












以移动互联网、云计算为代表的新技术,带动信息通信业务创新节奏加快,通信终端越来越多,接入方式也趋于多样化,全球可用的存储、带宽、计算和信息系统正在呈现爆炸性增长。传统网络架构通常为了满足日益复杂的业务需求,需要部署大量的专有业务设备,使得网络结构日益复杂。随着企业和运营商对于业务智能化的需求越来越高,网络架构早已不再只是一个网络对应一种业务,融合成为必然的趋势,新一代企业网需要具备整合的云连接、应用感知、更全面的安全及统一策略控制等能力来更好的支撑企业传统业务及新业务。
思科ASR1000系列路由器是耗资2.5亿美元,耗费5年时间研制成功的一款汇聚多业务路由器,作为思科无边界网络(CiscoBorderlessNetwork)的重要组件,思科ASR1000系列汇聚服务路由器通过提供业界领先的性能、服务容量以及可信赖的紧凑结构,为服务提供商和企业打造了一个坚固的多业务汇聚网络边界。
业务至上—QuantumFlow处理器解析
思科在多年前已经意识到,在网络的边界随着新技术的使用,传统的网络处理器设计将无法满足日益多样化的业务需求。通用处理器(CPU)虽然可以灵活的通过软件编程实现新的业务,但缺乏流量优先级管理机制,并且转发效率相对较低,而传统的多核心网络处理器虽然能够提供很高的吞吐量,单由于使用微码编程并且受制于微码空间的限制无法进行灵活的报文处理,相对固定的流水线无法灵活的处理业务。
思科为这款处理器投入了一个接近600人的世界一流的开发团队,耗时5年开发完成这款QuantumFlow处理器,它将网络处理器技术推向了一个新的高度。它是一个具有高性能转发能力同时又兼备灵活的业务处理能力、大规模并行处理并集成多种业务和流量管理的高速网络处理器。它是业界第一款完全集成的可编程大规模多核心并行流处理器,集成了QoS和先进的内存管理机制并同时提供集成的多业务编程和业务交付能力。
QuantumFlow处理器架构:
CiscoQuantumFlow处理器视频简介
http://www.cisco.com/assets/cdc_content_elements/flash/netsol/sp/quantum_flow/demo.html
多核心并行处理
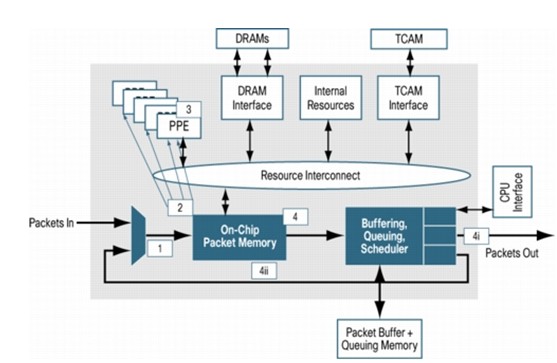
第一代QuantumFlow处理器(QFP)使用90nm工艺,QFP拥有40个定制QFP数据包处理引擎(PPE),每个PPE支持4个执行线程。利用多达160个并行运行的独立处理器线程,平均每线程功耗仅0.51W,远低于业界平均水平。同时QFP提供了一个高速的多核互联总线,确保每个内核都能及时快速的访问到相关的资源,并且能够避免在不够先进的硬件架构中常见的CPU过度使用和超长延迟问题,
而传统的网络处理器架构仅有少量的内核,因此需要使用交换矩阵或总线将多块网络处理器互联才能达到和QFP相同的处理速度,其功耗远高于QFP系统,而多块网络处理器资源互相访问将会带来大量的数据包延迟。
例如在运行SBC业务时,单块QFP可以并发处理68,000个语音流,其语音转发延迟仅56微秒(56microseconds),而另一个厂商的分布式平台则需要使用3个业务板卡通过交换网互联,共计六块传统网络处理器才能达到相同的语音流处理能力,同时转发延迟高达1毫秒。
先进的内存管理机制
QFP具有非凡的计算能力,在设计上采用了一个先进的内存管理架构,能够为其创新功能提供出色的支持。凭借高速、多级命令缓存,QFP能够快速地访问必要的代码,以便向任意数据包提供多项服务。
传统的网络处理器为了优化报文分类和处理速度并节省内存访问带宽,通常仅访问数据包头以获得较高的转发吞吐量,当这类处理器进行深度数据包检测(DPI),防火墙,网络地址转换(NAT),Netflow等复杂操作时,将会对性能造成不良影响。
