Fourinone同时提供完整的分布式缓存支持,包括中小型缓存以及大型集群缓存,他使用不同于map/reduce的全新设计模式解决问题,模仿现实中生产加工链式加并行处理的“包工头/农民工/手工仓库/职业所”方式设计分布式计算,他还可以当做简单的mq使用。Fourinone整体短小精悍,就一个jar包没有任何依赖,很方便嵌入式开发使用。本文将详细介绍Fourinone的使用背景、原理和功能等
淘宝Fourinone(中文名字“四不像”)是一个四合一分布式计算框架,在写这个框架之前,我对分布式计算进行了长时间的思考,也看了老外写的其他开源框架,当我们把复杂的hadoop当作一门学科学习时,似乎忘记了我们想解决问题的初衷:我们仅仅是想写个程序把几台甚至更多的机器一起用起来计算,把更多的cpu和内存利用上,来解决我们数量大和计算复杂的问题,当然这个过程中要考虑到分布式的协同和故障处理。如果仅仅是为了实现这个简单的初衷,为什么一切会那么复杂,我觉的自己可以写一个更简单的东西,它不需要过度设计,只需要看上去更酷一点,更小巧一点,功能更强一点。于是我将自己对分布式的理解融入到这个框架中,考虑到底层实现技术的相似性,我将Hadoop,Zookeeper,MQ,分布式缓存四大主要的分布式计算功能合为一个框架内,对复杂的分布式计算应用进行了大量简化和归纳。
首先,对分布式协同方面,它实现了Zookeeper所有的功能,并且做了很多改进,包括简化Zookeeper的树型结构,用domain/node两层结构取代,简化Watch回调多线程等待编程模型,用更直观的容易保证业务逻辑完整性的内容变化事件以及状态轮循取代,Zookeeper只能存储信息不大于1M的内容,FourInOne超过1M的内容会以内存隐射文件存储,增强了它的存储功能,简化了Zookeeper的ACL权限功能,用更为程序员熟悉rw风格取代,简化了Zookeeper的临时节点和序列节点等类型,取代为在创建节点时是否指定保持心跳,心跳断掉时节点会自动删除。FourInOne是高可用的,没有单点问题,可以有任意多个复本,它的复制不是定时而是基于内容变更复制,有更高的性能,FourInOne实现了领导者选举算法(但不是Paxos),在领导者服务器宕机情况下,会自动不延时的将请求切换到备份服务器上,选举出新的领导者进行服务,这个过程中,心跳节点仍然能保持健壮的稳定性,迅速跟新的领导者保持心跳连接。基于FourInOne可以轻松实现分布式配置信息,集群管理,故障节点检测,分布式锁,以及淘宝configserver等等协同功能。
其次, FourInOne可以提供完整的分布式缓存功能。如果对一个中小型的互联网或者企业应用,仅仅利用domain/node进行k/v的存储即可,因为domain/node都是内存操作而且读写锁分离,同时拥有复制备份,完全满足缓存的高性能与可靠性。对于大型互联网应用,高峰访问量上百万的并发读写吞吐量,会超出单台服务器的承受力,FourInOne提供了fa?ade的解决方案去解决大集群的分布式缓存,利用硬件负载均衡路由到一组fa?ade服务器上,fa?ade可以自动为缓存内容生成key,并根据key准确找到散落在背后的缓存集群的具体哪台服务器,当缓存服务器的容量到达限制时,可以自由扩容,不需要成倍扩容,因为fa?ade的算法会登记服务器扩容时间版本,并将key智能的跟这个时间匹配,这样在扩容后还能准确找到之前分配到的服务器。另外,基于FourInOne可以轻松实现web应用的session功能,只需要将生成的key写入客户端cookie即可。
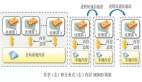
FourInOne对于分布式大数据量并行计算的解决方案不同于复杂的hadoop,它不像hadoop的中间计算结果依赖于hdfs,它使用不同于map/reduce的全新设计模式解决问题。FourInOne有“包工头”,“农民工”,“手工仓库”的几个核心概念。“农民工”为一个计算节点,可以部署在多个机器,它由开发者自由实现,计算时,“农民工”到“手工仓库”获取输入资源,再将计算结果放回“手工仓库”返回给“包工头”。“包工头”负责承包一个复杂项目的一部分,可以理解为一个分配任务和调度程序,它由开发者自己实现,开发者可以自由控制调度过程,比如按照“农民工”的数量将源数据切分成多少份,然后远程分配给“农民工”节点进行计算处理,它处理完的中间结果数据不限制保存在hdfs里,而可以自由控制保存在分布式缓存、数据库、分布式文件里。如果需要结果数据的合并,可以新建立一个“包工头”的任务分配进行完成。多个“包工头”之间进行责任链式处理。总的来说,是将大数据的复杂分布式计算,设计为一个链式的多“包工头”环节去处理,每个环节包括利用多台“农民工”机器进行并行计算,无论是拆分计算任务还是合并结果,都可以设计为一个单独的“包工头”环节。这样做的好处是,开发者有更大能力去深入控制并行计算的过程,去保持使用并行计算实现业务逻辑的完整性,而且对各种不同类型的并行计算场景也能灵活处理,不会因为某些特殊场景被map/reduce的框架限制住思维,并且链式的每个环节也方便进行监控过程。
FourInOne也可以当成简单的mq来使用,将domain视为mq队列,每个node为一个队列消息,监控domain的变化事件来获取队列消息。也可以将domain视为订阅主题,将每个订阅者注册到domain的node上,发布者将消息逐一更新每个node,订阅者监控每个属于自己的node的变化事件获取订阅消息,收到后删除内容等待下一个消息。但是FourInOne不实现JMS的规范,不提供JMS的消息确认和消息过滤等特殊功能,不过开发者可以基于FourInOne自己去扩充这些功能,包括mq集群,利用一个独立的domain/node建立队列或者主题的key隐射,再仿照上面分布式缓存的智能根据key定位服务器的做法实现集群管理。
FourInOne整体代码不到100k,跟Hadoop, Zookeeper, Memcache, ActiveMq等开源产品代码上没有任何相似性,不需要任何依赖,引用一个jar包就可以嵌入式使用,良好支持window环境,可以在一台机器上模拟分布式环境,更方便开发。
开发包里自带了一系列傻瓜上手demo,包括分布式计算、统一配置管理、集群管理、分布式锁、分布式缓存、MQ等方面帮助掌握fourinone的全部功能
下载地址:
http://www.skycn.com/soft/68321.html。
博客地址(内有跟hadoop的对比和基准测试):
http://3503265.blog.51cto.com/
【编辑推荐】