近来试着FTP搜索,遇到编码问题,研究了下。
Java内部的String为Unicode编码,每个字符占两个字节。
Java编解码方法如下:
- String str = "hi好啊me";
- byte[] gbkBytes=str.getBytes("GBK");//将String的Unicode编码转为GBK编码,输出到字节中
- String string=new String(gbkBytes,"GBK");//gbkBytes中的字节流以GBK方案解码成Unicode形式的Java字符串
1、表单数据的编码
现在的问题是,在网络中,不知道客户端发过来的字节流的编码方案(发送前浏览器会对数据编码!!!各个浏览器还不一样!!!)
解决方案如下:
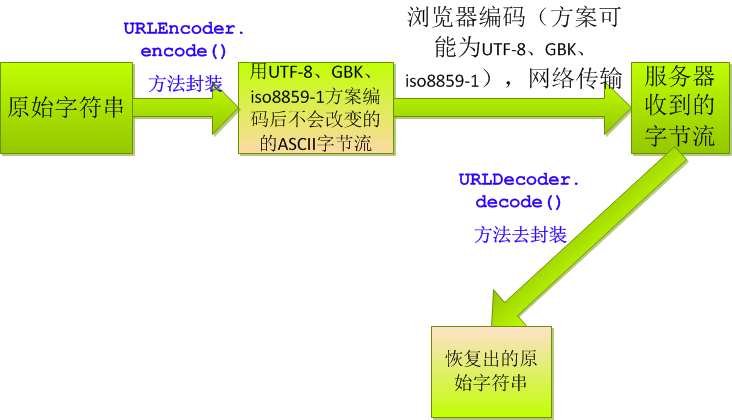
当然URLEncoder.encode(str, "utf-8")和URLDecoder.decode(strReceive,"utf-8")方法中的编码方案要一致。
2、网址的编码
但以上方法只适合表单数据的提交;对于URL则不行!!!原因是URLEncoder把'/'也编码了,浏览器发送时报错!!!那么,只要http://IP/子目录把http://IP/这部分原封不动(当然这部分不要有中文),之后的数据以'/'分割后分段编码即可。
代码如下:
- /**
- * 对{@link URLEncoder#encode(String, String)}的封装,但不编码'/'字符,对其他字符分段编码
- *
- * @param str
- * 要编码的URL
- * @param encoding
- * 编码格式
- * @return 字符串以字符'/'隔开,对每一段单独编码以encoding编码格式编码
- * @version: 2012_01_10
- * <p>
- * 注意:未考虑':',如直接对http://编解码,会产生错误!!!请在使用前将其分离出来,可以使用
- * {@link #encodeURLAfterHost(String, String)}方法解决此问题
- * <p>
- * 注意:对字符/一起编码,导致URL请求异常!!
- */
- public static String encodeURL(String str, String encoding) {
- final char splitter = '/';
- try {
- StringBuilder sb = new StringBuilder(2 * str.length());
- int start = 0;
- for (int i = 0; i < str.length(); i++) {
- if (str.charAt(i) == splitter) {
- sb.append(URLEncoder.encode(str.substring(start, i),
- encoding));
- sb.append(splitter);
- start = i + 1;
- }
- }
- if (start < str.length())
- sb.append(URLEncoder.encode(str.substring(start), encoding));
- return sb.toString();
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- return null;
- }
- /**
- * 对IP地址后的URL通过'/'分割后进行分段编码.
- * <p>
- * 对{@link URLEncoder#encode(String, String)}
- * 的封装,但不编码'/'字符,也不编码网站部分(如ftp://a.b.c.d/部分,检测方法为对三个'/'字符的检测,且要求前两个连续),
- * 对其他字符分段编码
- *
- * @param str
- * 要编码的URL
- * @param encoding
- * 编码格式
- * @return IP地址后字符串以字符'/'隔开,对每一段单独编码以encoding编码格式编码,其他部分不变
- * @version: 2012_01_10
- * <p>
- * 注意:对字符/一起编码,导致URL请求异常!!
- */
- public static String encodeURLAfterHost(String str, String encoding) {
- final char splitter = '/';
- int index = str.indexOf(splitter);//***个'/'的位置
- index++;//移到下一位置!!
- if (index < str.length() && str.charAt(index) == splitter) {//检测***个'/'之后是否还是'/',如ftp://
- index++;//从下一个开始
- index = str.indexOf(splitter, index);//第三个'/';如ftp://anonymous:tmp@g.cn:219.223.168.20/中的***一个'/'
- if (index > 0) {
- return str.substring(0, index + 1)
- + encodeURL(str.substring(index + 1), encoding);//如ftp://anonymous:tmp@g.cn:219.223.168.20/天空
- } else
- return str;//如ftp://anonymous:tmp@g.cn:219.223.168.20
- }
- return encodeURL(str, encoding);
- }
- /**
- * 对IP地址后的URL通过'/'分割后进行分段编码.
