Executor 框架是 juc 里提供的线程池的实现。前两天看了下 Executor 框架的一些源码,做个简单的总结。
线程池大概的思路是维护一个的线程池用于执行提交的任务。我理解池的技术的主要意义有两个:
1. 资源的控制,如并发量限制。像连接池这种是对数据库资源的保护。
2. 资源的有效利用,如线程复用,避免频繁创建线程和线程上下文切换。
那么想象中设计一个线程池就需要有线程池大小、线程生命周期管理、等待队列等等功能,下面结合代码看看原理。
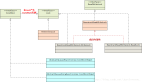
Excutor 整体结构如下:

Executor 接口定义了最基本的 execute 方法,用于接收用户提交任务。 ExecutorService 定义了线程池终止和创建及提交 futureTask 任务支持的方法。
AbstractExecutorService 是抽象类,主要实现了 ExecutorService 和 futureTask 相关的一些任务创建和提交的方法。
ThreadPoolExecutor 是最核心的一个类,是线程池的内部实现。线程池的功能都在这里实现了,平时用的最多的基本就是这个了。其源码很精练,远没当时想象的多。
ScheduledThreadPoolExecutor 在 ThreadPoolExecutor 的基础上提供了支持定时调度的功能。线程任务可以在一定延时时间后才被触发执行。
1、ThreadPoolExecutor 原理
1.1 ThreadPoolExecutor内部的几个重要属性
1.线程池本身的状态
- volatile int runState;
- static final int RUNNING = 0;
- static final int SHUTDOWN = 1;
- static final int STOP = 2;
- static final int TERMINATED = 3;
2.等待任务队列和工作集
- private final BlockingQueue<Runnable> workQueue; //等待被执行的Runnable任务
- private final HashSet<Worker> workers = new HashSet<Worker>(); //正在被执行的Worker任务集
3.线程池的主要状态锁。线程池内部的状态变化 ( 如线程大小 ) 都需要基于此锁。
- private final ReentrantLock mainLock = new ReentrantLock();
4.线程的存活时间和大小
- private volatile long keepAliveTime;// 线程存活时间
- private volatile boolean allowCoreThreadTimeOut;// 是否允许核心线程存活
- private volatile int corePoolSize;// 核心池大小
- private volatile int maximumPoolSize; // 最大池大小
- private volatile int poolSize; //当前池大小
- private int largestPoolSize; //最大池大小,区别于maximumPoolSize,是用于记录线程池曾经达到过的最大并发,理论上小于等于maximumPoolSize。
5.线程工厂和拒绝策略
- private volatile RejectedExecutionHandler handler;// 拒绝策略,用于当线程池无法承载新线程是的处理策略。
- private volatile ThreadFactory threadFactory;// 线程工厂,用于在线程池需要新创建线程的时候创建线程
6.线程池完成任务数
- private long completedTaskCount;//线程池运行到当前完成的任务数总和
1.2 ThreadPoolExecutor 的内部工作原理
有了以上定义好的数据,下面来看看内部是如何实现的 。 Doug Lea 的整个思路总结起来就是 5 句话:
- 如果当前池大小 poolSize 小于 corePoolSize ,则创建新线程执行任务。
- 如果当前池大小 poolSize 大于 corePoolSize ,且等待队列未满,则进入等待队列
- 如果当前池大小 poolSize 大于 corePoolSize 且小于 maximumPoolSize ,且等待队列已满,则创建新线程执行任务。
- 如果当前池大小 poolSize 大于 corePoolSize 且大于 maximumPoolSize ,且等待队列已满,则调用拒绝策略来处理该任务。
- 线程池里的每个线程执行完任务后不会立刻退出,而是会去检查下等待队列里是否还有线程任务需要执行,如果在 keepAliveTime 里等不到新的任务了,那么线程就会退出。
下面看看代码实现:
线程池最重要的方法是由 Executor 接口定义的 execute 方法 , 是任务提交的入口。
我们看看 ThreadPoolExecutor.execute(Runnable cmd) 的实现:
- public void execute(Runnable command) {
- if (command == null)
- throw new NullPointerException();
- if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
- if (runState == RUNNING && workQueue.offer(command)) {
- if (runState != RUNNING || poolSize == 0)
- ensureQueuedTaskHandled(command);
- }
- else if (!addIfUnderMaximumPoolSize(command))
- reject(command); // is shutdown or saturated
- }
- }
解释如下:
当提交一个新的 Runnable 任务:
分支1 : 如果当前池大小小于 corePoolSize, 执行 addIfUnderCorePoolSize(command) , 如果线程池处于运行状态且 poolSize < corePoolSize addIfUnderCorePoolSize(command) 会做如下事情,将 Runnable 任务封装成 Worker 任务 , 创建新的 Thread ,执行 Worker 任务。如果不满足条件,则返回 false 。
