













无论是电信及金融行业,或是新兴的物联网、云计算,还是新应用层出不穷的互联网,每一刻都生成大量半结构化、非结构的数据。诸如目前最热门的微博应用,在非常显著的促进了用户交流和信息共享,但是由此也产生了大量信息,对于数据的定位和检索非常不便。市场调研公司麦肯锡表示,全球数据正以每年40%的速度增加,到2020年全球电子设备存储的数据将暴增30倍,达到35ZB(相当于10亿块1TB的硬盘的容量)。由此对各行各业电信运营商、电商、税务、金融、公安、等各个行业都会面对大数据计算的挑战。
大数据计算的挑战
1、 数据格式的挑战:数据的格式包括结构化数据、半结构化数据、非结构化数据、每种数据的处理方法和分析方法都有区别,分析和计算的难度大。
2、 数据分析方法的挑战:大数据技术的数据挖掘分为,关联分析、聚类分析、异常分析、特性群组分析、演变分析等,分析的数学模型需要很强的适应性。
3、 计算的时效性挑战:数据挖掘的实时计算,需要毫秒级的用户体验,需要瞬间把握数据动向和趋势。
4、 计算的成本的挑战:数据的存储和安全以及在未来访问和使用这些数据的存储成本、计算资源的成本必须改变过去大型机、小型机的计算模式,改为采用通用硬件的分布式计算的技术模式。
作为行业深度定制化智能网络及云计算解决方案提供商,汉柏在电信、政府等行业在数据挖掘积累了丰富的经验。汉柏大数据计算系统提供了高性能存储和查询检索,并提供简单可靠的存储扩展,从而能够提供便捷快速的数据搜索和检索定位。该方案通过云的手段提供海量数据挖掘的方法,提高了挖掘的效率,增加了挖掘的精度,有效提升客户业务效能。
汉柏数据挖掘模型

汉柏大数据计算模型
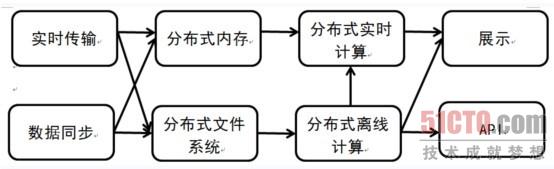
汉柏大数据计算的体系结构
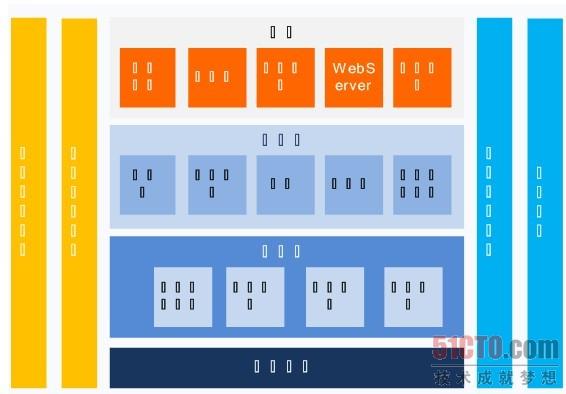
某客户应用案例
诸如,某省级电信运营商提供车载、手持和手机三个定位终端,上传轨迹数据,服务器获取数据后通过GIS(地理信息系统)在地图上实时展示终端当前的地理位置。车载和手持定位终端最小每隔10秒上传一次轨迹数据(包括终端ID、经纬度、方向、速度、里程、状态信息等)。静止状态下,终端页会每隔300秒上传一次数据,一次上传的数据大小为512字节,一个终端每天上传的数据约为2000条左右,数据大小约为1M。目前,该运营商约有20万个终端,每天的反馈数据量为4亿条,一天上传的数据容量为200GB。在采用了汉柏大数据计算系统后,不但良好支持了上亿数量级终端即千亿条记录,更能够横向扩展,从而良好解决数据分析的时效性、经济性,保证了数据的可靠性。
目前,汉柏大数据计算方案已经在广电行业、银行业以及某部委付诸实施,并与汉柏的多款定制化产品配合,取得了良好的应用效果。












