版本。这会让图 4 内所示的这个典型顺序发生稍许变化,如 图 5 所示。
图4.在一个典型的应用程序内更新或存储数据

图 5 显示了使用 memcached 后发生了变化的流程。
图5.在使用memcached时更新或存储数据

比如,仍以博客站点为例,在博客系统更新数据库内的类别列表时,更新应该遵循如下顺序:
- 更新数据库内的类别列表
- 格式化信息
- 将信息存储到 memcached 内
- 将信息返回至客户机
memcached 内的存储操作是原子的,所以信息的更新不会让客户机只获得部分数据;它们获得的或者是老版本,或者是新版本。
对于大多数应用程序,这两个操作是您惟一需要注意的。在访问他人使用的数据时,它会自动被添加到这个缓存内,而且如果对该数据进行了更改,此缓存内也会自动进行更新。#p#
五、键、名称空间和值
memcached 另一个需要重点考虑的因素是如何组织和命名存储在缓存内的这些数据。从之前博客站点的例子中,不难看出需要使用一种一致的命名结构以便您能加载博客类别、历史和其他信息,然后再在加载信息(并更新缓存)时或者在更新数据(同样也要更新缓存)时使用。
使用的何种具体的命名系统特定于应用程序,但通常可以使用一种与现有应用程序类似的结构,并且这种结构很可能基于某种惟一识别符。当从数据库拉出信息或在整理信息集时,就会发生这种情况。
以 blog post 为例,可以在一个具有键 category-list 的项中存储类别列表。与此 post ID 对应的单个 post,比如 blogpost-29 相关的值都可以使用,而该项的注释则可以存储在 blogcomments-29内,其中 29 就是这个 blog post 的 ID。这样一来, 您就可以将各种各样的信息存储在缓存内,使用不同的前缀来标识这些信息。
memcached 键/值存储的简便性(以及安全性的缺乏)意味着如果您想要在使用同一个 memcached 服务器的同时支持多个应用程序,那么就可以考虑使用其他格式的量词来标识数据属于某种特定的应用程序。比如,可以添加像 blogapp:blogpost-29 这样的应用程序前缀。这些键是没有格式的,所以可以使用任何字符串作为键的名称。
在存储值的方面,应该确保存储在缓存内的信息适合于您的应用程序。比如,对于这个博客系统,您可能想要存储被博客应用程序使用的对象以便格式化博客信息,而不是原始的 HTML。如果同一个基础结构用在应用程序内的多个地方,这一点更具实用性。
大多数语言的接口,包括 Java™、Perl、PHP 等,都能串行化语言对象以便存储在 memcached 内。这就让您可以存储并随后从内存存储恢复全部对象,而不是在您的应用程序内手动重构它们。 很多对象,或它们使用的结构,都基于某种散列或数组结构。对于跨语言的环境,比如在 JSP 环境和 JavaScript 环境间共享相同信息,可以使用一种架构中立的格式,比如 JavaScript Object Notation (JSON) 甚或 XML。#p#
六、填充并使用memcached
作为一种开源产品以及一种最初开发用来工作于现有开源环境内的产品,memcached 受大量环境和平台支持。与 memcached 服务器通信的接口有很多,并常常具有针对所有语言的多个实现。参见参考资料 以获得常用的库和工具箱。
要列出所有受支持的接口和环境不太可能,但它们均支持 memcached 协议提供的基础 API。这些描述已经被简化并应用在不同语言的上下文内,在这些语言中,使用不同的值可指示错误。主要的函数有:
- get(key) — 从存储了特定键的 memcached 获得信息。 如果键不存在,就返回错误。
- set(key, value [, expiry]) — 使用缓存内的标识符键存储这个特定的值。如果键已经存在,那么它就会被更新。期满时间的单位为秒,并且如果值小于 30 天 (30*24*60*60),那么就用作相对时间,如果值大于 30 天,那么就用作绝对时间 (epoch)。
- add(key, value [, expiry]) — 如果键不存在就将这个键添加到缓存内,如果键已经存在就返回错误。如果您想要显式地添加一个新键而又不会因它已经存在而更新它,那么这个函数将十分有用。
- replace(key, value [, expiry]) — 更新此特定键的值,如果键不存在就返回一个错误。
- delete(key [, time]) — 从缓存中删除此键/值对。如果您提供一个时间,那么添加具有此键的一个新值就会被阻塞这个特定的时期。超时让您可以确保此值总是可以重新读取自您的数据中心。
- incr(key [, value]) — 为特定的键增 1 或特定的值。只适用于数值。
- decr(key [, value]) — 为特定的键减 1 或特定的值,只适用于数值。
- flush_all — 让缓存内的所有当前条目无效(或到期失效)。
