任何计算机系统都有出现故障的时候,可能发生在测试阶段,也可能发生在系统刚刚上线,还可能发生在已经稳定运行很多年的系统上,又可能发生在系统一个小小的升级之后。而这些系统出现故障所带来的负面影响则可大可小,小到一个终端的软件无法使用,大到整个系统瘫痪,所有业务不能办理。由此便有了IT故障处理分级的运作形式,将问题或故障做到先后有序,将IT运维故障划分为普通、急、紧急……依靠这套省力的约定建立故障处理流程,是解放IT支持部门最有效的法则。
当计算机故障升级到“核灾难”
佩特罗夫是原苏联一位年轻军人、计算机工程师。1983年9月26日晚上,他正在莫斯科附近的某个导弹中心值班,他回忆说:“忽然,我面前的计算机屏幕变成了刺眼的红色,刺耳的警报声也随之响起,声音大得简直能把死人都从坟墓里吓醒。这是计算机预警系统发出美国向苏联实施核进攻的警报,美国人向我们发射核武器了!”一般人认为,计算机按事先编制的程序工作,它提供的信息应是绝对可靠的,计算机不会玩花招,但这次出现的情况却不是这样。警报还在不断地响,佩特罗夫没有被吓呆,而是在积极思考。根据他掌握的情况来判断,他认为,美国没有理由在当时对苏联发动核攻击,唯一的可能是计算机出错。导弹中心接到佩特罗夫的报告后,急如星火地派人对计算机进行紧急检修。结果证明,错误警报的发出完全是由计算机的故障造成的,计算机在这起故障中,充当了挑起核战争的罪魁祸首。
上面这个真实存在的计算机故障被列为IT界十大故障之首。虽然这起故障最终没有引发全世界的“灾难”,但是不是今后的数十年之后,就会完全避免此类事件发生呢?这引起了我们深深地思考。
作为IT运维产品和服务提供商的北塔软件认为:“无论从技术角度出发,还是就业务角度而言,我们都需要对经常发生的IT故障进行各种考虑和权衡。在看起来似乎无法立即解决所有故障的情况下进行正确的权衡,则是IT运维人员成功的关键。这意味着要首先确定有哪些系统出现问题,会波及到核心业务的停滞范围,以及理解并确定如何在出现故障的时候按照紧急度权衡,从而避免影响面最大的灾难事件发生。”
北塔软件的技术专家以一家正在实施BTIM IT综合管理系统的银行IT系统为例,为我们说明了故障和灾难的区别。例如,对于一般的电脑系统故障,信科部或业务部门通过通常的措施(如激线、重组、重起、切换、脱机交易、冲证等)在短时间内能够恢复对外的服务,对银行业务和客户利益没有造成重大影响,此类事件称之为故障。如果信息中心发生严重故障,导致管辖内大部分或全部的业务无法进行,且在一天内仍无法恢复正常对外服务,此类故障则要称之为“灾难”了。
故障优先级的两大核心要素
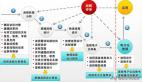
确定优先级需要综合考虑突发事件对业务的影响情况、恢复服务对业务的紧迫性、突发事件的大小、范围和复杂程度以及当前可供突发事件处理的资源等等。在定义优先级之前,我们必须清楚它与两个最重要的因素有关,即:影响度、紧急度。其中,影响度是衡量故障影响业务大小程度的指标,通常相当于故障影响服务质量的程度,它一般是根据受影响的人或系统的数量来确定的。而紧急度是评价故障和问题危机程度的指标,是根据客户的业务需求和故障或问题的影响而制定的。因此,如何设定优先级,这需要根据影响程度和紧急程度的评估和数据收集工作,之后才是制定故障的处理顺序。