代码如下:
- private boolean addIfUnderCorePoolSize(Runnable firstTask) {
- Thread t = null;
- final ReentrantLock mainLock = this.mainLock;
- mainLock.lock();
- try {
- if (poolSize < corePoolSize && runState == RUNNING)
- t = addThread(firstTask);
- } finally {
- mainLock.unlock();
- }
- if (t == null)
- return false;
- t.start();
- return true;
- }
分支2 : 如果大于 corePoolSize 或 1 失败失败,则:
- 如果等待队列未满,把 Runnable 任务加入到 workQueue 等待队列
workQueue .offer(command) - 如多等待队列已经满了,调用 addIfUnderMaximumPoolSize(command) ,和 addIfUnderCorePoolSize 基本类似,只不过判断条件是 poolSize < maximumPoolSize 。如果大于 maximumPoolSize ,则把 Runnable 任务交由 RejectedExecutionHandler 来处理。
问题:如何实现线程的复用?
Doug Lea 的实现思路是 线程池里的每个线程执行完任务后不立刻退出,而是去检查下等待队列里是否还有线程任务需要执行,如果在 keepAliveTime 里等不到新的任务了,那么线程就会退出。这个功能的实现 关键在于 Worker 。线程池在执行 Runnable 任务的时候,并不单纯把 Runnable 任务交给创建一个 Thread 。而是会把 Runnable 任务封装成 Worker 任务。
下面看看 Worker 的实现:
代码很简单,可以看出, worker 里面包装了 firstTask 属性,在构造worker 的时候传进来的那个 Runnable 任务就是 firstTask 。 同时也实现了Runnable接口,所以是个代理模式,看看代理增加了哪些功能。 关键看 woker 的 run 方法:
- public void run() {
- try {
- Runnable task = firstTask;
- firstTask = null;
- while (task != null || (task = getTask()) != null) {
- runTask(task);
- task = null;
- }
- } finally {
- workerDone(this);
- }
- }
可以看出 worker 的 run 方法是一个循环,第一次循环运行的必然是 firstTask ,在运行完 firstTask 之后,并不会立刻结束,而是会调用 getTask 获取新的任务( getTask 会从等待队列里获取等待中的任务),如果 keepAliveTime 时间内得到新任务则继续执行,得不到新任务则那么线程才会退出。这样就保证了多个任务可以复用一个线程,而不是每次都创建新任务。 keepAliveTime 的逻辑在哪里实现的呢?主要是利用了 BlockingQueue 的 poll 方法支持等待。可看 getTask 的代码段:
- if (state == SHUTDOWN) // Help drain queue
- r = workQueue.poll();
- else if (poolSize > corePoolSize || allowCoreThreadTimeOut)
- r = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS);
- else
- r = workQueue.take();
2.ThreadFactory 和R ejectedExecutionHandler
ThreadFactory 和 RejectedExecutionHandler是ThreadPoolExecutor的两个属性,也 可以认为是两个简单的扩展点 . ThreadFactory 是创建线程的工厂。
默认的线程工厂会创建一个带有“ pool-poolNumber-thread-threadNumber ”为名字的线程,如果我们有特别的需要,如线程组命名、优先级等,可以定制自己的 ThreadFactory 。
RejectedExecutionHandler 是拒绝的策略。常见有以下几种:
AbortPolicy :不执行,会抛出 RejectedExecutionException 异常。
CallerRunsPolicy :由调用者(调用线程池的主线程)执行。
DiscardOldestPolicy :抛弃等待队列中最老的。
DiscardPolicy: 不做任何处理,即抛弃当前任务。
3.ScheduledThreadPoolExecutor
ScheduleThreadPoolExecutor 是对ThreadPoolExecutor的集成。增加了定时触发线程任务的功能。需要注意
从内部实现看, ScheduleThreadPoolExecutor 使用的是 corePoolSize 线程和一个无界队列的固定大小的池,所以调整 maximumPoolSize 没有效果。无界队列是一个内部自定义的 DelayedWorkQueue 。
ScheduleThreadPoolExecutor 线程池接收定时任务的方法是 schedule ,看看内部实现:
- public ScheduledFuture<?> schedule(Runnable command,
- long delay,
- TimeUnit unit) {
- if (command == null || unit == null)
- throw new NullPointerException();
- RunnableScheduledFuture<?> t = decorateTask(command,