- * 此方法与{@link #decodeURLAfterHost(String, String)}配对使用
- * @param str
- * 要解码的URL
- * @param encoding
- * str的编码格式
- * @return IP地址后字符串以字符'/'隔开,对每一段单独解码以encoding编码格式解码,其他部分不变
- * @version: 2012_01_10
- *
- * <p>
- * 注意:对字符/一起解码,将导致URL请求异常!!
- */
- public static String decodeURLAfterHost(String str, String encoding) {
- final char splitter = '/';
- int index = str.indexOf(splitter);//***个'/'的位置
- index++;//移到下一位置!!
- if (index < str.length() && str.charAt(index) == splitter) {//检测***个'/'之后是否还是'/',如ftp://
- index++;//从下一个开始
- index = str.indexOf(splitter, index);//第三个'/';如ftp://anonymous:tmp@g.cn:219.223.168.20/中的***一个'/'
- if (index > 0) {
- return str.substring(0, index + 1)
- + decodeURL(str.substring(index + 1), encoding);//如ftp://anonymous:tmp@g.cn:219.223.168.20/天空
- } else
- return str;//如ftp://anonymous:tmp@g.cn:219.223.168.20
- }
- return decodeURL(str, encoding);
- }
- /**
- * 此方法与{@link #encodeURL(String, String)}配对使用
- * <p>
- * 对{@link URLDecoder#decode(String, String)}的封装,但不解码'/'字符,对其他字符分段解码
- *
- * @param str
- * 要解码的URL
- * @param encoding
- * str的编码格式
- * @return 字符串以字符'/'隔开,对每一段单独编码以encoding编码格式解码
- * @version: 2012_01_10
- *
- * <p>
- * 注意:对字符/一起编码,导致URL请求异常!!
- */
- public static String decodeURL(String str, String encoding) {
- final char splitter = '/';
- try {
- StringBuilder sb = new StringBuilder(str.length());
- int start = 0;
- for (int i = 0; i < str.length(); i++) {
- if (str.charAt(i) == splitter) {
- sb.append(URLDecoder.decode(str.substring(start, i),
- encoding));
- sb.append(splitter);
- start = i + 1;
- }
- }
- if (start < str.length())
- sb.append(URLDecoder.decode(str.substring(start), encoding));
- return sb.toString();
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- return null;
- }
3、乱码了还能恢复?
问题如下:
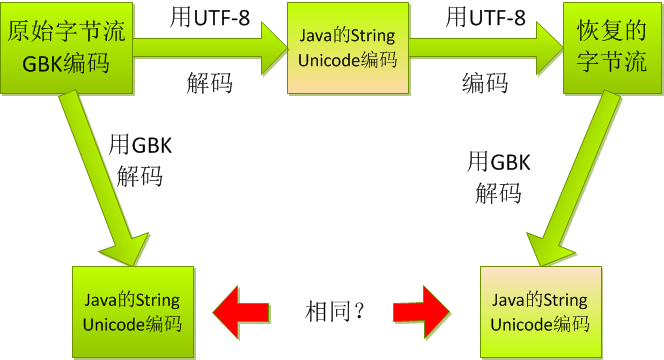
貌似图中的utf-8改成iso8859-1是可以的,utf-8在字符串中有中文时不行(但英文部分仍可正确解析)!!!毕竟GBK的字节流对于utf-8可能是无效的,碰到无效的字符怎么解析,是否可逆那可不好说啊。
测试代码如下:
- package tests;
- import java.io.UnsupportedEncodingException;
- import java.net.URLEncoder;
- /**
- * @author LC
- * @version: 2012_01_12
- */
- public class TestEncoding {
- static String utf8 = "utf-8";
- static String iso = "iso-8859-1";
- static String gbk = "GBK";
- public static void main(String[] args) throws UnsupportedEncodingException {
- String str = "hi好啊me";
- // System.out.println("?的十六进制为:3F");
- // System.err
- // .println("出现中文时,如果编码方案不支持中文,每个字符都会被替换为?的对应编码!(如在iso-8859-1中)");
- System.out.println("原始字符串:\t\t\t\t\t\t" + str);
- String utf8_encoded = URLEncoder.encode(str, "utf-8");
- System.out.println("用URLEncoder.encode()方法,并用UTF-8编码后:\t\t" + utf8_encoded);
- String gbk_encoded = URLEncoder.encode(str, "GBK");
- System.out.println("用URLEncoder.encode()方法,并用GBK编码后:\t\t" + gbk_encoded);
- testEncoding(str, utf8, gbk);
- testEncoding(str, gbk, utf8);
- testEncoding(str, gbk, iso);
- printBytesInDifferentEncoding(str);
- printBytesInDifferentEncoding(utf8_encoded);
- printBytesInDifferentEncoding(gbk_encoded);