一般来说,当IT出现故障时,首先要记录与故障有关的客户和用户的信息,如姓名、工作地点和联系电话等等,先对故障进行“初步归类”,然后再进行初步处理。 在对故障进行归类后,如果没有成功地将故障与问题或先前知名错误(知识库)进行匹配,下一步就是确定故障的优先级了,以确保对应的负责人给予故障必要的注意。当IT运维部门必须同时处理数个故障的时候,由于受到了时间、资源和人力等限制而无法立即解决全部问题时,此时就要排定处理的先后次序,即确定每个故障的优先级。但当出现故障后,没有用户会说他的问题可以放到以后解决。相反,他们总是认为自己的问题才是最需要优先解决的。因此,企业最好的IT运维方式,是通过服务台机制、或是历史的积累,以及业务部门负责人的认定之后,才能根据统计一些量化的指标来决定优先级。
当然,不同的企业所定义的故障优先级是不同的。例如:制造企业的ERP系统的故障的紧迫性和影响度就非常之高,有些故障或问题会直接影响业务运作,或影响公司的对外服务水平,或有法律上的风险。因为这会影响对客户承诺的送货时间,价格数据有误等等,这些故障或问题需要IT支持部门马上做出支持,以便最大限度地降低对业务运作的影响。
定义告警事件优先级 有效地处理故障
企业的 IT 管理部门就是为企业提供 IT 后勤服务,而IT运维软件又是为企业的 IT 管理部门提供后勤服务的,而这恰恰是很多未能推进 IT 运维监控工作的企业最容易忽视的地方。这些企业依赖一些经验丰富的“排错专家”,他们的技能是能够对在复杂环境中可能出现的性能和吞吐问题进行事先估计,并进行恰当的决策来避免这些问题。
但并不是每个人都是“佩特罗夫”,在我们看来,成功的IT运维部门所具有的最有价值的技能是将IT系统各个部分连接起来的能力。但是,由于传统的,手工作坊一样的管理效率不但低下,并且管理人员由于无法掌握全网的网络设备运行情况,当网络发生故障时也无法定位根源(即使我们从“影响度+紧急度==优先级”的公式计算中得到了结果)。同时,我们还应该清楚,不同的优先级,所处理得流程也是不一样的。但是由于一些工程师的维护职责不是很清楚,每个人都大概知道自己该做什么,但是某个具体事情到底该谁负责,却没有明细流程。林林总总,这些都可能导致看似非致命的故障,最终则是全网范围的网络中断,或者服务平台灾难性的事件发生。
而一套优秀的IT运维系统恰好可为优先级的管理奠定了预警和管理的技术。为了能够将IT告警事件区分出优先级,我们唯一的办法是将分散或看起来不相关的组件(问题)联系起来,以形成一个完整的系统。因为,只有从完整的监控系统中才能派生出“有意义的(可执行的)”的故障恢复流程。以北塔软件BTIM为例,在操作界面中的对于图标使用 “红、棕、黄、绿、蓝”不同的颜色,这代表5个告警等级,此告警等级可以代表不同的运维等级,它们是:紧急、高级、中级、低级、提示级。根据优先级的不同,对应的处理人员不同,处理流程也不同,响应的时间也是不同的。例如:SLA优先级较高的系统出现问题,IT运维部门需要在1小时之内解决问题,或者启用备用系统。而相对级别较低的服务便可根据SLA协议约定的范围内,如4小时、8小时内完成修复。
在北塔BTIM综合运维系统中,可以把IT运维“那些事”(包括人员、资源、突发故障)分成不同级别和不同运维操作,以便有效的配置运维人力资源。正是因为监控系统与SLA协议的匹配,通过管理上对于不同故障等级采取不同的监管策略,才能实现了人力、财力成本投入不增加的情况下,起到高效管理的收益。
流程优化与人力优化是同时进行的,实现IT故障分级处理也是一次对IT运维人力资源配置的优化过程。例如,明确故障分级处理流程,便同时界定了运维人员对于故障的响应时间、职责、权限、义务和绩效考核标准等等。事实上许多企业的实践和北塔软件的成功实施案例也证明,这样可以减少IT运维操作的随意性和混乱性,并能大大提高运维中的人力资源效率。使服务的每个环节均标准、可控,从而使服务质量能够得到保证,避免了服务质量过分依赖技术工程师的个人能力和责任心,而使服务质量不可控和随机性。