比如,在 Perl 内,基本 set 操作可以如清单 1 所示的那样处理。
|
Ruby 内的相同的基本操作如清单 2 所示。
|
在两个例子中可以看到相同的基本结构:设置 memcached 服务器,然后分配或设置值。其他的接口也可用,包括适合于 Java 技术的那些接口,让您可以在 WebSphere 应用程序内使用 memcached。memcached 接口类允许将 Java 对象直接序列化到 memcached 以便于存储和加载复杂的结构。当在像 WebSphere 这样的环境内进行部署时,有两个事情非常重要:服务的弹性(在 memcached 不可用时如何做)以及如何提高缓存存储量来改进在使用多个应用程序服务器或在使用像 WebSphere eXtreme Scale 这样的环境时的性能。我们接下来就来看看这两个问题。#p#
七、弹性和可用性
有关 memcached 最常见的一个问题是:“若缓存不可用了,会发生什么情况呢?”正如之前章节中明示的,缓存内的信息不应该成为信息的的惟一资源。必须要能够从其他位置加载存储在缓存内的数据。
虽然,无法从缓存访问信息将会减缓应用程序的性能,但它不应该阻止应用程序的运转。可能会发生这样几个场景:
- 如果 memcached 服务宕掉,应用程序应该回退到从原始数据源加载信息并对信息进行显示所需的格式化。此应用程序还应继续尝试在 memcached 内加载和存储信息。
- 一旦 memcached 服务器恢复可用,应用程序就应该自动尝试存储数据。没有必要强制重载已缓存了的数据,可以使用标准的访问来用信息加载和填充缓存。最终,缓存将会被最常用的数据重新填充。
再次重申,memcached 是信息的缓存但并非惟一的数据源。memcached 服务器不可用不应该是应用程序的终结,虽然这意味着在 memcached 服务器恢复正常之前性能会有所降低。实际上,memcached 服务器相对简单,并且虽然不是绝对无故障的,但它的简单性的结果就是它很少会出错。#p#
八、分配缓存
memcached 服务器只是网络上针对一些键存储值的一个缓存。如果有多台机器,那么很自然地会想要在所有多余机器上设置一个 memcached 的实例来提供一个超大的联网 RAM 缓存存储。
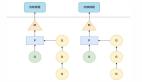
有了这个想法后,还有一种想当然是需要使用某种分配或复制机制来在机器之间复制键/值对。这种方式的问题是如果这么做反而会减少可用的 RAM 缓存,而不是增加。如图 6 所示,可以看出这里有三个应用程序服务器,每个服务器都可以访问一个 memcached 实例。
图6.多重memcached实例的不正确使用

尽管每个 memcached 实例都是 1 GB 的大小(产生 3 GB 的 RAM 缓存),但如果每个应用程序服务器只有其自己的缓存(或者在 memcached 之间存在着数据的复制),那么整个安装也仍只能有 1 GB 的缓存在每个实例间复制。
由于 memcached 通过一个网络接口提供信息,因此单个的客户机可以从它所能访问的任何一个 memcached 实例访问数据。如果数据没有跨每个实例被复制,那么最终在每个应用程序服务器上,就可以有 3 GB 的 RAM 缓存可用,如图 7 所示。
图7.多重memcached实例的正确使用

这个方法的问题是选择哪个服务器来储存键/值对,以及当想要重新获得一个值时,如何决定要与哪个 memcached 服务器对话。问题的解决方案就是忽略复杂的东西,比如查找表,或是寄望 memcached 服务器来为您处理这个过程。而 memcached 客户机则必须要力求简单。
memcached 客户机不必决定此信息,它只需对在存储信息时指定的键使用一个简单的散列算法。当想要从一列 memcached 服务器存储或获取信息时,memcached 客户机就会用一个一致的散列算法从这个键获取一个数值。举个例子,键 mykey 被转换成数值 23875 。是保存还是获取信息无关紧要,这个键将总是被用作惟一标识符来从 memcached 服务器加载,因此在本例中,“mykey” 散列转化后对应的值总是 23875。
如果有两个服务器,那么 memcached 客户机将对这个数值进行一个简单的运算(例如,系数)来决定它应将此值存储在第一个还是第二个配置了的 memcached 实例上。
当存储一个值时,客户机会从这个键确定出散列值以及它原来存储在哪个服务器上。当获取一个值时,客户机会从这个键确定出相同的散列值并会选择相同的服务器来获取信息。
如果在每个应用程序服务器上使用的是相同的服务器列表(并且顺序相同),那么当需要保存或检索同一个键时,每个应用程序服务器都将选择同一个 服务器。现在,在这个例子中,有 3GB 的 memcached 空间可以共享,而不是同一个 1 GB 的空间的复制,这就带来了更多的可用缓存,并很有可能会提高有多个用户情况下的应用程序的性能。#p#
九、如何能不使用memcached?
