












文本排版大家都并不陌生,并且随处可见,无论是当前的字处理软件,如Word、PDF等,还是传统的出版行业,如:书籍、报刊、杂志等,都有良好的排版风格和样式。好的排版风格让人耳目一新,有一种继续读下去的冲动。本文主要是通过Erlang实现简单的文本排版,借此学习Erlang、熟悉Erlang。
实战:文本排版。
要求如下:


在代码中我附了注释,代码如下:
- -module(text_process).
- -export([process/2]).
- -import(lists,[reverse/1]).
- process(FileIn,FileOut) ->
- {Status,Value} = file:open(FileIn,read),
- if
- Status =:= ok ->
- Tokens = readFile(Value), %% 将要处理文本FileIn拆分为单词列表
- io:format("token :~p~n",[Tokens]),
- writeToFile(FileOut,Tokens), %% 将单词重新排版输出到屏幕与文件FileOut
- io:format("~nsuccess!~n");
- Status =/= ok ->
- io:format("Open file error: file doesn't exist!")
- end.
- readFile(Value) -> readFile(Value,[]).
- readFile(S,Dict) ->
- OneLine = io:get_line(S,''), %%读取文件的一行
- if
- OneLine =:= eof ->
- io:format("~nCome across the file end, stop!~n"),
- file:close(S),
- Dict;
- OneLine =/= eof ->
- Tokens = string:tokens(OneLine,"\r\t\n "), %%以空格、回车、换行、制表符为单词分隔符
- Len = string:len(Tokens), %%获得字符串的长度
- if
- Len =:= 0 -> %%遇到空行,停止处理
- io:format("~nCome across blank line, stop!~n"),
- file:close(S),
- Dict;
- Len =/= 0 ->
- NewDict = string:concat(Dict,Tokens), %% 将Tokens连接到Dict尾
- readFile(S,NewDict) %%未读到空行、EOF,继续读取文本
- end
- end.
- writeToFile(FileOut,Tokens) ->
- {ok,S} = file:open(FileOut,write),
- Data = parse(Tokens,[]),
- String = lineToPara(Data),
- io:format("~n~s~n",[String]), %% 输出到屏幕
- io:format(S,"~s~n",[String]). %% 输出到文件
- %lists:foreach(fun({X}) -> io:format(S,"~s~n",[X]) end, Data).
- lineToPara(Data) -> lineToPara(Data,"").
- lineToPara([],Ret) -> Ret;
- lineToPara(Data,Ret) ->
- Last = lists:nth(1,Data),
- Element = element(1,Last),
- Temp = Ret ++ Element ++ "\n",
- %io:format("~s",[Temp]),
- lineToPara(lists:delete(Last,Data), Temp).
- %%解析单词列表
- parse(Tokens,Contents) ->
- M =50,
- {ALine,RemainToken} = parse_line(Tokens,M),
- if
- length(RemainToken) =:= 0 ->
- Plain = plain(ALine),
- io:format("last line----:~s~n",[Plain]),
- NewContent = lists:append(Contents,[{Plain}]);
- length(RemainToken) =/= 0 ->
- NewContent = lists:append(Contents,[{ALine}]),
- parse(RemainToken,NewContent)
- end.
- plain(Last) ->plain(Last, "").
- plain([], String) -> String;
- plain(L, String) ->
- if
- length(L) =:= 1 ->
- Last = lists:nth(1,L),
- NewS = string:concat(String,Last);
- length(L) =/= 1 ->
- First = lists:nth(1,L),
- Temp = string:concat(First," "),
- NewS = string:concat(String,Temp),
- plain(lists:delete(First,L), NewS)
- end.
- parse_line(Tokens,M) -> parse_line(Tokens,M,[]).
- %% @ Tokens: 当前剩余单词个数
- %% @ M:每行***字符阀值
- %% @ Line: 当前单词行列表
- parse_line([],_M,Line) -> {Line,[]};
- parse_line(Tokens,M,Line) ->
- if
- length(Line) =:= 0 ->
- Element = lists:nth(1,Tokens),
- NewL = length(Element),
- NewToken = lists:delete(Element,Tokens),
- parse_line(NewToken,M,[Element]);
- length(Line) =/= 0 ->
- Element = lists:nth(1,Tokens),
- NewL = len(Line)+length(Element)+length(Line),
- case NewL > M of
- true ->
- String = toString(Line,M),
- {String,Tokens};
- false ->
- NewLine = lists:append(Line,[Element]),
- NewToken = lists:delete(Element,Tokens),
- parse_line(NewToken,M,NewLine)
- end
- end.
- %% 排版输出当前行Line数据
- toString(Line,M) ->
- Len = len(Line),
- Blank = M - Len,
- %io:format("Blank:~p Len:~p length(Line):~p ~n",[Blank,Len,length(Line)]),
- Ret = justify(Line,Blank,length(Line)),
- io:format("Mess------Ret:~s length:~p~n",[Ret,length(Ret)]),
- Ret.
