可以从不同的的角度去划分垃圾回收算法:
按照基本回收策略分
引用计数(Reference Counting):
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
标记-清除(Mark-Sweep):
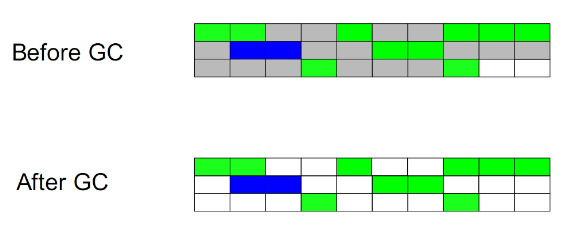
此算法执行分两阶段。***阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
复制(Copying):
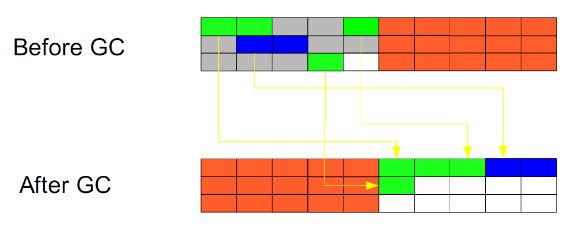
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
标记-整理(Mark-Compact):
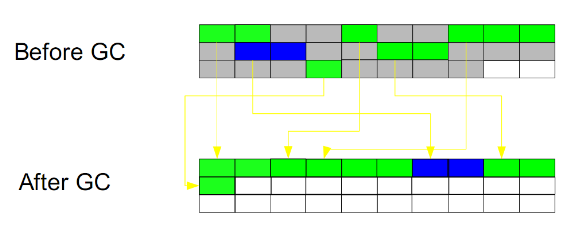
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,***阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
按分区对待的方式分
增量收集(Incremental Collecting):实时垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
分代收集(Generational Collecting):基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
按系统线程分
串行收集:串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
并行收集:并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
并发收集:相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。
原文链接:http://pengjiaheng.iteye.com/blog/520228
【编辑推荐】