尽管 memcached 很简单,但 memcached 实例有时候还是会被不正确地使用。
memcached不是一个数据库
最常见的 memcached 误用就是把它用作一个数据存储,而不是一个缓存。memcached 的首要目的就是加快数据的响应时间,否则数据从其他数据源构建或恢复需要很长时间。一个典型的例子就是从一个数据库中恢复信息,特别是在信息显示给用户前 需要对信息进行格式化或处理的时候。Memcached 被设计用来将信息存储在内存中以避免每次在数据需要恢复时重复执行相同的任务。
切不可将 memcached 用作运行应用程序所需信息的惟一信息源;数据应总是可以从其他信息源获取。此外,要记住 memcached 只是一个键/值的存储。不能在数据上执行查询,或者对内容进行迭代来提取信息。应该使用它来存储数据块或对象以备批量使用。
不要缓存数据库行或文件
虽然可以使用 memcached 存储加载自数据库的数据行,但这实际上是查询缓存,并且大多数数据库都提供各自的查询缓存的机制。其他的对象,比如文件系统的图像或文件的情况与此相同。很多应用程序和 web 服务器针对此类工作已经有了一些很好的解决方案。
如果在加载和格式化后,使用它来存储全部信息块,就可以从 memcached 获得更多的实用工具和性能上的改善。仍以我们的博客站点为例,存储信息的最佳点是在将博客类别格式化为对象,甚至是在格式化成 HTML 后。博客页面的构造可通过从 memcached 加载各个组件(比如 blog post、category list、post history 等)并将完成的 HTML 写回至客户机实现。
为了确保最佳性能,memcached 并未提供任何形式的安全性,没有身份验证,也没有加密。这意味着对 memcached 服务器的访问应该这么处理:一是通过将它们放到应用程序部署环境相同的私有侧,二是如果安全性是必须的,那么就使用 UNIX® socket 并只允许当前主机上的应用程序访问此 memcached 服务器。
这多少牺牲了一些灵活性和弹性,以及跨网络上的多台机器共享 RAM 缓存的能力,但这是在目前的情况下确保 memcached 数据安全性的惟一一种解决方案。#p#
十、不要限制自己
除了不应该使用 memcached 实例的情况外,memcached 的灵活性不应忽视。由于 memcached 与应用程序处于相同的架构水平,所以很容易集成并连接到它。并且更改应用程序以便利用 memcached 也并不复杂。此外,由于 memcached 只是一个缓存,所以在出现问题时它不会停止应用程序的执行。如果使用正确的话,它所做的是减轻其余服务器基础设施的负载(减少对数据库和数据源的读操 作),这意味着无需更多的硬件就可以支持更多的客户机。
但请记住,它仅仅是个缓存!
结束语
在本文中,我们了解了 memcached 以及如何最佳地使用它。我们看到了信息如何存储、如何选择合理的键以及如何选择要存储的信息。我们还讨论了所有 memcached 用户都要遇到的一些关键的部署问题,包括多服务器的使用、当 memcached 实例消亡时该怎么做,以及(也许最为重要的)在哪些情况下不能使用 memcached。
作为一种开源的应用程序并且是目的简单而直白的应用程序,memcached 的功能和实用性均来自于这种简单性。通过为信息提供巨大的 RAM 存储空间、让它在网络上可用,然后再让它可通过各种不同的接口和语言访问到,memcached 可被集成到多种多样的安装和环境中。