在这一年,我们看到众多厂商工作重点主要是围绕整合Hadoop或NoSQL数据处理引擎以及改善基本的数据存储。Hadoop最成功的一点就是其采用了MapReduce。MapReduce是一种处理超大型数据集并生成相关执行的编程模型,MapReduce的核心思想主要是借鉴了函数是编程语言以及矢量变成语言里的特性。
现今包括Microsoft、IBM、Oracle、Cloudera、MapR等众多厂商相继推出了与自身相结合的Hadoop产品。例如Oracle NoSQL Database,其是Oracle在全球大会上发布的Big Data Appliance的其中一个组件,Big Data Appliance还包括了Hadoop、Oracle数据库Hadoop适配器、Oracle数据库Hadoop装载器及R语言的系统。
同时在本月微软也公布了针对Windows Azure的基于Apache Hadoop的预览发行版,据微软透露其可使Hadoop应用程序在几小时即可部署完成,而以往这需要数天。而这种趋势在未来一年还会持续下去。正如我们所看到的,Hadoop技术在众多领域正广泛得到部署。
但Hadoop也面临一些相当棘手的状况,众所周知,Hadoop的批量化处理是人们喜爱它的地方,但这在某些领域仍显不足,尤其是在例如移动、Web客户端或金融、网页广告等需要实时计算的领域。这些领域产生的数据量极大,没有足够的存储空间来存储每个业务收到的数据。而流计算则可以实时对数据进行分析,并决定是否抛弃无用的数据,而这无需经过Map/Reduce的环节。
从实时计算的角度看,Yahoo!的分布式流计算平台S4则要比Hadoop更具优势。MapReduce系统主要解决的是对静态数据的批量处理,即当前的MapReduce系统实现启动计算时,一般数据已经到位(比如保存到了分布式文件系统上)。
而流式计算系统在启动时,一般数据并没有完全到位,而是源源不断地流入,并且不像批处理系统重视的是总数据处理的吞吐,而是对数据处理的latency,即希望进入的数据越快处理越好。
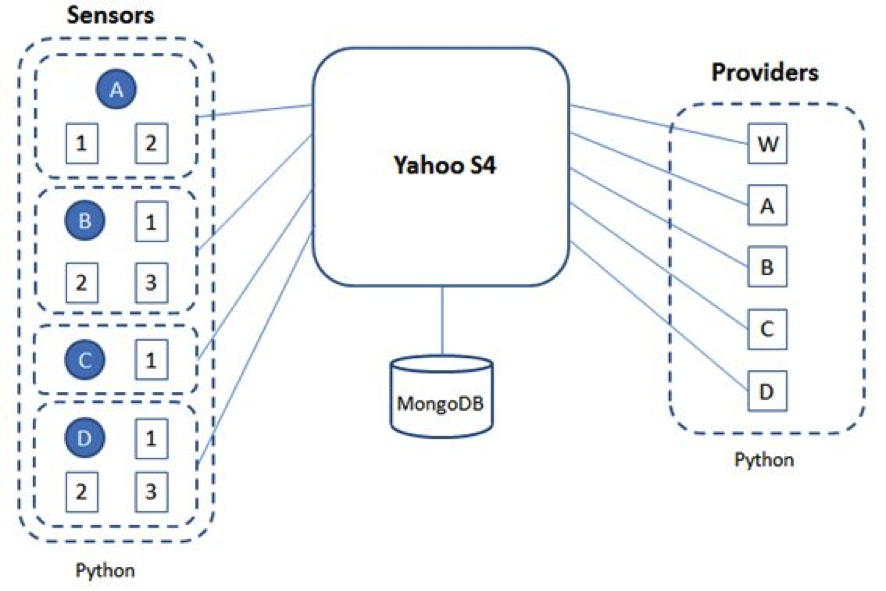
Yahoo!S4的设计大量借鉴了IBM的Stream Processing Core(SPC)中间件的设计。只是SPC采用的是Subscription Model,而S4结合了MapReduce和Actors Model。而简单的编程接口;高可用+高可扩展;尽力避免Disk IO,尽量使用Local Memory,以便减少处理latency;使用去中心化和对称架构,所有的节点的责任相同,方便部署和维护;功能可插拔,使得平台通用化的同时,做到可以定制化以及设计要科学、易用和灵活是Yahoo!S4的设计目标。
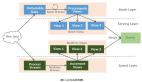
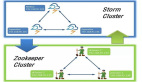
而Storm作为Twitter公司实时数据处理平台也受到广泛关注(Twitter也在9月19日圣路易斯市举行的Strange Loop会议上公布其源代码)。Storm的发展势头相当强劲,Twitter开发的相应工具已使其功能变得更加强大。
Storm的作用主要在以下三个领域:信息流处理(Stream processing)Storm可用来实时处理新数据和更新数据库,兼具容错性和可扩展性;连续计算(Continuous computation)Storm可进行连续查询并把结果即时反馈给客户端。比如把Twitter上的热门话题发送到浏览器中;分布式远程程序调用(Distributed RPC)Storm可用来并行处理密集查询。Storm的拓扑结构是一个等待调用信息的分布函数,当它收到一条调用信息后,会对查询进行计算,并返回查询结果。举个例子Distributed RPC可以做并行搜索或者处理大集合的数据。
另一个知名的分布式流式系统是Brandeis University、Brown University和MIT合作开发的Borealis,Borealis由之前的流式系统Aurora、Medusa演化而来。目前Borealis系统已经停止维护,***的Release版本停止在2008年。
Borealis具有丰富的论文、完整的用户/开发者文档,系由是C++实现并运行于x86-based Linux平台。同时系统是开源的,且使用了较多的第三方开源组件,包括用于查询语言翻译的ANTLR、C++的网络编程框架库NMSTL等。
Borealis系统的流式模型和其他流式系统基本一致:接受多元的数据流和输出,为了容错,采用确定性计算,对于容错性要求高的系统,会对输入流使用算子进行定序。
随着大量实时计算需求的增加,分布式流式计算将会成为分布式计算的下一个主要研究重点,将会成为类似Hadoop这类MapReduce框架的有力补充。