- }
- /**
- * 测试用错误的编码方案解码后再编码,是否对原始数据有影响
- *
- * @param str
- * 输入字符串,Java的String类型即可
- * @param encodingTrue
- * 编码方案1,用于模拟原始数据的编码
- * @param encondingMidian
- * 编码方案2,用于模拟中间的编码方案
- * @throws UnsupportedEncodingException
- */
- public static void testEncoding(String str, String encodingTrue,
- String encondingMidian) throws UnsupportedEncodingException {
- System.out.println();
- System.out
- .printf("%s编码的字节数据->用%s解码并转为Unicode编码的JavaString->用%s解码变为字节流->读入Java(用%s解码)后变为Java的String\n",
- encodingTrue, encondingMidian, encondingMidian,
- encodingTrue);
- System.out.println("原始字符串:\t\t" + str);
- byte[] trueEncodingBytes = str.getBytes(encodingTrue);
- System.out.println("原始字节流:\t\t" + bytesToHexString(trueEncodingBytes)
- + "\t\t//即用" + encodingTrue + "编码后的字节流");
- String encodeUseMedianEncoding = new String(trueEncodingBytes,
- encondingMidian);
- System.out.println("中间字符串:\t\t" + encodeUseMedianEncoding + "\t\t//即用"
- + encondingMidian + "解码原始字节流后的字符串");
- byte[] midianBytes = encodeUseMedianEncoding.getBytes("Unicode");
- System.out.println("中间字节流:\t\t" + bytesToHexString(midianBytes)
- + "\t\t//即中间字符串对应的Unicode字节流(和Java内存数据一致)");
- byte[] redecodedBytes = encodeUseMedianEncoding
- .getBytes(encondingMidian);
- System.out.println("解码字节流:\t\t" + bytesToHexString(redecodedBytes)
- + "\t\t//即用" + encodingTrue + "解码中间字符串(流)后的字符串");
- String restored = new String(redecodedBytes, encodingTrue);
- System.out.println("解码字符串:\t\t" + restored + "\t\t和原始数据相同? "
- + restored.endsWith(str));
- }
- /**
- * 将字符串分别编码为GBK、UTF-8、iso-8859-1的字节流并输出
- *
- * @param str
- * @throws UnsupportedEncodingException
- */
- public static void printBytesInDifferentEncoding(String str)
- throws UnsupportedEncodingException {
- System.out.println("");
- System.out.println("原始String:\t\t" + str + "\t\t长度为:" + str.length());
- String unicodeBytes = bytesToHexString(str.getBytes("unicode"));
- System.out.println("Unicode bytes:\t\t" + unicodeBytes);
- String gbkBytes = bytesToHexString(str.getBytes("GBK"));
- System.out.println("GBK bytes:\t\t" + gbkBytes);
- String utf8Bytes = bytesToHexString(str.getBytes("utf-8"));
- System.out.println("UTF-8 bytes:\t\t" + utf8Bytes);
- String iso8859Bytes = bytesToHexString(str.getBytes("iso-8859-1"));
- System.out.println("iso8859-1 bytes:\t" + iso8859Bytes + "\t\t长度为:"
- + iso8859Bytes.length() / 3);
- System.out.println("可见Unicode在之前加了两个字节FE FF,之后则每个字符两字节");
- }
- /**
- * 将该数组转的每个byte转为两位的16进制字符,中间用空格隔开
- *
- * @param bytes
- * 要转换的byte序列
- * @return 转换后的字符串
- */
- public static final String bytesToHexString(byte[] bytes) {
- StringBuilder sb = new StringBuilder(bytes.length * 2);
- for (int i = 0; i < bytes.length; i++) {
- String hex = Integer.toHexString(bytes[i] & 0xff);// &0xff是byte小于0时会高位补1,要改回0
- if (hex.length() == 1)
- sb.append('0');
- sb.append(hex);
- sb.append(" ");
- }
- return sb.toString().toUpperCase();
- }
- }
原文链接:http://cherishlc.iteye.com/blog/1343502
【编辑推荐】