- justify(Line,Blank,Len) -> justify(Line,Blank,Len,"").
- %% @Line: 一行字符串数据
- %% @Blank:需要的空格个数
- %% @Len: 当前行中剩余的单词个数
- %% @String: 返回一行矫正结果
- justify(Line,Blank,Len,String) ->
- if
- length(String) =:= 0 -> %%初始情况
- Temp = lists:nth(1,Line),
- Avg = Blank div Len, %% 计算单词之间平均需要Avg个空格字符
- NewLine = lists:delete(Temp,Line),
- %io:format("1---avg: ~p Blank:~p Len: ~p~n",[Avg,Blank,Len]),
- case Avg =:= 0 of
- true ->
- NewS = while(1,Temp),
- justify(NewLine,Blank-1,length(NewLine),NewS);
- false ->
- NewS = while(Avg,Temp),
- justify(NewLine,Blank-Avg,length(NewLine),NewS)
- end;
- length(String) =/= 0 ->
- if
- length(Line) =:= 1 -> %%一行中***一个单词,返回结果
- Last = lists:nth(1,Line),
- NewS = while(Blank,String), %%将剩余的Blank个字符补全
- string:concat(NewS,Last);
- length(Line) =/= 1 ->
- First = lists:nth(1,Line),
- Avg = Blank div Len,
- NewLine = lists:delete(First,Line),
- %io:format("2---avg: ~p Blank:~p Len: ~p~n",[Avg,Blank,Len]),
- case Avg =:= 0 of
- true ->
- NewS = while(1,String),
- justify(NewLine,Blank-1,length(NewLine), string:concat(NewS,First));
- false ->
- NewS = while(Avg,String),
- justify(NewLine,Blank-Avg,length(NewLine), string:concat(NewS,First))
- end
- end
- end.
- %% 功能: 子字符串后面加Count个空格
- while(0,String) -> String;
- while(Count,String) ->
- NewS = string:concat(String," "),
- while(Count-1,NewS).
- %%统计一行中字符的个数(只包括单词字符,不包括空格)
- len(Line) -> len(Line,0).
- len([],Len) -> Len;
- len([H|T],Len) ->
- len(T,Len+length(H)).
看起来比较复杂,其实思路比较简单:
1.将文本切分单词列表;
2.设定一个阀值M,将每行的字符设置为M,同时必须保证单词不能分割;
我觉得此程序的难度主要是设定单词与单词之间的空格字符的问题,我的思路是:根据每行中所有单词所占的字符个数不同,求出单词之间空格的平均Avg个数,一般情况,单词与单词之间的字符个数为1,因此justify/4很好的处理了这个问题。
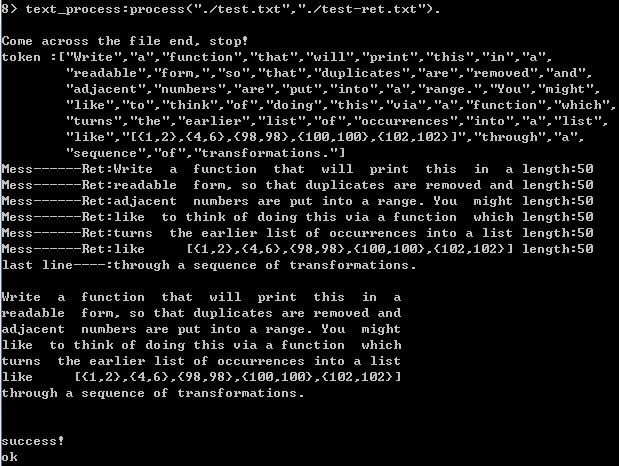
程序运行结果示意图如下:
test.txt文件内容:
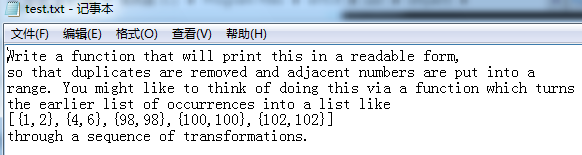
结果如下:
好了,文档排版Erlang实战就到此为止了。说个小问题,我在Erlang实战:杨辉三角、选择排序、集合交与并中的实战2:选择排序中不是用了两次列表逆置来讲一个元素加入到列表尾吗,其实Erlang中模块lists:append可以解决这个问题,我在本文代码中多次用到了这个函数,如:NewLine = lists:append(Line,[Element]),意思就是讲Element元素加入到列表尾,但是append函数的两个参数必须都为列表,因此Element元素需以列表形式加入:[Element],可见世上存在这样一条真理:只有你不知道的,没有不可能发生的。
原文:http://www.cnblogs.com/itfreer/archive/2012/05/08/Erlang_in_practise_text-process.html
【编辑推荐】