- new ScheduledFutureTask<Void>(command, null,
- triggerTime(delay, unit)));
- delayedExecute(t);
- return t;
- }
以上代码会初始化一个 RunnableScheduledFuture 类型的任务 t, 并交给 delayedExecute 方法。 delayedExecute(t) 方法实现如下:
- private void delayedExecute(Runnable command) {
- if (isShutdown()) {
- reject(command);
- return;
- }
- if (getPoolSize() < getCorePoolSize())
- prestartCoreThread();
- super.getQueue().add(command);
- }
如果当前线程池大小 poolSize 小于 CorePoolSize ,则创建一个新的线程,注意这里创建的线程是空的,不会把任务直接交给线程来做,而是把线程任务放到队列里。因为任务是要定时触发的,所以不能直接交给线程去执行。
问题: 那如何做到定时触发呢?
关键在于DelayedWorkQueue,它代理了 DelayQueue 。可以认为 DelayQueue 是这样一个队列(具体可以去看下源码,不详细分析):
1. 队列里的元素按照任务的 delay 时间长短升序排序, delay 时间短的在队头, delay 时间长的在队尾。
2. 从 DelayQueue 里 FIFO 的获取一个元素的时候,不会直接返回 head 。可能会阻塞,等到 head 节点到达 delay 时间后才能被获取。可以看下 DelayQueue 的 take 方法实现:
- public E take() throws InterruptedException {
- final ReentrantLock lock = this.lock;
- lock.lockInterruptibly();
- try {
- for (;;) {
- E first = q.peek();
- if (first == null) {
- available.await();
- } else {
- long delay = first.getDelay(TimeUnit.NANOSECONDS);
- if (delay > 0) {
- long tl = available.awaitNanos(delay);//等待delay时间
- } else {
- E x = q.poll();
- assert x != null;
- if (q.size() != 0)
- available.signalAll(); // wake up other takers
- return x;
- }
- }
- }
- } finally {
- lock.unlock();
- }
- }
4.线程池使用策略
通过以上的详解基本上能够定制出自己需要的策略了,下面简单介绍下Executors里面提供的一些常见线程池策略:
1.FixedThreadPool
- public static ExecutorService newFixedThreadPool(int nThreads) {
- return new ThreadPoolExecutor(nThreads, nThreads,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>());
- }
实际上就是个不支持keepalivetime,且corePoolSize和maximumPoolSize相等的线程池。
2.SingleThreadExecutor
- public static ExecutorService newSingleThreadExecutor() {
- return new FinalizableDelegatedExecutorService
- (new ThreadPoolExecutor(1, 1,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>()));
- }
实际上就是个不支持keepalivetime,且corePoolSize和maximumPoolSize都等1的线程池。
3.CachedThreadPool
- public static ExecutorService newCachedThreadPool() {
- return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
- 60L, TimeUnit.SECONDS,
- new SynchronousQueue<Runnable>());
- }
实际上就是个支持keepalivetime时间是60秒(线程空闲存活时间),且corePoolSize为0,maximumPoolSize无穷大的线程池。
4.SingleThreadScheduledExecutor
- public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
- return new DelegatedScheduledExecutorService
- (new ScheduledThreadPoolExecutor(1, threadFactory));
- }
实际上是个corePoolSize为1的ScheduledExecutor。上文说过ScheduledExecutor采用无界等待队列,所以maximumPoolSize没有作用。
5.ScheduledThreadPool
- public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
- return new ScheduledThreadPoolExecutor(corePoolSize);
- }
实际上是corePoolSize课设定的ScheduledExecutor。上文说过ScheduledExecutor采用无界等待队列,所以maximumPoolSize没有作用。
以上还不一定满足你的需要,完全可以根据自己需要去定制。
原文链接:http://singleant.iteye.com/blog/1423931
【编辑推荐】