QFP的PPE能够访问整个数据包,虽然在仅进行简单转发时报文处理速度稍低,但在并发部署多项高级服务时,性能并没有明显的下降。
简洁高效的编码能力
QFP是一款完全的基于C代码编程的网络处理器,与传统的基于微码编程的网络处理器相比,QFP可以更快的更好的实现新的业务。并可以完成对多种复杂业务的硬件加速处理,例如对BFD的硬件加速可以支持多达4,000个会话50ms的检测,并且QFP处理器占用率仅2%,而在对SBC接入用户快速注册的加速处理中,可以使得SBC功能可以满足多达720,000IP电话终端注册。
同时由于QFP对整个报文是可以见的,因此QFP还提供DPI流量控制功能,通过灵活的代码编写能力,QFP支持对多达1200种协议进行深度检测并进行报文分类和统计,统计信息直接通过QFP输出为Netflow格式日志报文,并配合灵活的QoS队列服务,实现了对用户对网络中的应用感知和控制(ApplicationVisibilityandControl,AVC)。
灵活的QoS处理能力
QFP提供了一个非常灵活的流量管理引擎,它有128,000个逻辑队列,用户能按任意层次结构对其进行分配,从而实施一个先进的分层流量管理系统,允许在一个数据包一次穿越ASR1000时应用多达5级的QoS调度,并且QFP还可以在多个信道上监控每秒数百万个事件,并配合NBAR等多种应用识别工具,使其成为当今业界最准确最灵活的流量控制引擎。
灵活的处理流水线
传统的网络处理器使用固定的流水线结构,使得在多种业务叠加时,不同的业务都要经过一个冗长的报文处理流水线,极大地影响了报文处理延迟和整机吞吐量。当需要增加新的业务时,通常需要很长的时间来修改整个流水线。
QFP可以为不同的业务类型提供灵活的流水线结构,节省了计算资源的消耗并同时降低了整机的报文延迟。并伴随着这种灵活的流水线结构使得多种业务可以快速的叠加在原有的网络架构下。
平衡之美—ASR1000架构浅析
集中式?分布式?
通过采用业界首款可扩展可编程型应用感知网络处理器CiscoQuantumFlow处理器,无需额外板卡,支持的服务包括安全服务(例如加密和防火墙)、服务质量(QoS)、基于网络的应用识别(NBAR)、CiscoIOS灵活数据包匹配(FPM)、宽带汇聚(BRAS)和会话边界控制器(SBC)等。可即时打开并以万兆位速度运行,无需牺牲网络性能或间断服务。
因此ASR1000通过集中式的QFP引擎完美的实现了多种业务整合和高效运营,一块网络处理器完美的实现了多个传统处理器的功能和性能,因此无需使用分布式架构就能提供多达数10Gbps的处理能力。并且随着工艺的更新,下一代QFP处理器将会使用更多的内核并占用更小的主板空间,并获得160Gbps的处理能力
绿色环保
由于CiscoASR1000系列多业务汇聚路由器在紧凑的机箱内集成了多种功能,同时通过对QuantumFlow处理器进行的优化测试,CiscoASR1000系列路由器功耗远小于同类产品。
平衡之美
传统网络处理器通常使用TCAM进行大规模的路由查询和会话查询以及ACL匹配,但TCAM通常成本高、功耗大和路由更新复杂。同时报文分类等处理也需要借助于TCAM,因此在一个多业务路由器平台上,通常需要对TCAM进行分区来实现不同的业务,这样也导致了很多性能瓶颈。
思科在开发ASR1000系列路由器时将CRS上使用的查表器件移植到了QuantumFlow处理器上,可以支持多达4,000,000条路由的高速查询,同时使用了专用的硬件Hash器件完成对防火墙,NAT等会话的高速查询,因此TCAM资源全部用于报文分类处理以及复杂的ACL匹配等。通过多组件的平衡处理,使得ASR1000在进行多种复杂业务叠加处理时维持了很高的处理能力。同时为了更好的服务于中国市场,思科公司在上海设立了专门的研发团队进行CiscoASR1000系列多业务汇聚路由器的新特性开发和维护。












